Virtualization technology has matured significantly today, thanks to the active participation of major internet companies. It relies on the Hypervisor to map virtual resources (such as vCPU, virtual memory, virtual devices, etc.) to the physical resources of the Host, thereby providing multiple virtual machine resources and maximizing hardware resource utilization. For instance, the VxLAN technology in Layer 2 achieves expansion by adding a field at the protocol layer, removing the three-layer transport logic from the outer layer of the packet, and then attaching the payload to the VLAN. This is a form of sleight of hand; fundamentally, virtualization is also a form of illusion, encapsulating and re-presenting the underlying hardware resources.
Operating SystemKernel‘s security isolation mechanism and resource management
Root Mode + Ring Privilege: Layered guarantees of virtualization isolation
One person plays multiple roles
A process is a virtual machine, a thread is avCPU?
Memory requires three layers of conversion to bear fruit
Device virtualization’s interrupt interception
Do interrupts also need virtualization?
Performance issues brought by virtualization
Operating SystemKernel‘s security isolation mechanism and resource management
The kernel mode and user mode are the traditional security isolation mechanisms of the operating system, used to isolate the kernel from applications. Correspondingly, CPU instructions are also divided into privileged and non-privileged instructions. Privileged instructions can only run in kernel mode; if executed in user mode, they will trigger a processor exception.
The Kernel runs in kernel mode, while ordinary user programs run in user mode. As shown in the figure below, Ring 0-3 is the privilege protection mechanism of the x86 architecture CPU, with privilege levels decreasing from 0 to 3. Ring 0 has the highest privilege (kernel mode), while Ring 3 has the lowest (user mode).
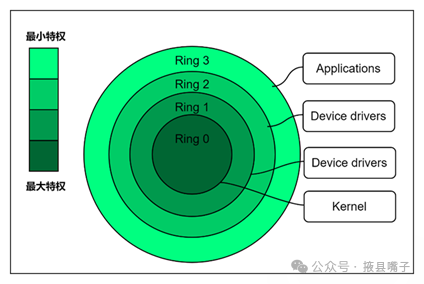
The operating system manages resources primarily through the kernel: CPU, memory, and IO devices.
CPU: Through scheduling algorithms (such as time-slice rotation, priority scheduling), it allocates CPU time slices to multiple processes, achieving concurrent execution.
Memory management: Divides physical memory and virtual memory, allocates independent memory space for processes, and prevents unauthorized access through memory protection.
IO device management: Through device drivers, it uniformly manages hardware such as disks, keyboards, and network cards, providing standardized IO operation interfaces for applications.
Root Mode + Ring Privilege: Layered guarantees of virtualization isolation
Intel developed VT technology, adding Virtual-Machine Extensions, abbreviated as VMX, to the CPU. Once the VMX support of the CPU is enabled, it will provide two operating modes: Root Mode (VMX Root Mode) and Non-Root Mode (VMX non-Root Mode), each supporting Ring 0-Ring 3. The effective isolation between virtual machines and the host is achieved through these two operating modes and Ring privilege isolation.
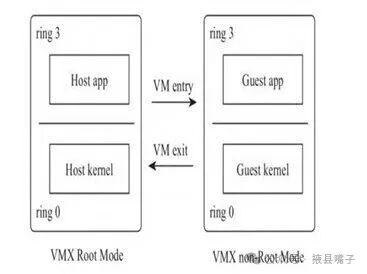
Root Mode: Only VMM can run. It has the highest privilege, responsible for managing physical resource allocation, virtual machine scheduling, and intercepting privileged instructions from virtual machines.
Non-Root Mode: For Guest virtual machines to run. Privileges are restricted, and direct access to physical hardware is not allowed; access must be indirect through VMM, ensuring resource isolation and security between different virtual machines.
In traditional physical machines, applications run in user mode, entering kernel mode through system calls to access hardware resources. This operation becomes quite special in virtualization scenarios; virtual machines cannot directly access the host, but the instructions still require the actual host CPU time slice to execute. Additionally, if a virtual machine process needs to access virtual resources, they must also be mapped to hardware resources to succeed. How is this entire mapping and isolation mechanism achieved? It is through Root Mode and Non-Root Mode.
