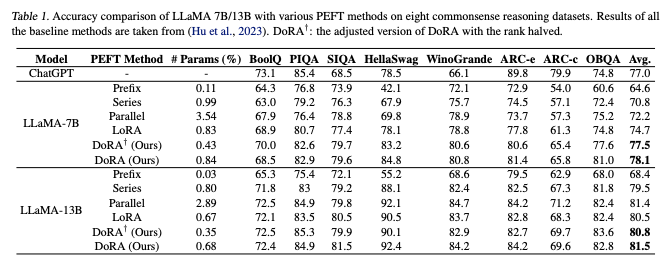
The mainstream method for fine-tuning LLMs, LoRA, has a new variant. Recently, NVIDIA partnered with Hong Kong University of Science and Technology to announce an efficient fine-tuning technique called DoRA, which achieves more granular model updates through low-rank decomposition of pre-trained weight matrices, significantly improving fine-tuning efficiency. In a series of downstream tasks, both training speed and performance are clearly superior to LoRA!

To help everyone quickly grasp the latest algorithm, Yuanmeng Feifan has invited a leading researcher in the field to customize a live class“AI Frontier Paper Analysis Series—DoRA: Weight-Decomposed Low-Rank Adaptation“, covering everything from a systematic overview of PEFT (Parameter-Efficient Fine-Tuning) to a comparison of the characteristics and algorithms of LoRA and DoRA, allowing participants to fully experience the excitement of fine-tuning large models!
▼ Scan to add teaching assistantsFreeReserve a live class!
Get free👇100 must-read papers on large models/multimodal large language models+50 hours of 3080 GPU computing power

🎁 6 types of research benefits available for free until the end of the article
“AI Frontier Paper Analysis Series—DoRA: Weight-Decomposed Low-Rank Adaptation“
March 19, 19:20 (Tuesday)
🌟 Overview of common large model efficient fine-tuning techniques
🌟 Comparison of the working principles of DoRA and LoRA algorithms
🌟 Implementation of DoRA and LoRA prototypes through code
🌟 Comparison of different fine-tuning methods in terms of parameters, costs, and accuracy
🌟 Applicability analysis of various fine-tuning techniques in different application scenarios
🌟 Outlook on future work and potential improvements related to the DoRA algorithm
▎Live Class Overview
■ Parameter-Efficient Fine-Tuning
■ Memory-Efficient Fine-Tuning
■ Parameter-Efficient Fine-Tuning
▼ Scan to add teaching assistants,FreeReserve a live class!

Get free!100 must-read papers on large models/multimodal large language models+50 hours of 3080 GPU computing power
🎁 6 types of research benefits available for free until the end of the article
■ Overview of DoRA
■ Low-Rank Adaptation (LoRA)
■ Weight Decomposition Analysis
■ Weight-Decomposed Low-Rank Adaptation
■ Gradient Analysis of DoRA
5️⃣ Code Implementation
■ Settings and Dataset
■ Multilayer Perceptron Model (without LoRA and DoRA)
■ Multilayer Perceptron Model (with LoRA and DoRA)
■ Train model with LoRA
■ Train model with DoRA
■ Multi-GPU IO-Aware Methods
▎Live Class Instructor
Lattner Instructor
Senior Expert in Efficient Computing for Large Models; Entrepreneur and Partner in AI Companies, proficient in deep learning, machine learning, high-performance computing, etc.; has made achievements in natural language processing, computer vision, multimodal fields.
▼ Scan to add teaching assistants,FreeReserve a live class!

Get free!100 must-read papers on large models/multimodal large language models+50 hours of 3080 GPU computing power
🎁 6 types of research benefits available for free until the end of the article
▎Mentor Team
Yuanmeng has a strong high-education mentor team, with rich research experience in computer science, machine learning, deep learning, and has published research results in major international conferences and journals, adhering to the original intention of personalized teaching throughout the process.



