

The following content is organized from Zhihu:
Author: Wang Peng Link:https://www.zhihu.com/question/285202403/answer/444253962First, let me answer the question,
(1) There is a significant difference in performance compared to traditional chips, such as CPUs and GPUs. When executing AI algorithms, they are faster and more energy-efficient.
(2) There is no difference in manufacturing processes; everyone is the same. At least for now, they are all the same.
The so-called AI chips generally refer to ASICs (Application-Specific Integrated Circuits) designed for AI algorithms.
Traditional CPUs and GPUs can also execute AI algorithms, but they are slow, have low performance, and cannot be practically commercialized.
For example, autonomous driving requires recognizing road conditions, pedestrians, traffic lights, etc. However, if a current CPU is used for calculations, the car might end up in a river before realizing it is there, as speed is critical, and time is life. Using a GPU is indeed much faster, but it consumes a lot of power, and the car’s battery might not support normal usage for long. Additionally, GPUs from NVIDIA are very expensive, often costing over ten thousand for a single unit, which ordinary consumers cannot afford, and they are often out of stock. Moreover, since GPUs are not specifically developed as ASICs for AI algorithms, their speed has not yet reached its limit, leaving room for improvement. In fields like intelligent driving, speed is a must! On mobile devices, AI applications such as facial recognition and voice recognition must be low in power consumption, so GPUs are out!
Therefore, developing ASICs has become inevitable.
Let’s discuss why AI chips are needed.
AI algorithms commonly use CNN (Convolutional Neural Networks) in image recognition and RNN (Recurrent Neural Networks) in speech recognition and natural language processing. These are two different types of algorithms. However, they fundamentally involve matrix or vector multiplication and addition, along with some division, exponentiation, and other algorithms.
A mature AI algorithm like YOLO-V3 involves a large amount of convolution, residual networks, fully connected layers, etc., which essentially means multiplication and addition. For YOLO-V3, if the input image size is fixed, the total number of multiplication and addition calculations is determined, for example, a trillion times. (In reality, the situation is much larger.)
To execute YOLO-V3 quickly, it must complete a trillion multiplication and addition calculations.
At this point, let’s consider IBM’s POWER8, one of the most advanced servers using superscalar CPUs, operating at 4GHz with SIMD (Single Instruction, Multiple Data) and 128-bit architecture. Assuming it processes 16-bit data, that would be 8 numbers, meaning that in one cycle, it can perform a maximum of 8 multiply-accumulate calculations. In one cycle, it can perform a maximum of 16 operations. This is still theoretical and is unlikely to be achieved in practice.
Thus, the peak calculation frequency of the CPU per second = 16 x 4Gops = 64Gops.
Now, we can calculate the execution time for a CPU calculation.
Similarly, we can calculate the execution time for a GPU as well. However, since I am not very familiar with the internal structure of GPUs, I will not analyze it in detail.
Now let’s talk about AI chips, for example, the famous Google TPU1.
TPU1 operates at approximately 700MHz, with a 256×256 size array, as shown in the figure below. It has a total of 256×256 = 64K multiply-accumulate units, each capable of executing one multiplication and one addition at a time. This results in 128K operations (one for multiplication and one for addition).
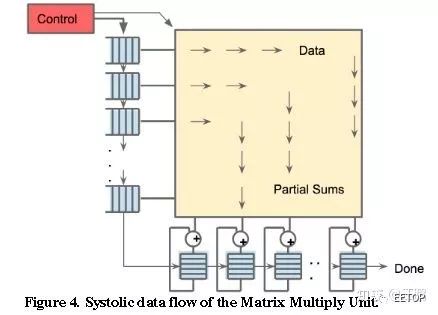
Additionally, besides the pulse array, there are other modules, such as activation functions, which also involve multiplication and addition.
So, the peak computation frequency of TPU1 is at least = 128K x 700MHz = 89600Gops = approximately 90Tops.
Comparing CPU and TPU1, we find several orders of magnitude difference in computational power, which is why CPUs are considered slow.
