
 Click to join the discussion group→👥 Discuss with 1000+ embodied intelligence researchersEntrepreneurship × RL × VLA Open Source Project Collection: Yushu | VLA | Reinforcement Learning Control | RL Framework Practice | Unitree RL_Gym
Click to join the discussion group→👥 Discuss with 1000+ embodied intelligence researchersEntrepreneurship × RL × VLA Open Source Project Collection: Yushu | VLA | Reinforcement Learning Control | RL Framework Practice | Unitree RL_Gym
Core Ideas and Innovations
💬 Editor’s Perspective
GentleHumanoid allows the robot’s upper body to be compliant, enabling it to move along with humans, while ensuring that the safety force limits are not exceeded. It is not simply adding impedance control, but rather transforming “compliance” into a learnable unified dynamics rule, embedded throughout the shoulder-elbow-hand chain, making human-robot interaction truly natural, stable, and trustworthy.
Project Homepage: https://firm2025.github.io/
Core Ideas of the Paper
GentleHumanoid first unifies “target action drive” and “interaction forces generated by physical contact” into a learnable spring-based reference dynamic system, allowing the shoulder, elbow, and hand to respond collaboratively under the same mechanical rules.
This reference dynamic system can express both resistive contact (e.g., pushing, supporting) and guiding contact (e.g., being pushed, pulled, embraced), and by sampling postures from real human actions, these guiding forces naturally conform to human movement structures.
During training, the strategy does not directly learn “compliance” through brute force, but instead uses this reference dynamics as a teacher, allowing the student strategy to reproduce this “soft yet stable, compliant yet not collapsing” upper body compliant behavior while relying solely on observable information from reality.
With the addition of adjustable safety force thresholds, the robot can switch between “gentle contact” and “firm support” in different scenarios, ultimately achieving natural, safe, and controllable real-world upper limb interaction.
Summary of Innovations
1️⃣ Unified Compliant Dynamics Framework: Describes driving actions and external contacts using a spring-based dynamics model, ensuring natural consistency in compliant behavior across the shoulder-elbow-hand chain;2️⃣ Human Action-Guided Interaction Modeling: Samples “guiding forces” from real human postures, allowing the robot to learn push, pull, and embrace interaction methods that conform to human mechanical structures;3️⃣ Adjustable Safety Compliance Levels: Controls compliance through variable force thresholds, enabling the robot to switch freely between “gentle hugging” and “firm assistance”;4️⃣ Teacher-Student Sim2Real Transfer: Uses privileged teacher learning for complex compliant dynamics, then distills it to the student strategy, achieving stable upper limb interaction on real hardware;5️⃣ Significant Real-World Verification Effects: Successfully completes hugging, sit-stand assistance, and fragile object manipulation on Unitree G1, demonstrating significantly better safety and naturalness compared to baseline.
Algorithm Implementation Details
Basic Ideas
The core of GentleHumanoid is not to let the strategy directly learn compliance, but to first construct an interpretable, controllable, and learnable reference dynamics system: abstracting the driving actions of the upper limb and all external contacts into a unified mechanical rule in the form of “spring-damping”.The strategy itself does not design these mechanical relationships, but instead mimics the “compliant behavior trajectories” generated by this reference dynamics through reinforcement learning. Thus, what the robot ultimately learns is not a specific action, but a stable, natural, and adjustable compliant response method.Combined with the asymmetric training structure of Teacher-Student, the final student strategy retains only the sensory data that can be obtained during real deployment, yet still presents a coordinated and compliant control of the entire upper limb that aligns with human interaction habits.
