A professional community focused on sharing financial information. If you like it, please click the business card below to follow.
A strange yet common misconception has spread in the market: as soon as a company announces it is developing ASICs, many people immediately believe it, as if ASICs are a technology that anyone can master, and that simply placing an order for tape-out can immediately challenge NVIDIA. The public has even formed a counterintuitive perception that GPUs are difficult to develop, while ASICs seem much simpler. The truth is, developing an ASIC chip is not hard; the challenge lies in creating one that can be genuinely adopted for large-scale, long-term, production-level applications. This is the truly hellish part of the difficulty.
Today, the process of developing ASICs has become quite industrialized: purchasing IP, outsourcing to foundries for tape-out, and conducting validation are tasks that startups and even university teams can accomplish. However, the real challenge of ASICs has never been about whether they can be produced, but whether they can be used at scale in real business scenarios. The vast majority of past failed AI ASIC projects did not fail due to poor hardware; rather, they succeeded in tape-out, had impressive demos, and lively launch events, but when faced with real workloads, they collapsed: performance did not meet promises, power consumption exceeded limits, heat was uncontrolled, yield was unstable, and costs were uncontrollable. More critically, the software ecosystem could not keep up, models could not be migrated, and businesses could not support them, ultimately relegating them to laboratory toys.
The common root cause of ASIC project failures in the industry is actually the software ecosystem. Computing chips are not just ICs; they are a complete system engineering project: compilers, runtime, kernel libraries, framework adaptations, debugging toolchains, distributed training components, scheduling systems, operational systems, performance analysis tools… missing any one of these can prevent the chip from being truly deployed. Names like Graphcore, Nervana, Tenstorrent, Cerebras, and Groq are classic cases of “hardware done well, but the ecosystem cannot keep up,” costing countless teams their investments.
Some historically failed ASIC projects
|
Company / Project |
Status Overview |
Time Frame |
Technical Route / Positioning |
|---|---|---|---|
|
Intel Nervana NNP |
Project canceled |
2016–2020 |
Data center training / inference dedicated NNP |
|
Graphcore IPU |
Business significantly contracted, uncertain prospects |
2016–2024 |
IPU parallel computing architecture |
|
Tenstorrent |
Struggling to survive, making slow progress |
2016–present |
RISC-V + self-developed tensor core, primarily open-source |
|
Cerebras WSE |
Niche market |
2017–present |
Full wafer super-large chip WSE |
|
Groq TSP |
In transition / unclear path |
2016–present |
TSP pipeline architecture, focusing on ultra-low latency |
|
Wave Computing |
Bankrupt and liquidated |
2010–2020 |
Dataflow architecture + MIPS |
|
Mythic Analog AI |
On the brink of bankruptcy, barely surviving after downsizing |
2012–2022 (then small-scale restart) |
Analog in-memory computing (Analog Matrix) |
|
Meta MTIA v1 |
Internal first-generation tape-out canceled |
2021–2023 |
Self-developed inference ASIC (MTIA version 1) |
|
AWS Trainium v1 |
Performance below expectations |
2020–2023 |
Training chip, paired with Neuron SDK |
|
IBM TrueNorth |
Remained at the research project level |
2014–present |
Neuromorphic / spiking neural network chip |
|
Untether AI |
Company bankrupt, most teams acquired |
2018–2024 |
Near-storage computing, RISC-V multi-core |
|
Esperanto Technologies |
Significant layoffs, preparing to sell IP |
2014–2024 |
Large-scale RISC-V small core array |
This also raises a more realistic question: what would motivate customers to switch from GPUs to ASICs? To persuade a company to abandon a mature ecosystem and take the risk of migration, you must provide a “crushing advantage” in some dimension, such as being faster at the same cost, or significantly reducing power consumption/latency. Otherwise, customers have no incentive to migrate code, retrain models, or reconfigure operations. If you cannot achieve an extreme advantage, then ASICs have no value and may even become a business burden.
Many people today think ASICs are easy, but this is simply because GPUs are too powerful, and ASICs are misunderstood as cheap, customizable, and low-threshold products under the shadow of information asymmetry. The reality is that in those past failed projects, each team’s technical strength was greater than that of most companies currently telling stories in the market. It is precisely because the difficulty of ASICs is severely underestimated that the market continues to see anyone daring to claim they will develop ASICs and replace GPUs.
