Recently, Anthropic shared their best practices in building multi-agent research systems, focusing on8 principles of prompt engineering and evaluation for research agents: Claude now possesses research capabilities, able to complete complex tasks through web searches, Google Workspace, and any integrated tools.
Claude now possesses research capabilities, able to complete complex tasks through web searches, Google Workspace, and any integrated tools.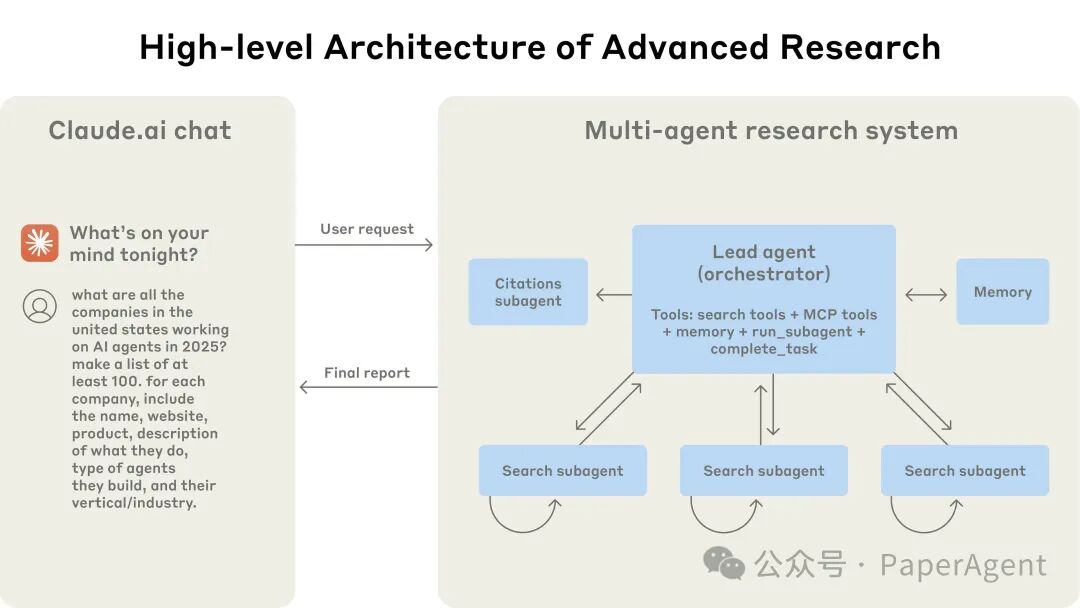 AnthropicThe architecture of the multi-agent research system adopts a coordinator-worker model: the system consists of a lead agent and multiple subagents. The lead agent is responsible for coordinating and assigning tasks, while subagents execute specific tasks in parallel.In contrast to traditional RAG methods that use static retrieval,Anthropic‘s architecture employs multi-step searches to dynamically find relevant information, adapt to new discoveries, and analyze results to formulate high-quality answers.
AnthropicThe architecture of the multi-agent research system adopts a coordinator-worker model: the system consists of a lead agent and multiple subagents. The lead agent is responsible for coordinating and assigning tasks, while subagents execute specific tasks in parallel.In contrast to traditional RAG methods that use static retrieval,Anthropic‘s architecture employs multi-step searches to dynamically find relevant information, adapt to new discoveries, and analyze results to formulate high-quality answers.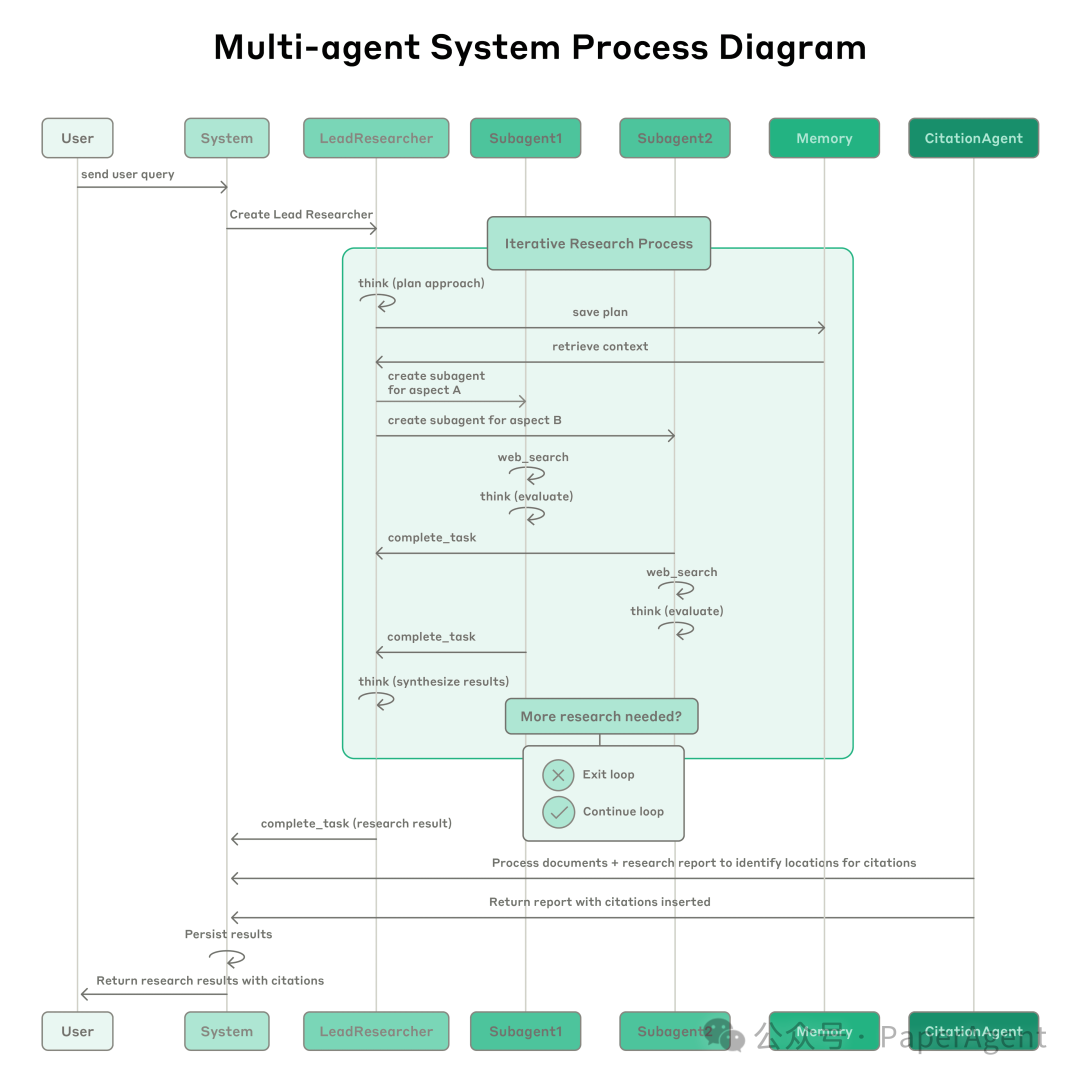 Prompt Engineering and Evaluation for Research Agents
Prompt Engineering and Evaluation for Research Agents