Of course, the above data are ideal theoretical values; in practice, it may only reach about 5%. This is because the storage on the chip is not large enough, so data is often stored in DRAM, and retrieving data from DRAM is slow. Therefore, the multiplication logic often has to wait. Additionally, AI algorithms consist of many layers of networks, which must be computed layer by layer. Thus, when switching layers, the multiplication logic is idle, leading to various factors that prevent the chip from reaching its peak computational performance, and the gap is significant.
Some may argue that research can tolerate slower speeds.
Currently, neural network sizes are increasing, and parameters are becoming more numerous. When faced with large NN models that take weeks or even months to train, would you have the patience to wait? What if there’s a sudden power outage, and everything has to start over? (I once trained an AI to write novels, and each training session (50 epochs) took about a day and a night. I remember if I started training in the morning, it might not finish until the next afternoon, and that was for a relatively simple model with only tens of thousands of data points.)
Modifying a model can take several weeks to determine its correctness; can you afford to wait?
Suddenly having a TPU makes it possible to return from lunch and find that the parameter optimization is done, and you can continue running—how enjoyable!
Fast computation speeds allow for rapid iteration, leading to the development of stronger AI models. Speed is money.
Since I am not familiar with the internal structure of GPUs, I won’t compare them. It is certain that GPUs are still relatively fast, at least much faster than CPUs, which is why most people currently use GPUs. However, each of these GPUs can easily cost over ten thousand, which is very expensive, and they consume a lot of power, often going out of stock. They are not suitable for large-scale use in data centers.
In summary, CPUs and GPUs are not AI-specific chips. To achieve other functionalities, they contain a lot of other logic that is completely unnecessary for current AI algorithms. This naturally leads to CPUs and GPUs not achieving optimal cost-performance ratios.
Google has invested in developing TPUs, and they have now released TPU3, which is being used quite happily. They have started supporting Google Cloud Computing Services, which costs about $6 per hour, if I remember correctly.
It is evident that Google finds it necessary to develop TPUs.
Currently, in fields such as image recognition, speech recognition, and natural language processing, the most accurate algorithms are based on deep learning. The computational accuracy of traditional machine learning has been surpassed. The most widely used algorithms today are likely deep learning algorithms. Additionally, traditional machine learning algorithms require far less computation than deep learning, which is why when I discuss AI chips, I refer specifically to deep learning algorithms that involve large computational loads. After all, for algorithms with smaller computational loads, CPUs are already quite fast. Moreover, CPUs are suitable for executing complex scheduling algorithms, which GPUs and AI chips cannot achieve. Therefore, these three types of chips are just aimed at different application scenarios, each having its own strengths.
As for why I used CPUs for comparison?
Instead of specifically mentioning GPUs, it is because, as I mentioned, I currently do not have a systematic understanding of GPU literature and am not familiar with the GPU situation, so I will not analyze it. Due to my accumulated experience, I am more familiar with superscalar CPUs, which is why I made a detailed comparison using CPUs. Additionally, small networks can be trained using CPUs without significant issues; it may just be a bit slower as long as the network model is not too large.
AI algorithm companies like SenseTime and Megvii have large models, and naturally, a single GPU cannot handle them. The computational power of GPUs is also quite limited.
As for saying that CPUs are serial and GPUs are parallel,
That’s correct, but it’s not comprehensive. Let me elaborate on the CPU being serial. The user likely does not have a very deep understanding of CPUs. The CPU I mentioned is IBM’s POWER8, which is a superscalar server CPU, currently one of the top performers, operating at a frequency of 4GHz. I wonder if they noticed that I mentioned it has SIMD capabilities? This SIMD means it can execute multiple instructions simultaneously, which is parallelism, not serial. A single data point is 128 bits, and if the precision is 16 bits, then theoretically, in one cycle, it can calculate a maximum of eight groups of multiplications or additions, or multiply-accumulate operations. Isn’t that parallelism? It’s just that the degree of parallelism is not as powerful as that of GPUs, but it is still parallelism.