The next time you hear a company claiming it will develop AI ASICs, the real question to ask is not whether it can tape out, but how it plans to solve the software ecosystem? In what dimension can it provide crushing performance over GPUs? And who is willing to bear the risk of its first large-scale deployment? The vast majority of companies cannot answer these three questions, so they are likely just the next story-telling ASIC project in the capital market, rather than the next NVIDIA.
If you understand the above, you can also grasp why I have always emphasized Google.
Data + Model + TPU + Ecosystem + Talent = Google. The creator of the Transformer, the pioneer of ASIC computing. Google is quietly building its own AI empire with a full-stack technology and resource layout, and its dominance in future AI competition is already looming on the horizon.
Dream Four Dimensions, WeChat Official Account: The Dream of the Fourth Dimension GPT-5 underperforms? Musk disbands the Dojo supercomputer team? The Federal Reserve suddenly wants to cut interest rates three times this year?
It can now be clearly stated that in this AI race, the Google dynasty is beginning to emerge. OpenAI, due to its inherent lack of hardware systems, will inevitably have to collaborate with the powerful NVIDIA for mutual benefit. In contrast, Google has already formed a complete closed loop across chips (TPU), large models (Gemini), and other fronts. For Google, there is no need for anxiety or to “roll” for speed; steady progress is enough to leave competitors in the dust.
Next, let us await the official release of Gemini 3.0.
Finally, let’s take a look at the current price of DRAM storage.
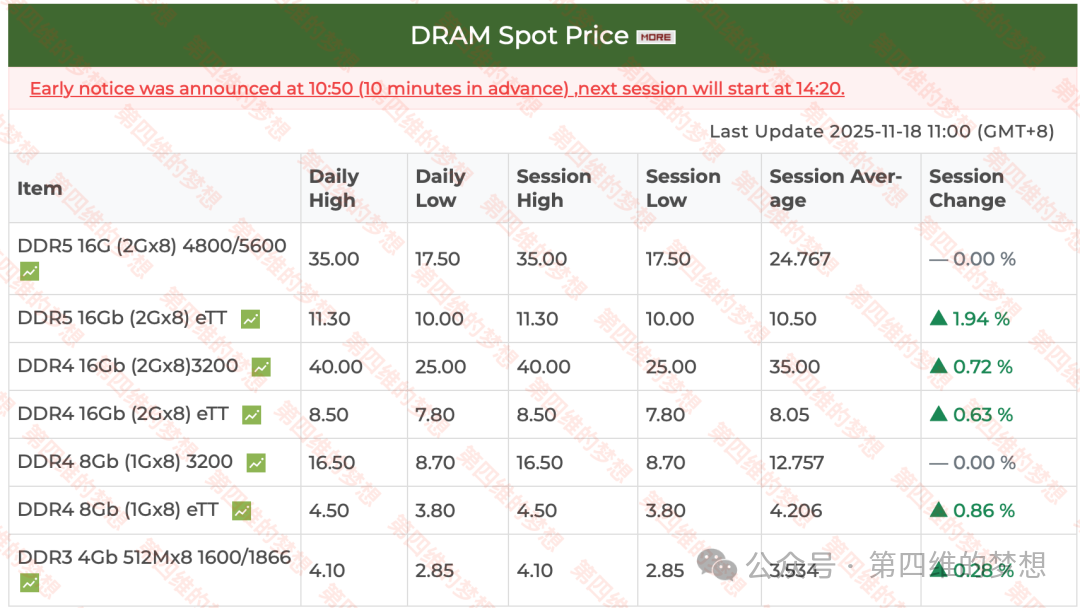
“Next week is a key week for data, as well as a key week for sentiment!“
“What else is worth watching in AI computing power?“
“When will you return? Waiting for new highs must have its time“
“NVIDIA GPU and various ASIC shipment forecasts“
“Berkshire Hathaway, led by Buffett, strongly buys Google!“
If you like this public account, you can click below to follow; it updates almost daily, and the public account is currently pushing in random order. Just adding a follow may not receive timely updates; friends who want to receive them promptly can star the public account!
A professional community focused on sharing financial information. If you like it, please click the business card below to follow.
Disclaimer: The materials in this article are compiled from company announcements, news, publicly available research reports, and social media networks, and do not constitute investment advice regarding the professionals and individual stocks mentioned. The market has risks, and investment should be cautious. If there are any infringements or violations of disclosure rules in the text and images, please contact us to delete them.