The author states: Among various effective LLM fine-tuning methods, LoRA remains his preferred choice.
LoRA (Low-Rank Adaptation) is a popular technique for fine-tuning LLMs (Large Language Models), initially proposed by researchers from Microsoft in the paper “LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS”. Unlike other techniques, LoRA does not adjust all parameters of the neural network but focuses on updating a small number of low-rank matrices, significantly reducing the computational cost required to train the model.
Due to the fine-tuning quality of LoRA being comparable to full model fine-tuning, many refer to this method as a fine-tuning magic tool. Since its release, many have been curious about this technology and want to write code from scratch to better understand the research. Previously, they struggled with a lack of suitable documentation; now, the tutorial has arrived.
The author of this tutorial is renowned machine learning and AI researcher Sebastian Raschka, who states that among various effective LLM fine-tuning methods, LoRA remains his preferred choice. To this end, Sebastian has specifically written a blog titled “Code LoRA From Scratch”, building LoRA from the ground up, which he considers a great learning method.
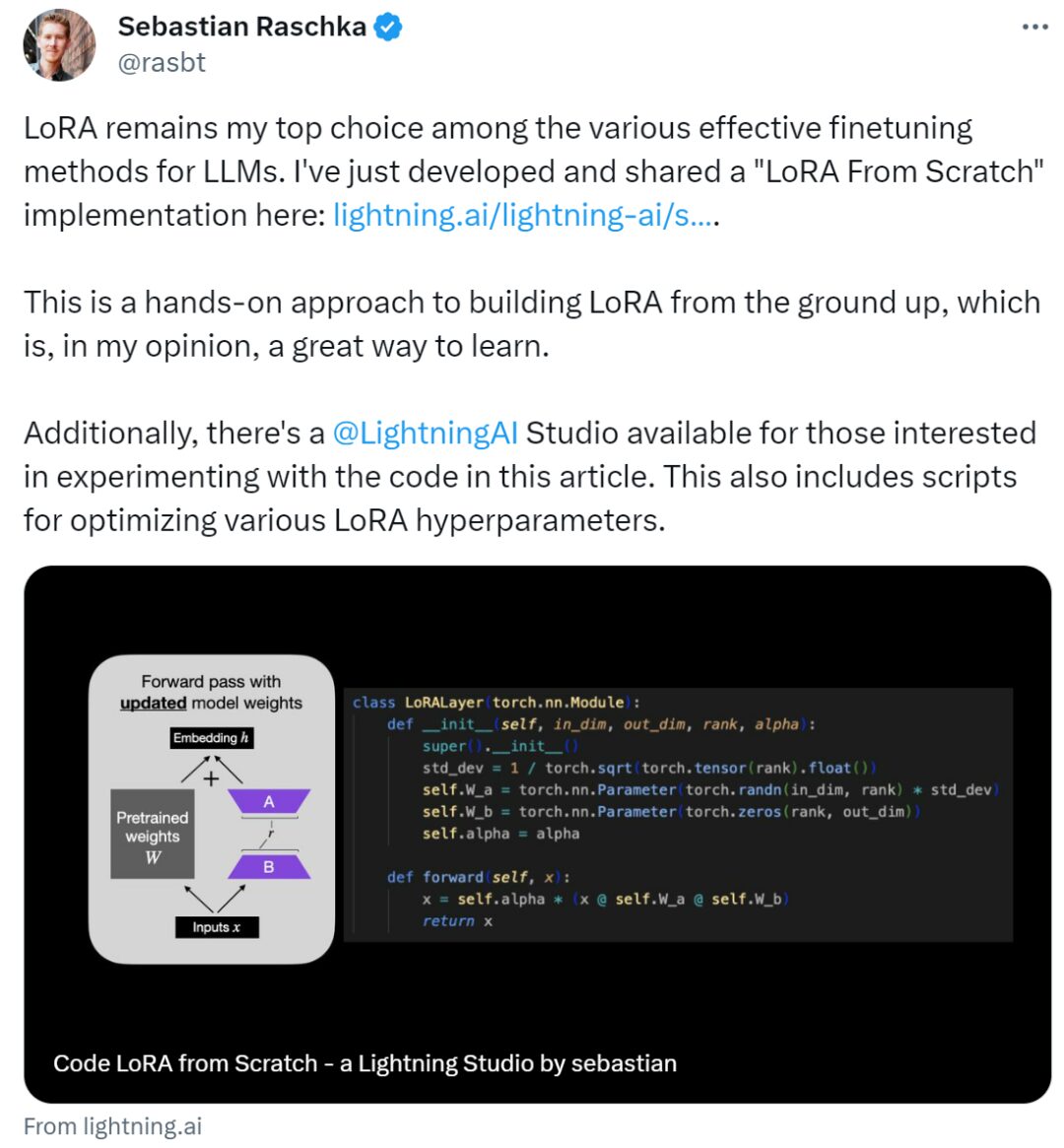
In simple terms, this article introduces Low-Rank Adaptation (LoRA) by writing code from scratch. In the experiment, Sebastian fine-tuned the DistilBERT model for a classification task.
The comparison results between LoRA and traditional fine-tuning methods show that using LoRA achieved a test accuracy of 92.39%, which demonstrates better performance compared to fine-tuning only the last few layers (86.22% test accuracy).
How did Sebastian achieve this? Let’s continue reading.
Writing LoRA From Scratch
Expressing a LoRA layer in code looks like this:
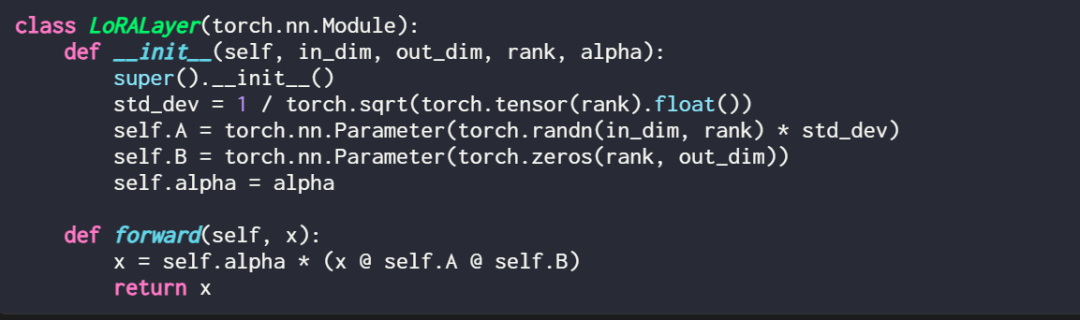
Here, in_dim is the input dimension of the layer to be modified by LoRA, and the corresponding out_dim is the output dimension of the layer. The code also adds a hyperparameter, the scaling factor alpha, where a higher alpha value means a greater adjustment to the model’s behavior, and a lower value means the opposite. Additionally, this article initializes matrix A with smaller values from a random distribution and initializes matrix B with zeros.
It is worth mentioning that LoRA typically functions in the linear (feed-forward) layers of neural networks. For instance, for a simple PyTorch model or a module with two linear layers (e.g., this may be the feed-forward module of a Transformer block), its forward method can be expressed as:

When using LoRA, updates are typically added to the outputs of these linear layers, yielding the following code:

If you want to implement LoRA by modifying an existing PyTorch model, a simple method is to replace each linear layer with a LinearWithLoRA layer:
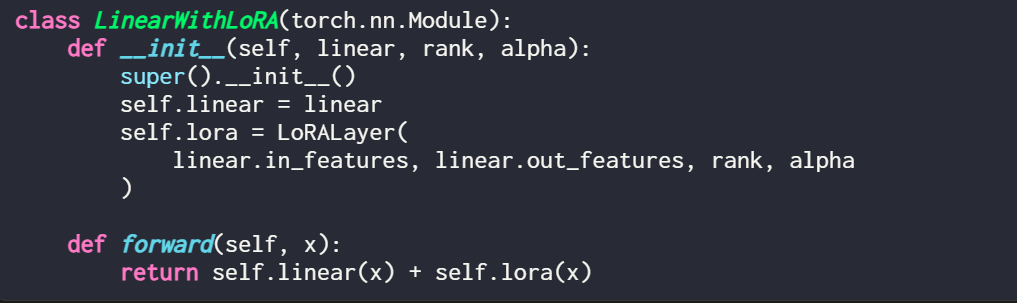
These concepts are summarized in the figure below:

To apply LoRA, this article replaces the existing linear layers in the neural network with the LinearWithLoRA layer, which combines the original linear layer and LoRALayer.
How to Get Started with LoRA Fine-Tuning
LoRA can be used for models such as GPT or image generation. For simplicity, this article uses a small BERT (DistilBERT) model for text classification.

Since this article only trains new LoRA weights, it is necessary to set the requires_grad of all trainable parameters to False to freeze all model parameters:

Next, use print(model) to check the structure of the model:

From the output, it can be seen that the model consists of 6 transformer layers, which contain linear layers:

Additionally, the model has two linear output layers:

By defining the following assignment function and loop, LoRA can be selectively enabled for these linear layers:
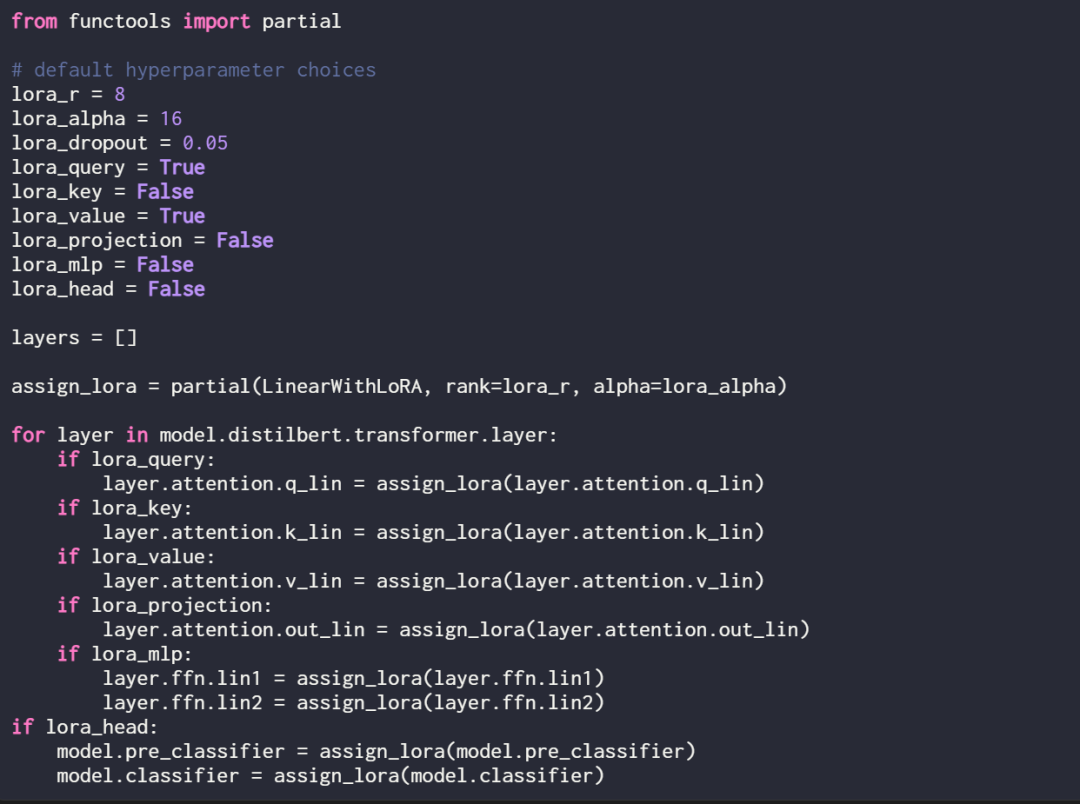
Use print(model) again to check the updated structure of the model:
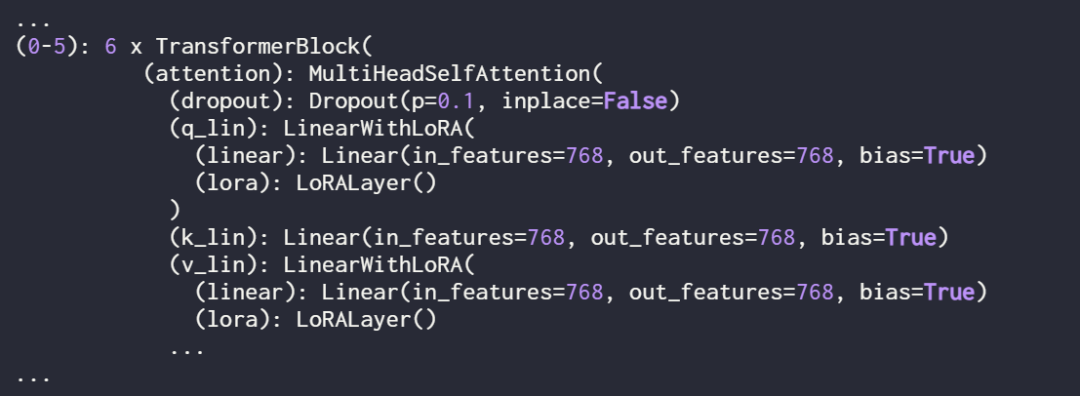
As seen above, the linear layers have been successfully replaced by the LinearWithLoRA layers.
If the model is trained using the default hyperparameters shown above, the following performance will be achieved on the IMDb movie review classification dataset:
-
Training accuracy: 92.15%
-
Validation accuracy: 89.98%
-
Test accuracy: 89.44%
In the next section, this article compares these LoRA fine-tuning results with traditional fine-tuning results.
Comparison with Traditional Fine-Tuning Methods
In the previous section, LoRA achieved a test accuracy of 89.44% under default settings; how does this compare with traditional fine-tuning methods?
To make a comparison, this article conducted another experiment using the DistilBERT model as an example, but only updating the last 2 layers during training. The researcher achieved this by freezing all model weights and then unfreezing the two linear output layers:
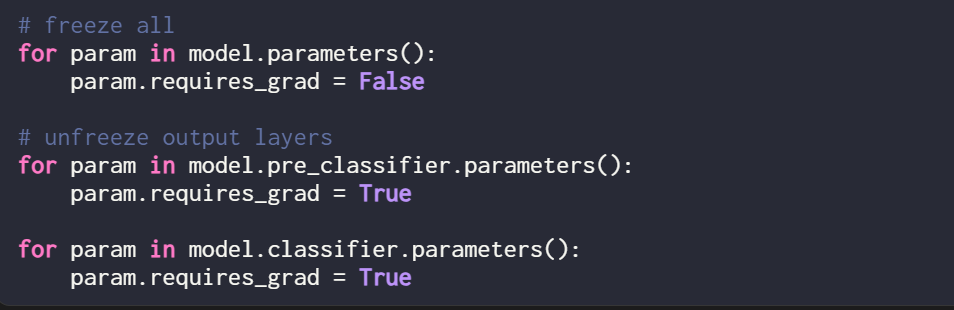
The classification performance obtained by training only the last two layers is as follows:
-
Training accuracy: 86.68%
-
Validation accuracy: 87.26%
-
Test accuracy: 86.22%
The results show that LoRA outperforms the traditional fine-tuning method that only updates the last two layers, but it uses four times fewer parameters. Fine-tuning all layers requires updating 450 times more parameters than the LoRA setup, but the test accuracy only improves by 2%.
Optimizing LoRA Configuration
The results mentioned earlier were all obtained with LoRA under default settings, with the following hyperparameters:

If users want to try different hyperparameter configurations, they can use the following command:

However, the optimal hyperparameter configuration is as follows:

With this configuration, the results are:
-
Validation accuracy: 92.96%
-
Test accuracy: 92.39%
It is worth noting that even though the LoRA setup has only a small number of trainable parameters (500k vs. 66M), the accuracy is still slightly higher than that obtained through full fine-tuning.
Original link: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?continueFlag=f5fc72b1f6eeeaf74b648b2aa8aaf8b6