Overall Framework
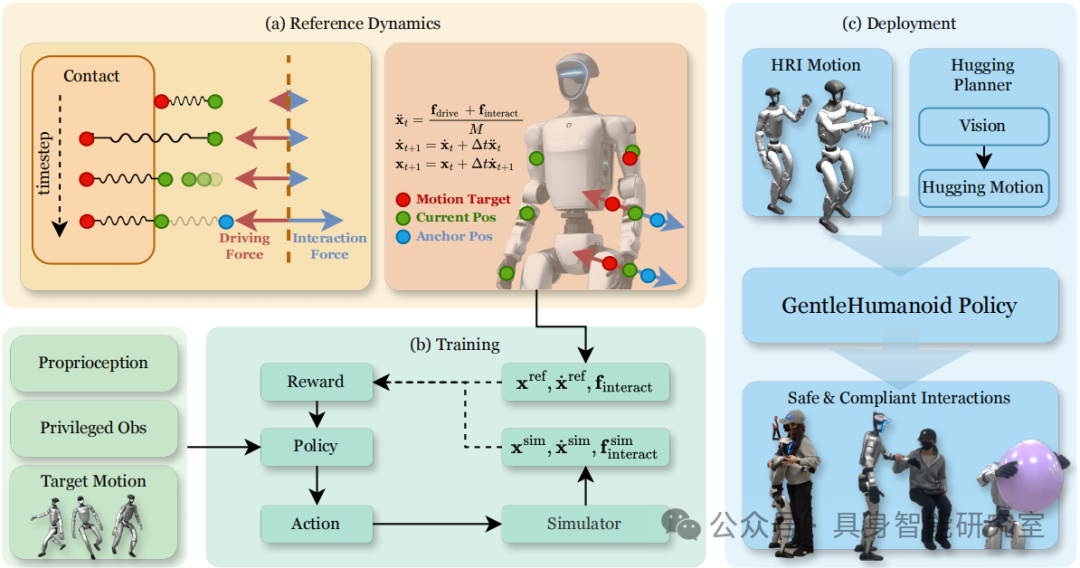
1. Reference Dynamics Construction
Input:
Target action sequence (from human action dataset)
Randomly generated external interaction forces (including resistive and guiding)
The system simulates the motion trends of the shoulder, elbow, and hand key points under driving forces and external disturbances based on the spring-damping model, obtaining the “reference pose trajectory” and “reference interaction force trajectory”.
Output:
Reference positions and velocities of upper limb key points
Corresponding reference interaction forces
Adjustable force thresholds (determining compliance level)
2. Teacher Strategy Training
The teacher strategy has access to all information that cannot be exposed to the robot during real training:
Key point poses generated by reference dynamics
Reference and actual contact forces
Real simulated contact forces
Current relative height, body state, historical errors, etc.
The teacher’s goal is very clear:to fully align with the compliant behavior generated by reference dynamics.
Utilizing all privileged information, full state observations, and complete reward signals, maximize the learning of that spring-based compliant rule, thus providing a distilled demonstration for the student.
Output:
High-quality, imitable compliant control actions (as the learning target for the student)
3. Student Strategy Distillation
The student strategy only accesses the observations that can be obtained during real deployment:
Self-perception (joint angles, velocities, gravity direction, etc.)
Historical actions
Future short-term target actions (from trajectory planning or hugging generation module)
Maximum allowable contact force threshold set by the current task
The student does not need to know the real contact forces or the internal details of the reference dynamics; it only needs to learn to reproduce the behavior patterns of the teacher strategy. The final distilled result is a compliant control strategy that can be plug-and-play on real robots:
Natural actions
Safe contact
Stable postures
Controllable response to disturbances
Zero-sample use in hugging/support/handling scenarios
⚙️ Algorithm Implementation Details
1. Upper Limb Interaction Force Model
The key breakthrough of the paper is dividing all external forces into two types:
① Resistive Contact When the robot presses against an object or human, it treats the “initial contact position” as a fixed anchor point. When the joints deviate from that point, a restoring force is generated, simulating real-world scenarios such as “being blocked, leaning against a wall, or pushing against an arm”.
② Guiding Contact This is more like human actions of “pulling you”, “pushing you”, or “hugging you”. The system randomly samples a complete upper limb posture from human action data, using the corresponding shoulder, elbow, and hand positions as guiding targets to generate natural pushing and pulling forces.
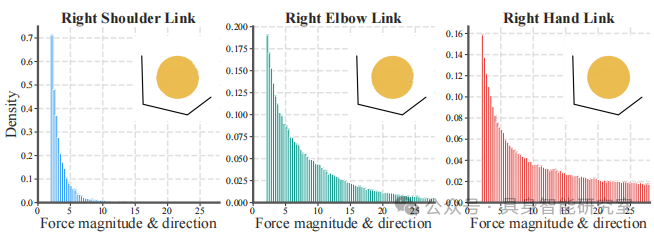
Both types of forces follow the same set of rules:
Act on the “shoulder-elbow-hand” multi-joint chain
Force directions are naturally coordinated, avoiding unnatural situations like “the hand pushes forward while the shoulder pulls back”.