In Root Mode, VMM can switch to Non-Root Mode by executing the virtualization instruction VMLaunch, as this process is equivalent to entering a virtual machine, it is often referred to as VM entry. When the virtual machine executes sensitive instructions, such as certain I/O operations, it will trigger the CPU to perform a trap action, switching back from Non-Root Mode to Root Mode, which is equivalent to exiting the VM, hence also called VM exit.
As a virtual machine, everything must obey the arrangements of VMM; it can only use the virtual resources allocated to it and cannot seize other resources. The host cannot see the specific processes within the virtual machine; it can only perceive the virtual machine processes. Conversely, processes within the virtual machine cannot directly access the host’s processes and resources.
For example: Virtual machine user programs (such as Nginx, MySQL) run in user mode and cannot directly access kernel resources; they must enter kernel mode through system calls (such as read(), write()). System call interception: User-mode system calls are handled by the virtual machine Guest kernel, but requests involving hardware resources (such as file IO, network communication) still require Hypervisor intervention to map to physical hardware for a response.
One person plays multiple roles
Just as a CPU can time-share multiple tasks, each task has its own context, switched by the scheduler during scheduling, allowing the same CPU to run multiple tasks simultaneously. In virtualization scenarios, the physical CPU resources on the host must also play multiple roles, time-sharing between the host and multiple Guest virtual machines, switching between different modes as needed, with each mode needing to save its own context data.
To this end, VMX has designed a data structure to save context: this is the core data structure of VMX, the VMCS. Each virtual machine Guest has a VMCS instance. When the physical CPU loads different VMCS, it will run different virtual machines Guest. Whenever the virtual machine Guest switches processes, the kernel of the virtual machine Guest will set the cr3 register to point to the corresponding VMCS.
A process is a virtual machine, a thread is avCPU?
A virtual machine is created using a process on the Host, running the virtual machine within this process, and then using a thread within the process to create a vCPU. Thus, a virtual machine with 4 vCPUs appears as a process with 4 threads on the host. If this 4-core virtual machine (with 4 vCPUs) runs on an 8-core host, the Hypervisor‘s scheduler (such as kvm_sched) will dynamically allocate the 4 vCPUs to the 8 hardware threads (physical CPU cores or hyper-threads) on the host, with each vCPU occupying a time slice of a hardware thread. This is the essence of virtualization.
Many people are confused about whether there is a mapping relationship between the host process and the virtual machine’s process, whether Hypervisor has done something to manipulate it. In fact, there is not; the processes/threads of the virtual machine do not directly correspond to any specific process or thread on the Host. They are scheduled by the virtual machine Guest kernel itself, which merely maps the execution context of the Guest to the physical resources of the Host (such as CPU, memory), essentially using the time slices of the Host CPU (or memory, IO) only.
The execution of processes within the virtual machine (Guest Process) requires three layers of mapping: “process → virtual hardware → physical hardware”. Each layer is scheduled by the corresponding kernel/component:
First layer: The Guest OS kernel schedules processes within the virtual machine. Like physical machines, the Guest OS will assign PID to internal processes, manage their lifecycle, and allocate them to vCPUs through scheduling algorithms, executing instructions first on virtual memory.
Second layer: The Hypervisor maps virtual resources. The instructions of vCPU will be intercepted by the Hypervisor. If they are ordinary instructions (such as arithmetic operations), they are directly handed over to the host CPU for execution. If they are privileged instructions (such as modifying hardware configurations), they are executed by the Hypervisor to avoid compromising the host’s security.
Third layer: The host OS schedules the virtual machine processes.
As mentioned earlier, vCPU is a software abstraction. At the host level, the Hypervisor typically creates software threads to manage its execution state. For example, in KVM, each vCPU corresponds to a struct kvm_vcpu structure, managed by the Hypervisor kernel thread (such as kvm/kvm-vcpu). This thread is responsible for handling the execution of vCPU (such as executing Guest code, handling VM Exit). The Hypervisor binds the vCPU of the virtual machine Guest to the physical CPU of the host through scheduling algorithms (such as kvm_vcpu scheduling in Linux). The Guest processes/threads run on the physical CPU time slices provided by the vCPU, saving the vCPU state during VM Exit (such as when a privileged instruction is triggered) and restoring it during VM Entry.
