1. Why Use FPGA?
As we all know, the Moore’s Law for general-purpose processors (CPU) has entered its twilight, while the scale of machine learning and web services is growing exponentially.
People are using custom hardware to accelerate common computing tasks, but the rapidly changing industry demands that this custom hardware be reprogrammable to perform new types of computing tasks.
FPGA is a type of hardware reconfigurable architecture. Its full English name is Field Programmable Gate Array.
For many years, FPGAs have been used as a small-batch alternative to Application-Specific Integrated Circuits (ASICs), but in recent years, they have been deployed at scale in data centers of companies like Microsoft and Baidu to provide both powerful computing capabilities and sufficient flexibility.
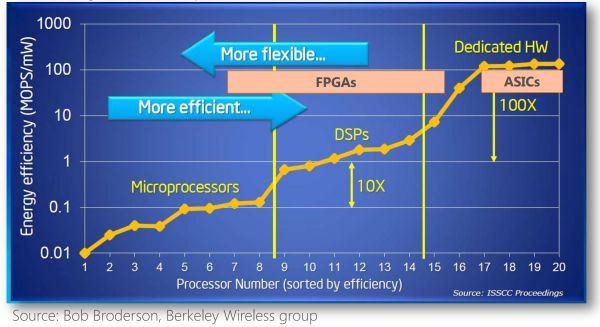
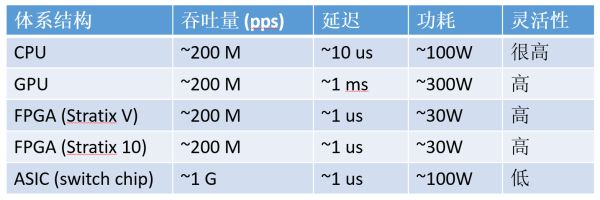
Comparison of Performance and Flexibility of Different Architectures
Why is FPGA fast? “It’s all about the good company it keeps.”
CPU and GPU belong to the von Neumann architecture, which means instruction decoding execution and shared memory. The reason FPGA is more energy-efficient than CPU or even GPU is fundamentally due to its architecture that is instruction-free and does not require shared memory.
In the von Neumann architecture, since execution units (like CPU cores) can execute arbitrary instructions, there is a need for instruction memory, decoders, various instruction arithmetic units, and branch jump processing logic. Due to the complexity of the control logic for the instruction flow, there cannot be too many independent instruction streams, so GPUs use SIMD (Single Instruction, Multiple Data) to allow multiple execution units to process different data in sync, and CPUs also support SIMD instructions.
However, the function of each logic unit in FPGA is determined at the time of reprogramming (burning), and it does not need instructions.
In the von Neumann architecture, memory serves two purposes: one is to save state, and the other is to communicate between execution units.
Since the memory is shared, access arbitration is required; to utilize access locality, each execution unit has a private cache, which requires maintaining cache consistency between execution components.
For the need to save state, registers and on-chip memory (BRAM) in FPGA belong to their respective control logic, eliminating unnecessary arbitration and caching.
For communication needs, the connections between each logic unit in FPGA are determined at the time of reprogramming (burning) and do not require communication through shared memory.
After discussing these high-level concepts, how does FPGA actually perform? Let’s look at examples of compute-intensive tasks and communication-intensive tasks.