Force magnitude, action chain, and triggering intervals are all randomized, covering a wide range of possible interaction scenarios.
This design ensures that the compliant responses learned by the strategy have a true human mechanical structure.
2. Adjustable Compliance Level: Force Threshold Control Mechanism
Each task sets a maximum contact force threshold, for example:
Hugging: 5–10N (gentle)
Sit-Stand Assistance: 10–15N (firm)
Fragile Objects: 5N (super gentle)
The strategy treats this threshold as an observation input, dynamically changing compliance levels across different tasks. When the internal driving force exceeds the threshold, the system automatically scales down proportionally, making the action “softer” to avoid hard impacts.
This is the key to transforming the entire framework from “able to be compliant” to “able to adjust compliance”.
3. Reward Design
In addition to conventional action tracking, balance, and gait stability rewards, there are three types of compliance-related rewards:
Reference Dynamics Tracking: Encourages the strategy to mimic the trajectories produced by the spring system, ensuring “yielding like a human”.
Reference Force Alignment: The strategy’s force response must align with the expected force direction of the reference dynamics, ensuring coordination.
Excessive Force Penalty: Any contact force that exceeds the threshold too much will be immediately penalized, ensuring human-robot safety.
These three serve as a “compliance behavior supervisor”, continuously shaping the strategy into a safe and reliable interactive entity during training.
4. Teacher-Student Sim2Real (Asymmetric Training)
To ensure stability on real hardware, the paper adopts a commonly used “asymmetric training” strategy in reinforcement learning:
Teacher Strategy: Omniscient Perspective (includes all available information)
Student Strategy: Real Deployment Perspective (can only see what the robot itself can sense)
The student achieves smooth transfer from simulation to reality by mimicking the teacher’s behavior distribution. Since the teacher’s behavior fully adheres to reference dynamics, it naturally possesses “physical meaning”, making it easier to implement in the real world without exhibiting erratic or unstable behaviors.
5. Action Generation Method: Self-Perception → Control Commands
The entire system’s input-output chain is:
The robot obtains self-perception, future short-window reference actions, and task-allowed force thresholds
The student strategy outputs target joint positions (as input for low-level PD control)
The PD controller directs the joints to the target positions
If external disturbances occur, the strategy automatically adjusts behavior based on the compliant rules learned from the teacher, allowing the body to yield slightly to external forces
The entire shoulder-elbow-hand chain maintains consistency under spring-based rules, ultimately forming natural compliant upper limb actions
This chain means that the strategy does not need explicit force control or special contact detection to naturally present human-like compliant behavior.
Simulation Testing and Result Analysis
🎯 Experimental Goals and Evaluation Philosophy
The experimental design of GentleHumanoid aims to prove whether this “unified compliant dynamics + RL distilled strategy” can truly enable humanoid robots to achieve safe, stable, and natural upper limb physical interaction in real environments. Therefore, the entire evaluation system focuses on the following three core capabilities:
Is compliance truly controllable: In interaction scenarios such as pushing, hugging, and supporting, can the robot move along with external forces instead of rigidly resisting?
Is control force stable and safe: Can it maintain contact forces within the task requirements without sudden peaks or localized high-pressure points?
Is Sim2Real robust: Can the distilled student strategy run directly on the real Unitree G1 while maintaining consistent compliant responses with the simulation?
The paper incorporates numerous external force disturbances, posture deviations, misaligned contacts, and fragile object interactions in both simulation and real experiments to verify that its compliant control is not a “coincidence”, but rather derived from generalizable dynamic rules.
📈 Overall Performance Comparison
The experiments mainly compare with two types of baselines:
Vanilla-RL: Only performs full-body tracking without considering compliance or contact forces;
Extreme-RL: Introduces significant external force disturbances during training but lacks systematic compliance modeling.
The paper will demonstrate the differences among the three in hugging, external force disturbances, assistive support, and fragile object interactions.
1. External Force Disturbance: A Qualitative Change from Resistance to Compliance
In the simulated hugging scenario, researchers apply an outward pulling force to simulate the scenario of separating a human from the robot.