For the host, the entire virtual machine is a large process (such as the qemu-kvm process of KVM, or the vmware-vmx process of VMware). The host kernel will allocate physical CPU time slices, physical memory, IO devices, and other resources to this large process just like scheduling ordinary processes. Then, the various processes or threads of the virtual machine will receive sufficient physical CPU time slice resources to consume. Many people are concerned about the limitations of processes, always feeling that a small process on the host cannot bear the burden of a virtual machine. Here is a vivid analogy: when the big river has water, the small river is full; when the big river has no water, the small river is dry. Essentially, everything is about CPU time slices; processes and threads are merely containers for wrapping time slice logic, which can be large or small.
Memory requires three layers of conversion to bear fruit
In traditional physical machine memory management, there is the concept of a page table, where the virtual address of the application VA to the physical address PA managed by the operating system is already a layer of virtualization mapping.
In virtualization scenarios, with memory virtualization, the address mapping adds another layer. The Hypervisor must maintain a shadow translation table for each virtual machine. To elaborate on this shadow table, in protected mode, a separate table is created for each Guest process, recording the mapping relationship from GVA to HPA.
When the MMU receives GVA, it traverses this new table to ultimately translate GVA to HPA, sending the correct physical address onto the address bus. Among them, KVM needs to construct a page table mapping from GVA to HPA, and this page table needs to be updated based on the internal page table information of the Guest. This table looks like a shadow of the page table in the Guest, following it closely. In actual address mapping, since the cr3 register points to the page table constructed by KVM, this table takes effect, obscuring (shadowing) the internal page table of the Guest. Therefore, this page table constructed by KVM is referred to as the shadow page table. Once the shadow page table is constructed, mapping from GVA to HPA can be done in one translation, but establishing this mapping requires three conversions: the first is completed by the Guest using its own page table to convert GVA to GPA; the second is completed by KVM based on memory bar information to convert GPA to HVA; the third is completed by the host using the kernel’s memory management mechanism to convert HVA to HPA.
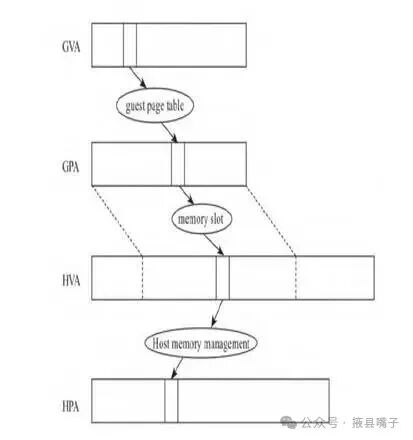
KVM modifications to the shadow page table lead to repeated switches from Guest mode to Host mode, greatly affecting performance. Intel has introduced an EPT mechanism at the hardware level to improve this, as it executes at the hardware level, making the mapping from GVA to HPA nearly zero loss. From the host’s perspective, a virtual machine is just a process, so maintaining an EPT table is sufficient, which reduces memory usage compared to the shadow page table. Because when the Guest internally switches processes, there is no need to switch the EPT, thus reducing the CPU switching between Guest mode and Host mode.
Device virtualization’s interrupt interception
Device virtualization should be quite familiar; complete virtualization means simulating hardware logic according to hardware specifications. This method is completely transparent to the virtual machine Guest, and the Guest operating system does not need to make any modifications. These virtual devices are indistinguishable from real drivers in the Guest kernel.
As mentioned earlier, if the client virtual machine wants to use the underlying hardware resources, it needs the Hypervisor to intercept every request instruction and simulate the behavior of these instructions.The action of the Hypervisor intercepting instructions is the VM-Exit process, which processes the simulation and then VM-Entry. This process is costly; every instruction must go through this, leading to significant performance overhead.
To improve efficiency, the Virtio virtualization method was invented, which is entirely software-based. The client completes the front-end driver program for the device, while the Hypervisor collaborates with the client to complete the corresponding back-end driver program. This way, the two can achieve an efficient virtualization process through an interaction mechanism.
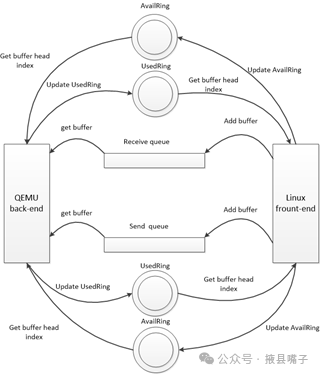
The Virtio framework uses Virtqueue to implement its I/O mechanism. Each Virtqueue is a queue that carries data. Vring is the specific implementation of Virtqueue, with corresponding descriptor tables describing Vring. The Virtio framework is a general driver and device interface framework, implementing many different types of simulated devices and device drivers based on Virtio, such as Virtio-net, Virtio-blk, Virtio-scsi, etc.