I don’t understand why CPUs cannot be used for comparison of computational power?
Some comments highly praise GPUs, saying it is inappropriate to compare them with CPUs.
Please, GPUs were originally separated from CPUs to handle image computations, which means GPUs are specialized for image processing. This includes rendering various visual effects. This is also a fundamental flaw of GPUs, as they are more suited for rendering and similar computational algorithms. However, these algorithms are still quite different from deep learning algorithms. The AI chips I mentioned, like TPUs, are specifically developed for typical deep learning algorithms such as CNNs. Additionally, Cambricon’s NPUs are also specifically designed for neural networks, similar to TPUs.
When Google’s TPU and Cambricon’s DianNao were first introduced, they were compared to CPUs and GPUs.
Take a look at the abstract of Google TPU papers, which directly compare TPU1 with CPU/GPU performance results, as shown in the red box:


This is the performance comparison of TPU1 with CPU/GPU introduced in the abstract.
Now let’s take a look at Cambricon’s DianNao paper, which directly compares DianNao’s performance with that of CPUs in the abstract, as shown in the red box:

Let’s review the history
When neural networks first appeared in the last century, they were calculated using CPUs.
When Bitcoin first emerged, it was also mined using CPUs. Now it has evolved into ASIC mining machines. You can look into Bitmain.
Since 2006, the deep learning craze began, and both CPUs and GPUs could compute. It was found that GPUs were faster but more expensive, so CPUs were still more commonly used, especially since GPU CUDA was not very advanced at that time. Later, as NN models grew larger, the advantages of GPUs became increasingly evident, and CUDA became more powerful, leading to the current dominance of GPUs.
Cambricon’s DianNao (NPU) released in 2014 was faster than CPUs and also more energy-efficient. The advantages of ASICs are evident, which is why ASICs are being developed.
As for why many companies’ solutions are programmable, most of them work with FPGAs. Are you referring to SenseTime or DeepMind? Indeed, the papers they published are based on FPGAs.
These startups primarily focus on algorithms; the chips are not their main focus, and they currently lack the energy and strength to develop them. FPGAs are very flexible, cost-effective, and can quickly prototype architectural designs, so they naturally choose FPGA-based solutions. However, recently they have been heavily financing and recruiting for chip design positions, so they are likely starting to delve into ASIC development.
If FPGA-based programmable solutions really had enormous commercial value, why would they invest so much in ASICs?
I have said a lot; I am also a latecomer, learning out of work necessity. According to my current understanding, by examining TPU1’s patents and papers, deriving its internal design methods step by step, I have understood most of what is called AI processors. Then, studying a series of papers from Cambricon, which has several different architectures for different situations, could be interesting to research. Then there are other unicorns like SenseTime and DeepMind, which publish papers every year that are worth reading. These papers likely represent the most advanced AI chip architecture designs currently available. Of course, the most advanced designs are not disclosed, as Google has never made the patents related to TPU2 and TPU3 public, and I haven’t found any. However, the current literature already represents the most advanced progress in recent years.
Author: Bluebear
Link:https://www.zhihu.com/question/285202403/answer/444457305
The AI chips currently discussed can be divided into two categories: one is aimed at both training and inference, which can be handled by GPGPU, CPUs, and FPGAs (such as Altera’s Stratix series), but Google’s TPU2 and Bitmain’s Sophon, due to their specialized design, may have advantages in energy efficiency. This type of product is relatively few but more interesting. Of course, ICLR has also explored works that use fixed-point devices for training; Xilinx hopes that XNOR-net allows fixed-point devices to participate in training.