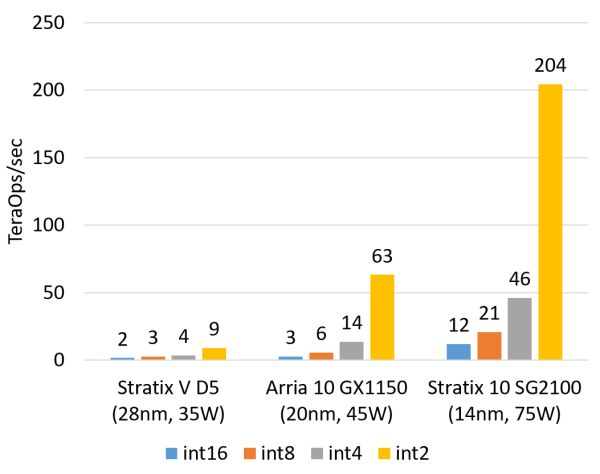
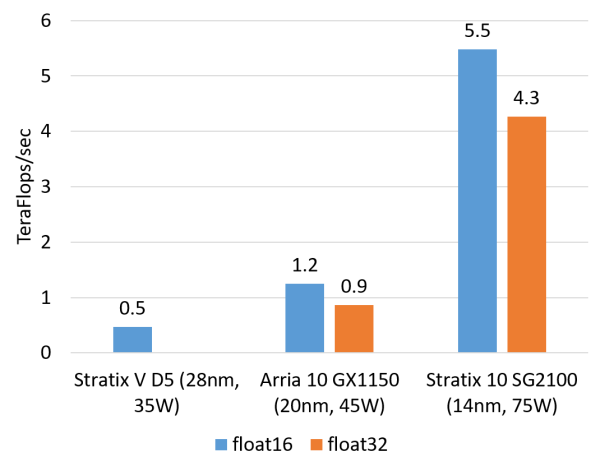
Examples of compute-intensive tasks include matrix operations, image processing, machine learning, compression, asymmetric encryption, and sorting in Bing search. For these tasks, CPUs typically offload the work to FPGAs. Currently, the integer multiplication performance of the Altera (which should be called Intel now, but I still prefer to call it Altera…) Stratix V FPGA is roughly equal to that of a 20-core CPU, and its floating-point multiplication performance is comparable to that of an 8-core CPU, but it is an order of magnitude lower than that of GPUs. The next generation FPGA, Stratix 10, which we are about to use, will be equipped with more multipliers and hardware floating-point units, theoretically achieving computing capabilities comparable to the current top GPU compute cards.
Estimated integer multiplication capability of FPGA (not using DSP, estimated based on logic resource occupancy).
Estimated floating-point multiplication capability of FPGA (float16 using soft core, float32 using hard core).
In data centers, the core advantage of FPGA over GPU is latency.
For tasks like Bing search sorting, to return search results as quickly as possible, you need to minimize the latency at each step.
If you use a GPU to accelerate, to fully utilize its computing capabilities, the batch size cannot be too small, and the latency can reach the millisecond level.
Using FPGA for acceleration only requires microsecond-level PCIe latency (our current FPGA is used as a PCIe acceleration card).
In the future, after Intel launches the Xeon + FPGA connected via QPI, the latency between CPU and FPGA can be reduced to below 100 nanoseconds, making it almost indistinguishable from accessing main memory.
Why is FPGA’s latency much lower than that of GPU?
This is fundamentally due to the architectural differences.
FPGA has both pipeline parallelism and data parallelism, while GPU has almost only data parallelism (pipeline depth is limited).
For example, processing a data packet involves 10 steps; FPGA can build a 10-stage pipeline where different stages process different data packets, and once a packet has passed through all 10 stages, it is completed. Each time a packet is completed, it can be output immediately.
On the other hand, the GPU’s data-parallel method involves 10 computing units, each processing different packets, but all must operate in unison, doing the same thing (SIMD, Single Instruction Multiple Data). This requires that 10 packets must be input and output together, increasing the input-output latency.
When tasks arrive one by one rather than in batches, pipeline parallelism achieves lower latency than data parallelism. Therefore, for streaming computing tasks, FPGA inherently has an advantage in terms of latency over GPU.
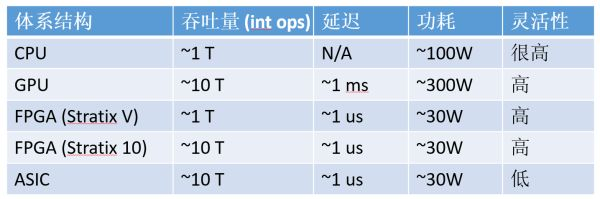
Comparison of orders of magnitude for compute-intensive tasks: CPU, GPU, FPGA, and ASIC (using 16-bit integer multiplication as an example, numbers are only estimates of orders of magnitude).
ASIC chips are impeccable in terms of throughput, latency, and power consumption, but Microsoft has not adopted them for two reasons:
-
Computing tasks in data centers are flexible and variable, while the R&D cost and cycle for ASICs are high. After deploying a batch of acceleration cards for a certain neural network, if another neural network becomes more popular, the investment is wasted. FPGAs can update their logic functions in just a few hundred milliseconds. The flexibility of FPGA can protect investments; in fact, Microsoft’s current usage of FPGA is very different from the original concept.
-
Data centers are rented out to different tenants; if some machines have neural network acceleration cards, some have Bing search acceleration cards, and others have network virtualization acceleration cards, task scheduling and server maintenance become complicated. Using FPGA can maintain the homogeneity of the data center.