Multi-agent systems have key differences from single-agent systems, including a rapid increase in coordination complexity. Early agents made mistakes, such as generating 50 subagents for simple queries, endlessly searching for non-existent sources online, or interfering with each other through excessive updates.Since each agent is guided by prompts, prompt engineering is the primary means to improve these behaviors:
-
Think like your agent. To iterate on prompts, you must understand their effects. Use the exact prompts and tools in the system, then observe the agent’s work step by step. This immediately reveals failure modes: agents continue running when sufficient results have already been obtained, use overly verbose search queries, or choose the wrong tools. Effective prompts rely on developing an accurate mental model of the agent, making the most impactful changes evident.
-
Teach the coordinator how to delegate tasks. The lead agent breaks down queries into subtasks and describes these tasks to the subagents. Each subagent needs a goal, output format, guidance on tools and sources to use, and clear task boundaries. Without detailed task descriptions, agents may duplicate work, leave gaps, or fail to find necessary information. Initially, allowing the lead agent to give simple, brief instructions like “research semiconductor shortages” was found to be too vague, leading to subagents misunderstanding tasks or conducting identical searches as other agents.
-
Adjust workload based on query complexity. Agents struggle to judge the appropriate workload for different tasks, so adjustment rules were embedded in the prompts. Simple fact-finding only requires 1 agent for 3-10 tool calls, direct comparisons may need 2-4 subagents, each making 10-15 calls, while complex research may require over 10 subagents, each with clearly defined responsibilities. These clear guidelines help the lead agent allocate resources efficiently and prevent over-investment in simple queries.
