
Title: Multi-Token Attention
Paper Link: https://arxiv.org/pdf/2504.00927

Innovations
-
This paper presents a new attention method—Multi-Token Attention (MTA), which allows the model to adjust attention weights based on multiple query and key vectors simultaneously. By applying convolution operations on queries, keys, and attention heads, MTA enables nearby queries and keys to influence each other, resulting in more precise attention allocation.
-
In addition to key-query convolution, MTA also introduces head mixing convolution. This convolution operation occurs between groups of attention heads, allowing attention weights to influence each other across different heads. For example, by dividing all heads into multiple groups and applying non-overlapping convolution operations within each group, MTA can share information between heads, further enhancing the model’s ability to process complex information.
Methodology
This paper proposes a new attention mechanism—Multi-Token Attention (MTA), aimed at addressing the limitations of traditional soft attention mechanisms when dealing with long contexts and complex information. The core idea of MTA is to apply convolution operations on queries, keys, and attention heads, allowing the model to consider multiple query and key vectors simultaneously when calculating attention weights. This method breaks the limitation of traditional attention mechanisms that rely solely on the similarity of a single query and key vector, enabling the model to utilize richer information to locate relevant parts of the context. Specifically, MTA consists of three key components: key-query convolution, head mixing convolution, and group normalization with gating mechanisms.
Comparison of Multi-Token Attention (MTA) with Standard Attention Mechanisms
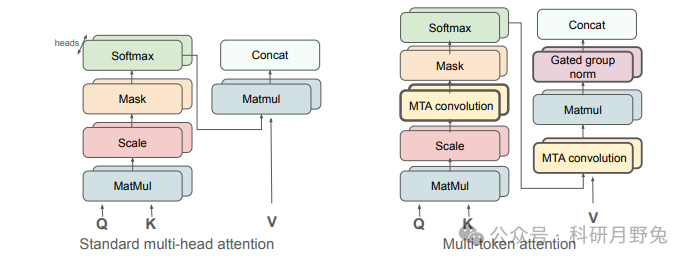
This figure illustrates the comparison between Multi-Token Attention (MTA) and standard multi-head attention mechanisms. In standard multi-head attention, each attention head calculates attention weights based solely on the similarity of a single query and key vector, which limits the amount of information the model can use to distinguish contextually relevant parts. In contrast, MTA allows the model to consider multiple query and key vectors simultaneously by applying convolution operations on queries, keys, and attention heads, resulting in more precise attention allocation. In MTA, key-query convolution is first applied within each attention head, combining information from multiple queries and keys, allowing nearby queries and keys to influence attention weights. Then, head mixing convolution shares information between different attention heads, further enhancing the model’s ability to process complex information. Finally, MTA applies convolution operations again after the softmax operation and applies group normalization and scalar gating mechanisms before the final concatenation to stabilize the training process and improve model performance.
Key-Query Convolution and Head Mixing Convolution in Multi-Token Attention (MTA)
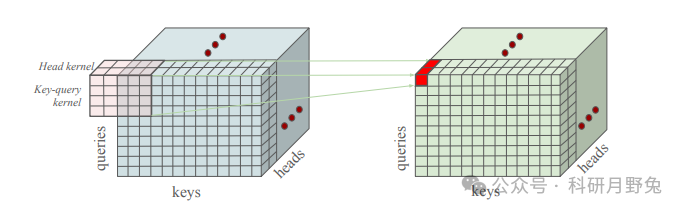
This figure details the two core operations in Multi-Token Attention (MTA): Key-Query Convolution and Head Mixing Convolution. These two operations enable MTA to surpass traditional “single-token” attention mechanisms by combining information from multiple queries, keys, and attention heads to enhance the calculation of attention weights.
Performance of Multi-Token Attention (MTA) on Toy Tasks
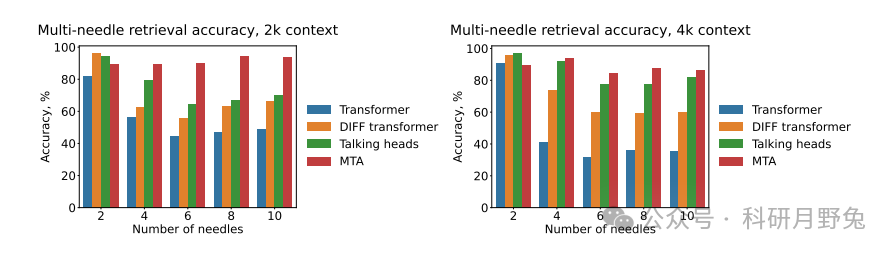
This figure shows the performance of Multi-Token Attention (MTA) on a simple toy task. This toy task is designed to reveal the limitations of standard attention mechanisms and validate the effectiveness of MTA in scenarios that require multiple information fragments to locate targets. The task setup is as follows: the model receives a series of blocks composed of random letters, each block containing N letters, followed by L question letters (L < N). The model’s goal is to find the block containing all question letters and output all letters of that block, or only output the first or last letter of that block (as three different task variants).
Experiments
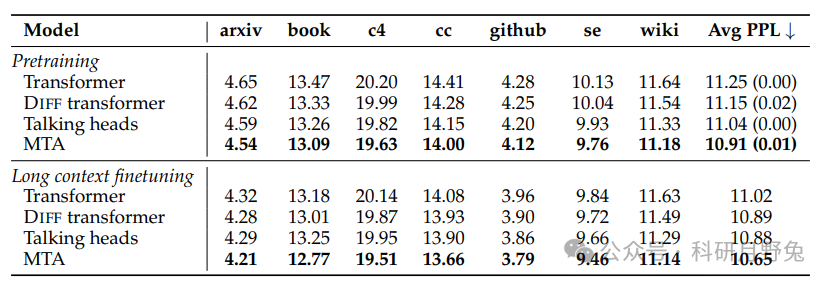
This table presents a comparison of validation perplexity for different model architectures on large-scale language modeling tasks. These models include the standard Transformer model, Differential Transformer (DIFF Transformer), Transformer model with Talking Heads attention, and the Multi-Token Attention (MTA) model proposed in this paper. All models were pre-trained on the SlimPajama dataset, using 105B tokens, and evaluated on different validation datasets. The results show that the MTA model outperforms or is comparable to other baseline models across all validation datasets. Specifically, MTA achieves lower validation perplexity on multiple datasets, indicating its performance improvement in language modeling tasks. For instance, on the arxiv dataset, MTA’s perplexity is 4.54, lower than the standard Transformer’s 4.65 and DIFF Transformer’s 4.62. On the book dataset, MTA’s perplexity is 13.09, also lower than the standard Transformer’s 13.47 and DIFF Transformer’s 13.33. The results in this table indicate that the MTA model has significant performance advantages in large-scale language modeling tasks, especially in handling long-context tasks. This validates the effectiveness of MTA in utilizing richer information to locate relevant parts of the context, thereby enhancing the overall performance of the model.