Next, let’s look at communication-intensive tasks.
Compared to compute-intensive tasks, communication-intensive tasks involve less complex processing for each input data, usually just simple calculations for output, and communication often becomes the bottleneck. Symmetric encryption, firewalls, and network virtualization are examples of communication-intensive tasks.
Comparison of orders of magnitude for communication-intensive tasks: CPU, GPU, FPGA, and ASIC (using 64-byte network packet processing as an example, numbers are only estimates of orders of magnitude).
For communication-intensive tasks, FPGA has even greater advantages over CPU and GPU.
In terms of throughput, FPGAs can connect directly to 40 Gbps or even 100 Gbps network cables, processing packets of any size at line speed; while CPUs need to receive packets from network cards to process, many network cards cannot process 64-byte small packets at line speed. Although multiple network cards can be installed to achieve high performance, the number of PCIe slots supported by CPUs and motherboards is often limited, and network cards and switches themselves are also quite expensive.
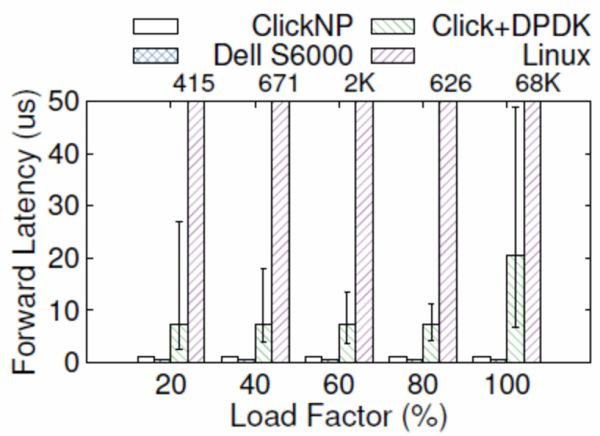
In terms of latency, when a network card receives a packet to the CPU and then sends it back to the network card, even using high-performance packet processing frameworks like DPDK, the latency is still around 4-5 microseconds. A more serious issue is that the latency of general-purpose CPUs is not stable. For example, under high load, forwarding latency can rise to tens of microseconds or even higher (as shown in the figure below); clock interrupts and task scheduling in modern operating systems also increase the uncertainty of latency.
Comparison of forwarding latencies between ClickNP (FPGA), Dell S6000 switch (commercial switch chip), Click+DPDK (CPU), and Linux (CPU), with error bars indicating 5% and 95%.
While GPUs can also process packets at high performance, they lack network ports, meaning packets must first be received from network cards before being processed by GPUs. This limits throughput to that of the CPU and/or network card. The latency of GPUs is even worse.
So why not implement these network functions in network cards or use programmable switches? The inflexibility of ASIC remains a drawback.
Although there are increasingly powerful programmable switch chips, such as Tofino that supports P4 language, ASICs still cannot perform complex stateful processing, such as certain custom encryption algorithms.
In summary, the main advantages of FPGA in data centers are stable and extremely low latency, suitable for both streaming compute-intensive tasks and communication-intensive tasks.
2. Microsoft’s Practice of Deploying FPGA
In September 2016, Wired magazine published an article titled “Microsoft Bets Its Future on FPGA”, detailing the past and present of the Catapult project.
Shortly thereafter, Doug Burger, the head of the Catapult project, demonstrated FPGA-accelerated machine translation at the Ignite 2016 conference alongside Microsoft CEO Satya Nadella.
The total computing power of the demonstration was 1.03 million T ops, equivalent to 100,000 top GPU compute cards. A single FPGA (along with on-board memory and network interfaces) consumes about 30 W, only increasing the overall server power consumption by one-tenth.
Demonstration at Ignite 2016: Machine translation computing power of 1 Exa-op (10^18) per second.