-
Tool design and selection are crucial. The interface between agents and tools is as important as the human-computer interface. Using the right tools is efficient—often, it is absolutely necessary. Agents are provided with clear heuristic rules: for example, first check all available tools, match tool usage with user intent, conduct broad external exploration through web searches, or prioritize specialized tools over general ones. Poor tool descriptions can lead agents down completely wrong paths, so each tool needs a clear purpose and description.
-
Enable agents to self-improve. The Claude 4 model can be an excellent prompt engineer. When given a prompt and a failure mode, it can diagnose the reasons for agent failures and suggest improvements. It even created a tool to test agents—when given a flawed MCP tool, it attempts to use that tool and then rewrites the tool description to avoid failure. Through multiple tests of the tool, this agent can discover key nuances and vulnerabilities. This process of improving tool usability reduces the task completion time for subsequent agents using the new descriptions by 40%, as they can avoid most errors.
-
Explore broadly first, then narrow down. Search strategies should mimic expert human research: first explore the overall situation, then delve into specific details. By prompting agents to start with brief and broad queries, assess available information, and then gradually narrow the focus, this tendency is offset.
-
Guide the thinking process. Expanding the thinking model (leading Claude to output additional tokens with visible thought processes) can serve as a controllable draft. The lead agent uses thinking to plan its approach, assess which tools are suitable for the task, determine the complexity of queries and the number of subagents, and define the roles of each subagent.
-
Parallel tool calls change speed and performance. Complex research tasks naturally involve exploring many sources. To increase speed, two types of parallelization were introduced: (1) the lead agent simultaneously launches 3-5 subagents instead of sequentially; (2) subagents use 3 or more tools simultaneously. These changes reduced the research time for complex queries by up to 90%, allowing more work to be completed in minutes rather than hours, while covering more information.
https://www.anthropic.com/engineering/built-multi-agent-research-systemhttps://cognition.ai/blog/dont-build-multi-agentsIf you like this article, please click the upper right corner to share it with your friends.If there are technical points you would like to learn about, please leave a message for Ruofei to arrange a sharing session.
Due to changes in the public account’s push rules, please click “View” and add “Star” to get exciting technical shares at the first time.
·END·
相关阅读:-
A16z: In-Depth Understanding of the Future of MCP and AI Tool Ecosystem
-
2025 AI Agent Technology Stack Overview
-
Dear IT Department, Please Stop Trying to Build Your Own RAG Systems
-
“Three-Hour Replica of Manus, GitHub 20,000 Stars”: Technical Breakdown of the OpenManus Multi-Agent Framework
-
Understanding MCP: From Technical Principles to Practical Implementation
-
Overview of Three Major Open Source Manus Replication Projects
-
Unveiling the Working Principles of Manus: Deconstructing the Multi-Agent Architecture of Next-Generation AI Agents
-
Illustrating What a Reasoning Model Is
-
A Detailed Explanation of the Past and Present of DeepSeek R1
-
From Scratch to Drawing the Architecture and Training Process of DeepSeek R1
-
Illustrating the Innovative Training and Reasoning Model Implementation Principles of DeepSeek-R1
-
Deploying Full-Blooded DeepSeek-R1 on Ascend 910B
-
Technical Interpretation of DeepSeek V3, R1, Janus-Pro Series Models
- Qwen Architecture Modified to DeepSeek, Then Reproducing R1
- DeepSeek Exploded, How Ordinary People Can Train Their Own Large Models from Scratch in 3 Hours
- DeepSeek Prompt Writing Techniques Collection Edition!
- Explaining DeepSeek Principles in Simple Terms
- Understanding the Evolution and Implementation of DeepSeek in MoE Technology
- In-Depth Analysis of DeepSeek’s Distillation Technology
- Discussing the Technical Path of DeepSeek-R1
- Latest Insights on DeepSeek
Source:PaperAge
Copyright Statement: Content sourced from the internet, for learning and research purposes only, copyright belongs to the original author. If there is any infringement, please inform us, and we will delete it immediately and apologize. Thank you!
Architect
We are all architects!

Follow Architect (JiaGouX), add “Star”
Get daily technical insights and become an outstanding architect together
For technical groups, pleaseadd Ruofei:1321113940 to join the architect group
For submissions, collaborations, copyright, etc., please email:[email protected]