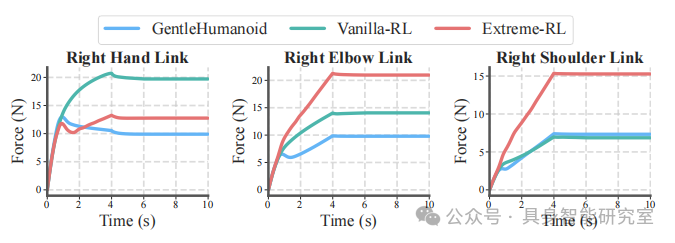
Vanilla-RL will directly enter “resistance mode”, with shoulder, elbow, and hand forces skyrocketing;
Extreme-RL is even more extreme, exhibiting force peak oscillations and potentially pulling the entire body out;
GentleHumanoid maintains a stable low force range, yielding slightly to the pulling force without being rigid or unstable.
All three chains (shoulder, elbow, hand) exhibit low and smooth force curves, proving that multi-joint compliance is collaborative rather than a coincidence at a single point.
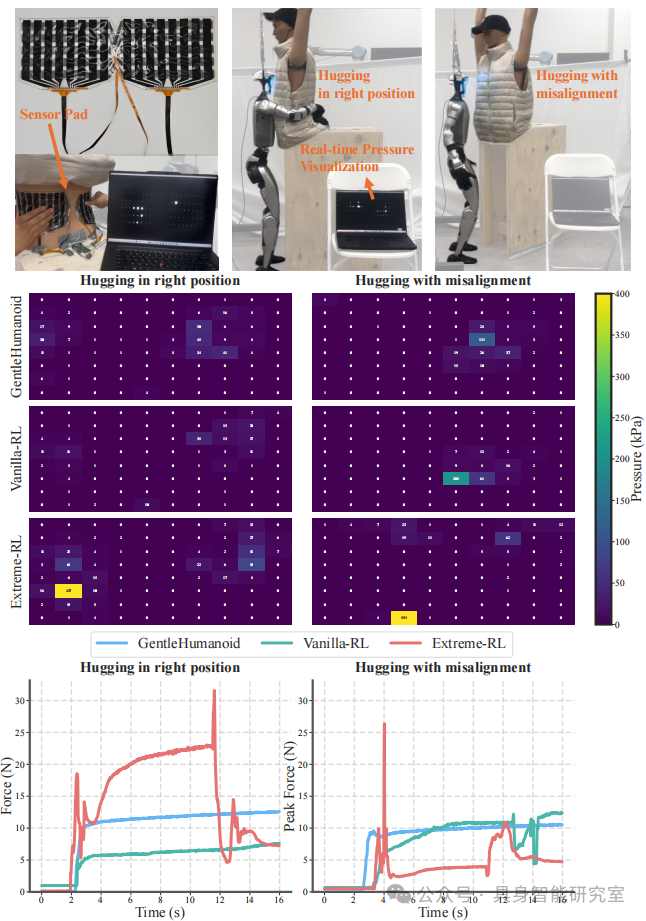
2. Misaligned Hugging: A Real Human Problem
Real hugging scenarios cannot always be perfectly aligned, so the paper specifically conducts a “misaligned hugging” test:

Baseline Strategies exhibit unstable behaviors such as “getting stuck, pushing back suddenly, or jamming” when facing alignment deviations, resulting in localized high pressure;
GentleHumanoid automatically adjusts its upper body posture due to the spring-guided reference dynamics, allowing contact forces to naturally diffuse even when misaligned, avoiding dangerous peaks.
The most intuitive result is the pressure sensor mat’s distribution map: the baseline shows “bright spots clustered together”, while GentleHumanoid shows “even and gentle” distribution.
3. Fragile Object Test: Can It Hold a Balloon?
This is the ultimate scenario to verify compliance.
When the robot hugs a balloon:
Extreme-RL/Vanilla-RL will crush the balloon due to inability to lower contact forces, even leading to instability.
GentleHumanoid locks itself in “super gentle mode” through force threshold adjustment, achieving control that “supports without crushing”.
This is a strong validation: maintaining stable actions in fragile object scenarios is the most challenging and differentiating aspect of the compliance framework.
4. Sit-to-Stand Assistance: High Contact Forces Can Also Provide Stable Support
When tasks require strong support, compliance cannot become “too soft”. The paper verifies the high threshold mode (e.g., 10–15N):
GentleHumanoid can stably output sufficient contact support force to assist a mannequin in standing up while maintaining torso stability;
Baseline Strategies either “over-support” or “excessive reaction forces lead to regression or instability”.
This demonstrates the core advantage of the method being “adjustable compliance”.

It’s not easy to organize, please like and follow~