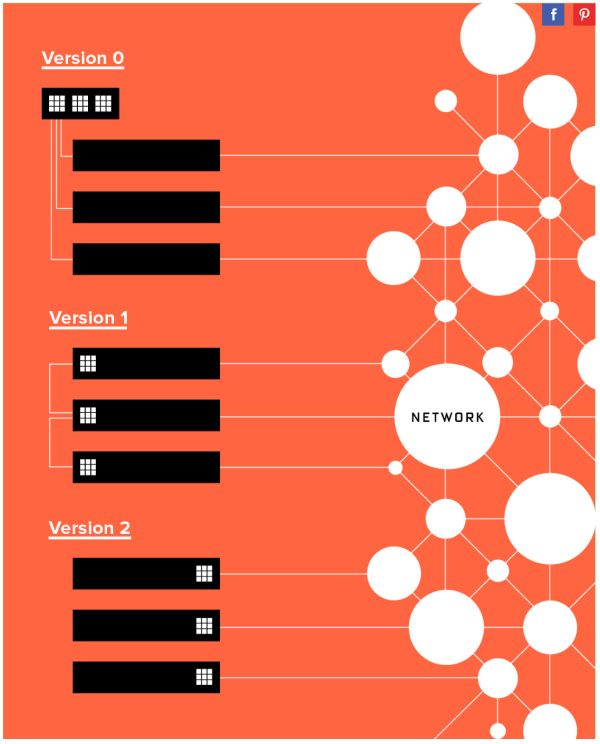
Microsoft’s deployment of FPGA has not been smooth. Regarding where to deploy FPGA, it has roughly gone through three stages:
-
Dedicated FPGA clusters filled with FPGAs.
-
One FPGA per machine, using dedicated network connections.
-
One FPGA per machine, placed between the network card and the switch, sharing the server network.
Three stages of Microsoft’s FPGA deployment approach.
The first stage involved dedicated clusters filled with FPGA acceleration cards, resembling a supercomputer made entirely of FPGAs.
The following image shows the earliest BFB experimental board, which housed 6 FPGAs on a single PCIe card, with 4 PCIe cards plugged into each 1U server.
The earliest BFB experimental board, which housed 6 FPGAs.
It is worth noting the name of the company involved. In the semiconductor industry, as long as the volume is sufficient, the price of chips will tend to the price of sand. It is rumored that it was precisely because this company refused to offer “sand prices” that another company was chosen.
Of course, now both companies’ FPGAs are used in the data center field. As long as the scale is large enough, concerns about FPGA prices being too high become unnecessary.
The earliest BFB experimental board, with 4 FPGA cards plugged into a 1U server.
Deployment like a supercomputer means that there is a dedicated cabinet filled with servers like the one shown above, each containing 24 FPGAs (left image below).
This approach has several issues:
-
FPGAs in different machines cannot communicate, limiting the scale of problems that FPGAs can handle to the number of FPGAs within a single server;
-
Other machines in the data center must concentrate tasks to this cabinet, forming in-cast, making it difficult to stabilize network latency.
-
FPGA dedicated cabinets create single points of failure; if one fails, no one can accelerate.
-
Servers equipped with FPGAs are custom-built, increasing cooling and maintenance difficulties.
Three methods of deploying FPGA, from centralized to distributed.
A less aggressive approach is to deploy a server filled with FPGAs in each cabinet (as shown in the image above). This avoids issues (2) and (3), but (1) and (4) remain unresolved.
The second stage aimed to ensure the homogeneity of servers in the data center (which is also an important reason for not using ASICs) by inserting one FPGA into each server (right image above), with FPGAs connected via dedicated networks. This was also the deployment method published by Microsoft at ISCA’14.
Open Compute Server in a rack.
Interior view of Open Compute Server. The red box indicates the location for FPGA.
Connection and fixing between FPGA and Open Compute Server.
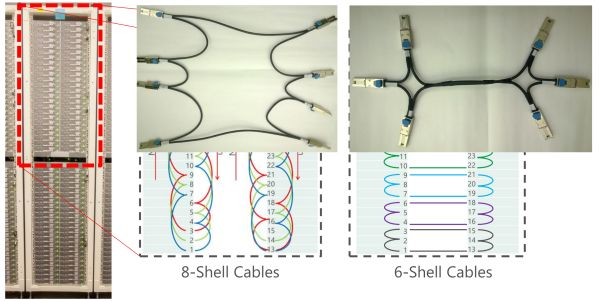
FPGA uses Stratix V D5, with 172K ALM, 2014 M20K on-chip memory, and 1590 DSPs. The board has an 8GB DDR3-1333 memory, a PCIe Gen3 x8 interface, and two 10 Gbps network interfaces. FPGAs between cabinets are connected via dedicated networks, with a group of 10G ports connected in a ring of 8, and another group of 10G ports connected in a ring of 6, without using switches.