The other category is Inference Accelerator chips, which simply means running pre-trained models on chips. This area is indeed flourishing, such as Cambricon’s NPU, Intel Movidius (and also a Nervana that should be similar to Xeon Phi for training), DeepMind’s DPU, Horizon’s BPU, Imagination’s PowerVR 2NX, ARM’s Project Trillium, and many more IPs. These products not only exist as products but also provide IPs for other developers to integrate deep learning accelerators into SoCs. Additionally, Tegra X2 is a product that resembles a small desktop platform, with an ARM processor and Nvidia GPU providing complete training and inference capabilities, though it also has high power consumption. Other accelerator chips vary significantly; Intel Movidius was released earlier, supporting floating-point inference, and it actually contains VLIW SIMD units, which are similar to previous ATi graphics cards or DSP designs. Other than that, I have seen little public information, so I will just speculate that AI accelerators are mainly optimized for existing networks, performing fixed-point or floating-point calculations, primarily stacking computational units (matrix computation units, multiply-accumulate), and then reducing memory data movement. The 970 may be hung on the CCI, relying on a large cache, while PowerVR 2NX seems to optimize to a 4-bit memory controller. By optimizing memory data pathways, it reduces some memory bandwidth requirements, which are all interrelated. This kind of thing feels close to a super multi-core DSP, but it is simplified since DSPs can still do some control tasks.
Moreover, to some extent, they are poorly optimized for new networks. Generally, industry lags behind academia by more than a year. For example, when DenseNet came out, chips only supported ResNet.
Regarding the following two questions:
If GPGPU or CPU performs inference, the energy consumption ratio will certainly not look good, but floating-point inference is generally more accurate than fixed-point or reduced precision (though there are cases where fixed-point generalization is good). However, if the NPU can only perform specific tasks under CPU control, it becomes quite embarrassing; without many application supports, the NPU is quite useless. On mobile devices, you often do not need an NPU, so I think it’s sufficient to use Mali or similar.
There is no difference; they use the same process as other mobile SoCs and graphics cards. If you have the money, you can upgrade to a new process and technology.
Author: DeepTech
Link:https://www.zhihu.com/question/285202403/answer/446703288
What exactly can artificial intelligence bring to our lives? Taking our most familiar mobile phones as an example, daily beauty selfies have become commonplace. However, the current selfie software requires uploading to the cloud after shooting, using a general model to complete “one-click beautification.” Meanwhile, mobile AI chips can synchronize beautification of photos based on user preferences right after (or even before) the shooting stage, which is something current CPUs cannot accomplish.
So what are the differences between the two? First, traditional chips only need to call the corresponding system for work based on instructions during computation, while AI instructions contain a large amount of parallel computing and modeling. This undoubtedly places high demands on the processor’s computing power.
Secondly, there is the data collection capability of mobile devices, especially smartphones. Excellent AI applications need to collect vast amounts of data to train models, and smartphones are undoubtedly the best data collection tools. With more sensors such as microphones, cameras, gravity sensors, and positioning devices being added to smartphones, an “artificial intelligence” chip capable of real-time data collection, synchronous processing, and coordinating different sensors becomes increasingly important.
Of course, an AI chip that integrates over 5.5 billion transistors in an area the size of a fingernail cannot be used solely for simple photography. Currently, smartphones already have intelligent applications such as voice services, machine vision recognition, and image processing, and in the future, there will be more diverse applications, including medical, AR, gaming AI, and more.
In addition to satisfying applications on mobile phones, AI chips will also have the opportunity to expand into other more potential markets. A typical example is autonomous driving; Tesla hired AMD’s legendary architect Jim Keller last year to develop its own AI chip. Even in the future, from rockets and spacecraft to deep-sea explorers, the control systems relying on chips will increasingly become AI-driven.


E课网(www.eecourse.com) is a professional integrated circuit education platform under Moore Elite, dedicated to cultivating high-quality professional talent in the semiconductor industry for six years. The platform is oriented towards the job requirements of integrated circuit companies, providing a practical training platform that aligns with the corporate environment, rapidly training students to meet corporate needs.
E课网 has a mature training platform, a complete curriculum system, and strong teaching resources, planning a high-quality semiconductor course system of 168 courses, covering the entire integrated circuit industry chain, with four offline training bases. So far, it has deeply trained a total of 15,367 people, directly supplying 4,476 professional talents to the industry. It has established deep cooperative relationships with 143 universities and has held 240 special IC training sessions for enterprises.