Compared to I/O software simulation virtualization, the performance advantages of Virtio virtualization lie in the fact that many control and status information do not need to be exchanged through register read/write operations, but rather through writing to the Virtqueue data structure, allowing the driver (Driver) and device (Device) to interact. Moreover, during data exchange, notifications are only sent when a certain batch of data changes requires the other party to process.
In addition to software-level optimizations, chip manufacturers are also improving at the hardware level, leading to the emergence of the SR-IOV solution.
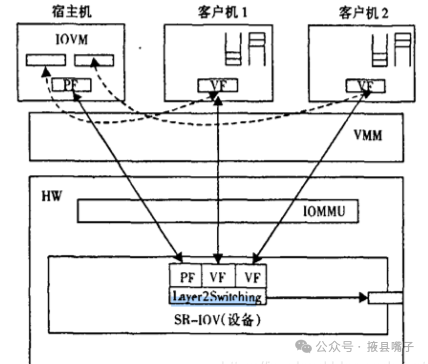
The SR-IOV solution introduces two types of PCIe devices.
PF (Physical Function): Includes all PCIe devices, including those managing SR-IOV functionality.
VF (Virtual Function): A lightweight PCIe device that can only perform necessary configurations and data transfers.
The Hypervisor allocates VF to virtual machines, providing DMA data mapping through hardware-assisted technologies such as IOMMU, allowing direct data transfer between virtual machines and physical devices.
Interrupts also need virtualization
Interrupt virtualization sounds strange; the core of interrupt virtualization is to allow virtual machines to receive and process interrupts like physical machines while being uniformly controlled by VMM to ensure stability in a multi-virtual machine environment.
Interrupts are signals sent from hardware to the CPU to notify it to handle urgent tasks (such as keyboard input, disk IO completion). Interrupt virtualization is the process by which VMM intercepts, forwards, and simulates these signals, allowing multiple virtual machines to share physical interrupt resources, preventing virtual machines from maliciously occupying interrupt resources or interfering with other virtual machines/physical machines. This is very similar to the message queue distribution mechanism.
Performance issues brought by virtualization
The core performance issue of virtualization technology is the additional overhead introduced by the virtualization layer, primarily affecting the efficiency of key resources such as CPU, IO, and memory.
CPU virtualization overhead: The privileged instructions of the virtual machine need to be intercepted and processed by VMM, and frequent switching between root mode and non-root mode consumes CPU resources. Early full virtualization had high overhead, but hardware-assisted virtualization (such as Intel VT-x, AMD-V) has significantly reduced this loss.
IO virtualization overhead: Disk and network IO must be forwarded or simulated by VMM, increasing the number of data copies (such as virtual machine → VMM → physical hardware), leading to increased IO latency and decreased throughput.
Memory virtualization overhead: VMM needs to maintain multi-level mappings from virtual addresses to physical addresses (such as shadow page tables), and the address translation process will increase latency; at the same time, memory paging and sharing mechanisms will also incur additional consumption.
Interrupt virtualization overhead: The capture, mapping, and forwarding processes of interrupts will produce latency, especially in high interrupt frequency scenarios (such as network-intensive tasks), where the overhead is more pronounced.
Optimization directions
Hardware-assisted optimization: Enable CPU features such as EPT (memory virtualization), VT-d/AMD-Vi (IO virtualization), etc., allowing hardware to handle some virtualization logic directly, reducing VMM intervention. Use paravirtualization instead of full simulation to reduce data copies. Adopt PCIe passthrough to directly allocate hardware to virtual machines, eliminating VMM forwarding overhead. Optimize virtual machine CPU scheduling algorithms to reduce resource contention between virtual machines. For scenarios with high real-time requirements, virtual machines can be bound to physical CPU cores.
In summary
Virtualization technology is a core technology for resource abstraction and isolation, constantly switching between the host and virtual machines, with performance losses being unavoidable. By abstracting physical hardware resources (such as CPU, memory, storage, network, etc.) into virtual resources, it achieves multi-environment isolation and operation. Hardware offloading optimization is the future direction of development.