Network connection method between FPGAs in a cabinet.
This cluster of 1632 servers and 1632 FPGAs has doubled the overall performance of Bing’s search result sorting (in other words, halving the number of servers).
As shown in the figure below, each group of 8 FPGAs is linked in a chain, with the aforementioned 10 Gbps dedicated network cable used for communication. Each of these 8 FPGAs has specific roles: some are responsible for feature extraction from documents (yellow), some for calculating feature expressions (green), and some for scoring documents (red).
FPGA accelerates the process of Bing’s search sorting.
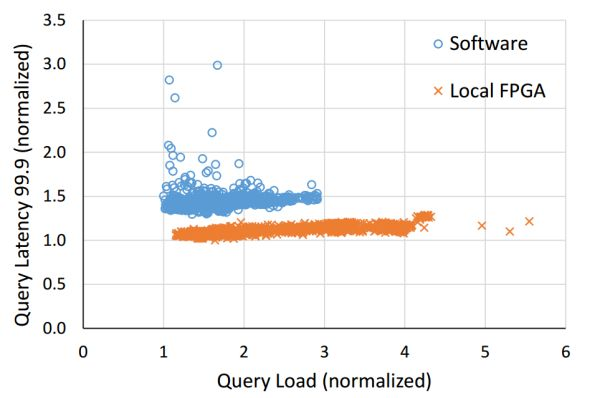
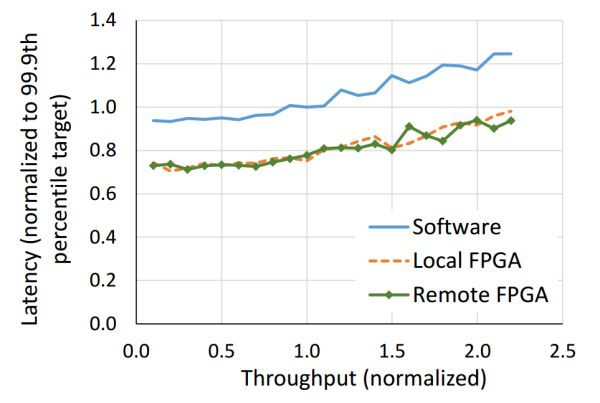
Both local and remote FPGAs can reduce search latency, with the communication latency of remote FPGAs being negligible compared to search latency.
The deployment of FPGA in Bing has been successful, and the Catapult project continues to expand within the company.
Microsoft’s Azure department has the most servers internally.
The urgent problem the Azure department needs to solve is the overhead brought by network and storage virtualization. Azure sells virtual machines to customers, requiring firewall, load balancing, tunneling, NAT, and other network functionalities for the virtual machines. Since the physical storage of cloud storage is separated from the computing nodes, data must be moved from the storage nodes through the network, requiring compression and encryption.
In the era of 1 Gbps networks and mechanical hard drives, the CPU overhead for network and storage virtualization was negligible. As network and storage speeds increase, reaching 40 Gbps for networks and 1 GB/s for SSDs, the CPU is gradually becoming overwhelmed.
For instance, the Hyper-V virtual switch can only handle around 25 Gbps of traffic and cannot achieve 40 Gbps line speed, performing even worse when packet sizes are small; AES-256 encryption and SHA-1 signing can only be processed at 100 MB/s per CPU core, which is only one-tenth of an SSD’s throughput.

Number of CPU cores required to process network tunneling protocols and firewall handling at 40 Gbps.
To accelerate network functions and storage virtualization, Microsoft has deployed FPGAs between network cards and switches.
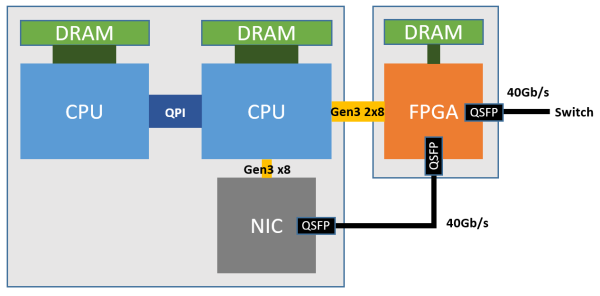
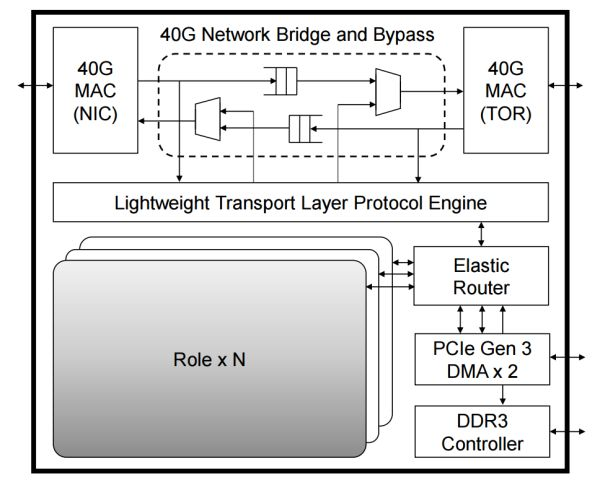
As shown in the figure below, each FPGA has a 4 GB DDR3-1333 DRAM, connected to a CPU socket via two PCIe Gen3 x8 interfaces (physically a PCIe Gen3 x16 interface, as the FPGA does not have a x16 hard core, logically treated as two x8). The physical network card (NIC) is a standard 40 Gbps network card, used solely for communication between the host and the network.
Architecture of Azure servers deploying FPGA.
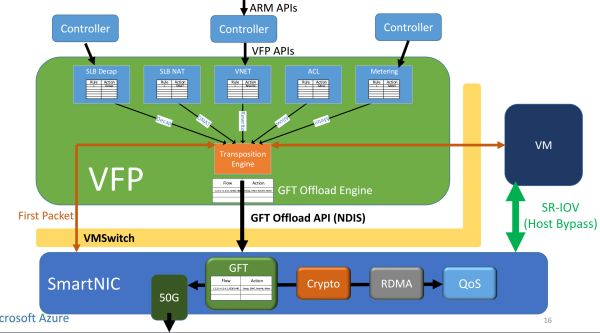
FPGA (SmartNIC) virtualizes a network card for each virtual machine, allowing VMs to directly access this virtual network card through SR-IOV. The data plane functions that were originally in the virtual switch have been moved to the FPGA, allowing virtual machines to send and receive network packets without CPU involvement or passing through the physical network card (NIC). This not only saves CPU resources available for sale but also improves the network performance of virtual machines (25 Gbps), reducing the network latency between virtual machines in the same data center by tenfold.
Accelerated architecture for network virtualization.
This is the third-generation architecture for Microsoft’s FPGA deployment, currently adopted for large-scale deployment of “one FPGA per server”.
The initial intention of reusing host networks with FPGA is to accelerate networking and storage, but its far-reaching impact is that it expands the network connections between FPGAs to a cloud-scale, creating a true “supercomputer”.
In the second-generation architecture, the network connections between FPGAs were limited to within the same rack, making it difficult to scale up the dedicated network interconnection method between FPGAs, while forwarding through CPUs incurs too high overhead.
In the third-generation architecture, FPGAs communicate via LTL (Lightweight Transport Layer). Latency within the same rack is under 3 microseconds; within 8 microseconds, it can reach 1000 FPGAs; within 20 microseconds, it can reach all FPGAs in the same data center. Although the second-generation architecture has lower latency within 8 machines, it can only access 48 FPGAs through the network. To support extensive communication between FPGAs, the LTL in the third-generation architecture also supports PFC flow control protocol and DCQCN congestion control protocol.
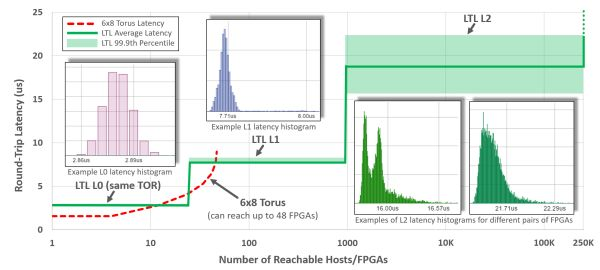
Vertical axis: LTL latency, horizontal axis: reachable number of FPGAs.
Logical module relationships within FPGA, where each Role represents user logic (such as DNN acceleration, network function acceleration, encryption), and the outer part is responsible for communication between various Roles and between Roles and peripherals.
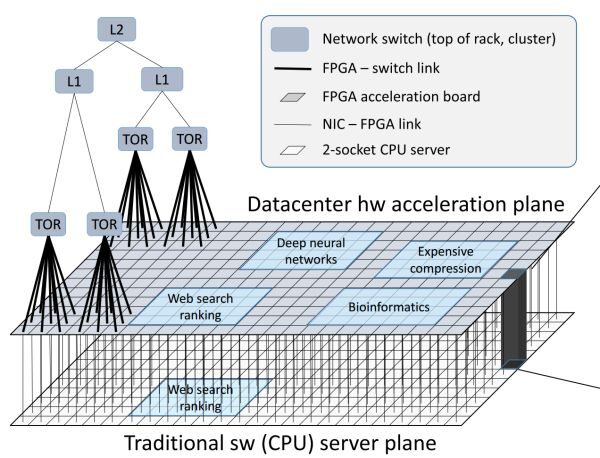
FPGA constitutes the data center acceleration plane, situated between the network switching layer (TOR, L1, L2) and traditional server software (software running on CPU).
Through high-bandwidth, low-latency networks interconnecting FPGAs, a data center acceleration plane is formed between the network switching layer and traditional server software.
In addition to the acceleration of network and storage virtualization required by every server providing cloud services, the remaining resources on FPGA can also be used to accelerate tasks like Bing search and deep neural networks (DNN).
For many types of applications, as the scale of distributed FPGA accelerators increases, their performance enhancement is superlinear.
For example, in CNN inference, when using only one FPGA, the on-chip memory may not be sufficient to hold the entire model, necessitating constant access to model weights in DRAM, creating a performance bottleneck. If the number of FPGAs is sufficient, each FPGA can be responsible for one layer or several features within a layer, allowing the model weights to be fully loaded into on-chip memory, eliminating the DRAM performance bottleneck and fully utilizing the performance of FPGA computing units.
Of course, overly fine-grained segmentation can lead to increased communication overhead. Balancing computation and communication is key when partitioning tasks across distributed FPGA clusters.
From neural network models to HaaS on FPGA. By leveraging the parallelism within the model, different layers and features of the model are mapped to different FPGAs.
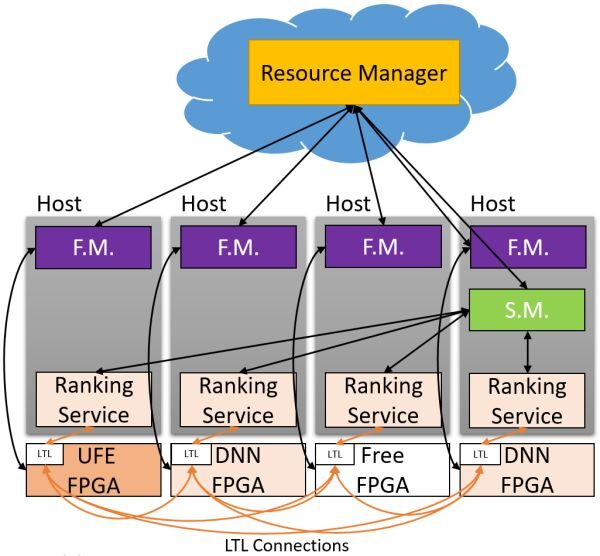
At the MICRO’16 conference, Microsoft proposed the concept of Hardware as a Service (HaaS), which allows hardware to be treated as a schedulable cloud service, enabling centralized scheduling, management, and large-scale deployment of FPGA services.
Hardware as a Service (HaaS).
From the first generation of dedicated servers filled with FPGAs, to the second generation of FPGA acceleration card clusters connected via dedicated networks, to the current large-scale FPGA cloud that reuses data center networks, three guiding principles have shaped our trajectory:
-
Hardware and software are not in a substitutive relationship but rather a cooperative one;
-
Flexibility is essential, meaning the ability to be software-defined;
-
Scalability must be ensured.
3. The Role of FPGA in Cloud Computing
-
What role should FPGA play in large-scale network interconnection systems?
-
How to efficiently and scalably program heterogeneous systems of FPGA + CPU?
My main regret regarding FPGA in the industry is that the mainstream usage of FPGA in data centers, from internet giants other than Microsoft to the two major FPGA manufacturers and academia, mostly treats FPGA as a computing accelerator for compute-intensive tasks like GPUs. But is FPGA really suitable for doing what GPUs do?
As mentioned earlier, the biggest difference between FPGA and GPU lies in their architecture; FPGA is more suitable for low-latency streaming processing, while GPU is better for processing large volumes of homogeneous data.
Since many people intend to use FPGA as a computing accelerator, the high-level programming models launched by the two major FPGA manufacturers are also based on OpenCL, mimicking the batch processing model based on shared memory used by GPUs. When a CPU assigns a task to an FPGA, it first has to load data into the DRAM on the FPGA board, then tell the FPGA to start executing, and finally, the FPGA puts the execution results back into DRAM, notifying the CPU to retrieve them.
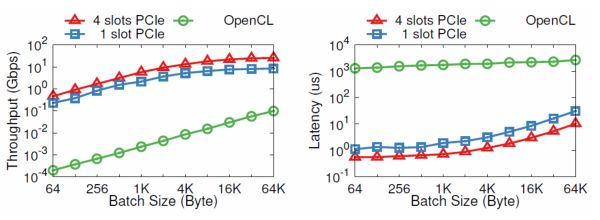
Why take the long route through the DRAM on the board when there could be efficient communication between CPU and FPGA via PCIe? Perhaps due to engineering implementation issues, we find that writing to DRAM, starting the kernel, and reading from DRAM through OpenCL takes 1.8 milliseconds. However, communicating via PCIe DMA only takes 1-2 microseconds.
Comparison of performance between PCIe I/O channel and OpenCL. The vertical axis is on a logarithmic scale.
Communication between multiple kernels in OpenCL is even more exaggerated, as the default method is also through shared memory.
This article begins by stating that FPGA is more energy-efficient than CPU and GPU, with the fundamental architectural advantage being that it is instruction-free and does not require shared memory. Using shared memory for communication between multiple kernels is unnecessary in sequential communication (FIFO). Moreover, DRAM on FPGA is generally much slower than DRAM on GPU.
Therefore, we propose the ClickNP network programming framework, which uses channels instead of shared memory for communication between execution units (elements/kernels) and between execution units and host software.
Applications that require shared memory can also be implemented on top of the channel framework; after all, CSP (Communicating Sequential Process) and shared memory are theoretically equivalent. ClickNP is still a framework based on OpenCL, constrained by the limitations of using C language to describe hardware (though HLS is indeed much more efficient than Verilog). The ideal hardware description language is probably not C.
ClickNP uses channels for communication between elements.
ClickNP uses channels for communication between FPGA and CPU.
Low-latency streaming processing requires maximum communication efficiency.
However, due to the limitations of parallelism and operating system scheduling, CPUs are not very efficient at communication and have unstable latency.
Additionally, communication inevitably involves scheduling and arbitration, and due to the limitations of single-core performance and low efficiency of inter-core communication in CPUs, the performance of scheduling and arbitration is constrained. Therefore, my doctoral research defines FPGA as the “big steward” of communication, capable of accelerating communication between servers, between virtual machines, between processes, and between CPUs and storage devices.
Success and failure both hinge on the same point. The lack of instructions is both an advantage and a weakness of FPGA.
Every time a different task is performed, a certain amount of FPGA logic resources must be occupied. If the tasks are complex and not highly repetitive, they will occupy a large amount of logic resources, most of which will remain idle. In such cases, it may be more efficient to use a von Neumann architecture processor.
Many tasks in data centers have strong locality and repetitiveness: some are related to network and storage tasks that need to be handled by virtualization platforms, while others are customer computing tasks, such as machine learning and encryption/decryption.
First, use FPGA for what it does best: communication. In the future, it may also rent out FPGA as computing accelerator cards like AWS.
Regardless of whether it’s communication or machine learning, encryption, and decryption, the algorithms are quite complex. If one tries to completely replace CPU with FPGA, it will inevitably lead to a tremendous waste of FPGA logic resources and increase the development costs of FPGA programs. A more practical approach is to have FPGA and CPU work together, with FPGA handling tasks that have strong locality and repetitiveness, while complex tasks are left to the CPU.
As we accelerate more services like Bing search and deep learning with FPGA; as the data plane for foundational components like network virtualization and storage virtualization is dominated by FPGA; as the “data center acceleration plane” composed of FPGAs becomes a barrier between networks and servers… it seems that FPGA will take control, while computing tasks on CPU become fragmented, driven by FPGA. In the past, we mainly relied on CPU, offloading repetitive computing tasks to FPGA; will it change in the future to FPGA taking the lead, offloading complex computing tasks to CPU? With the advent of Xeon + FPGA, will the ancient SoC experience a renaissance in the data center?