 Cover Image: nice view|Source: Hailey
Cover Image: nice view|Source: Hailey
I enjoy learning with “questions and curiosity”, which helps to systematize and solidify knowledge rather than just accumulating information. Follow this series of articles to explore 11 questions, which will greatly assist you in familiarizing yourself with Agent and Multi-agent technology. The next article will discuss the industry applications of these two technologies, representative companies, the latest product applications, and the pros and cons of implementation. Stay tuned.
1 Question List
Here is a list of questions for easy navigation to topics of interest.
- 1.What is the difference between Agent and LLM, and what kind of architecture can be called an Agent?
- 2.What core components are typically included in Agent architecture? What is the main function of each component?
- 3.What are the differences between the three Agent thinking frameworks: ReAct, Reflexion, and ToT (Tree of Thoughts)? What types of problems are they each suited to solve?
- 4.In a Multi-agent system, what is “emergent capability”? Please provide examples of how this capability manifests in practical applications.
- 5.What key issues should be noted when implementing Function calling? How can we effectively prevent hallucinations and parameter errors?
- 6.What are the technical characteristics and applicable scenarios of mainstream Agent frameworks (such as AutoGen, LangChain, CrewAI, etc.)?
- 7.When building an Agent based on Retrieval-Augmented Generation (RAG), how can we address knowledge conflicts and outdated information?
- 8.In a Multi-Agent System (MAS), how can we design effective Agent collaboration mechanisms? Discuss the design differences between homogeneous and heterogeneous Agent systems.
- 9.Memory management for Agents is crucial. Discuss the implementation methods and limitations of long-term and short-term memory in Agent systems.
- 10.How to evaluate (evals) the performance and effectiveness of Multi-agent systems? What are the limitations of existing evaluation metrics?
- 11.Anthropic’s recommendations for building Effective Agents
2 Basic Theory
2.1 What is the difference between Agent and LLM, and what kind of architecture can be called an Agent?
LLM is essentially a complex “input-output” system that can only generate text in response to user commands.
Agents add four key capabilities on top of LLM

- Decision-making: autonomously decide the next action based on goals
- Tools: can call external tools such as search engines, calculators, APIs
- Memory: save and utilize historical dialogue information
- Planning: decompose complex tasks and formulate execution plans
When can an AI system be called an Agent?
- Has a clear goal or intention
- Can perceive the environment to obtain information
- Can make decisions and take actions
- Has a certain degree of autonomy, not requiring human guidance for every step
- Ideally, can learn and adapt
2.2 What core components are typically included in Agent architecture? What is the main function of each component?
- Perception Module: collects and processes information from the environment, such as user input, reading documents, and obtaining web data.
- Cognitive Core: understands information and performs reasoning, usually handled by LLM, responsible for understanding tasks, generating plans, and making decisions.
- Memory System: stores historical information, including short-term memory (current session) and long-term memory (across sessions), typically implemented using vector databases, graph databases.
- Tool Repository: extends the external toolset, such as search engines, code executors, calculators, etc., called through mechanisms like function calling.
- Action Engine: translates cognitive decisions into actual actions, including calling APIs, generating content, controlling devices, etc.
- Self-evaluation: monitors and evaluates its own performance, checks whether the action results meet expectations, learns and improves future actions.
2.3 What are the differences between the three Agent thinking frameworks: ReAct, Reflexion, and ToT (Tree of Thoughts)? What types of problems are they each suited to solve?
- ReAct adds a “think-act” loop framework on top of LLM, suitable for tasks that require interaction with the environment (information retrieval and fact-checking) and multi-step problem-solving.
- Reflexion adds self-reflection and experiential learning capabilities on top of ReAct, suitable for tasks that require multiple attempts to improve and have clear success criteria.
- ToT focuses on exploring multiple approaches, suitable for tasks with various possible solutions.
2.4 In a Multi-agent (MA) system, what is “emergent capability”? Please provide examples of how this capability manifests in practical applications.
Definition and Characteristics of Emergence
1. Definition of Emergence
Emergence is the capability exhibited by the system as a whole, which does not exist in individual components. When multiple Agents work together in MA, they can accomplish tasks that a single Agent cannot or exhibit capabilities that a single Agent does not possess.
The emergent capability allows Multi-agent systems to solve complex problems, simulating the advantages of human teamwork, and in some aspects, surpassing human team performance.
2. Characteristics of Emergence
- Unpredictability: cannot be directly inferred from the capabilities of a single Agent
- Non-linearity: not a simple accumulation of capabilities, but a qualitative leap
- Interaction generation: arises from complex interactions and information exchanges between Agents
Manifestation in Practical Applications
- Debate Agents in the AutoGen framework: Agent1 proposes an initial plan, Agent2 challenges and critiques, Agent3 integrates opinions and improves.
- Team collaboration in the CrewAI framework: Agent1 is responsible for literature collection, Agent2 for data analysis, Agent3 for summarizing reports, collectively completing research work.
- Claude’s Constitutional AI: Agent1 generates content, Agent2 reviews and points out errors, Agent3 corrects based on feedback.
- Simulating financial market behavior in virtual economies: Buyer Agents and Seller Agents interacting may produce price fluctuations, speculative behaviors, and other real market phenomena.
- Creative collaboration and brainstorming: Agent1 provides sci-fi ideas, Agent2 provides historical context, Agent3 integrates them into a unique story.
2.5 What key issues should be noted when implementing Function calling? How can we effectively prevent hallucinations and parameter errors?
Key Issues in Function Calling
1. Function Definition and Documentation
- Key Issue: How to ensure the model accurately understands the function’s capabilities and parameter requirements
- Solution: Provide clear, structured function documentation, including function descriptions, parameter types, example usages, etc.
2. Parameter Validation and Error Handling
- Key Issue: The model may output parameters that do not meet requirements
- Solution: Implement strict parameter validation mechanisms, such as type checking, range validation, format validation, and provide specific feedback in case of errors
3. Timing of Function Calls
- Key Issue: The model may call functions at inappropriate times
- Solution: Clearly guide the model on when to call functions and when to respond directly, for example, instructing that “functions should only be called when external information is needed or specific actions are to be executed”
4. Parameter Hallucinations
- Key Issue: The model may fabricate non-existent parameter values
- Solution: Limit parameter options, provide enumerated values to clarify acceptable parameter ranges, and implement strict validation to prevent hallucinations
Effective Strategies to Prevent Hallucinations and Parameter Errors
1. Structured Input Validation
Use standards like JSON Schema to define parameter structures and implement strict type checking and value validation at the API layer.
2. Example Few-shot Prompting
Provide examples of correct function calls in the prompts to help the model understand the expected parameter format and usage scenarios.
3. Context Enhancement and Toolchain Design
Call information retrieval functions before action functions to reduce the need for the model to “guess” information.
2.6 What are the technical characteristics and applicable scenarios of mainstream Agent frameworks (such as AutoGen, LangChain, CrewAI, etc.)?
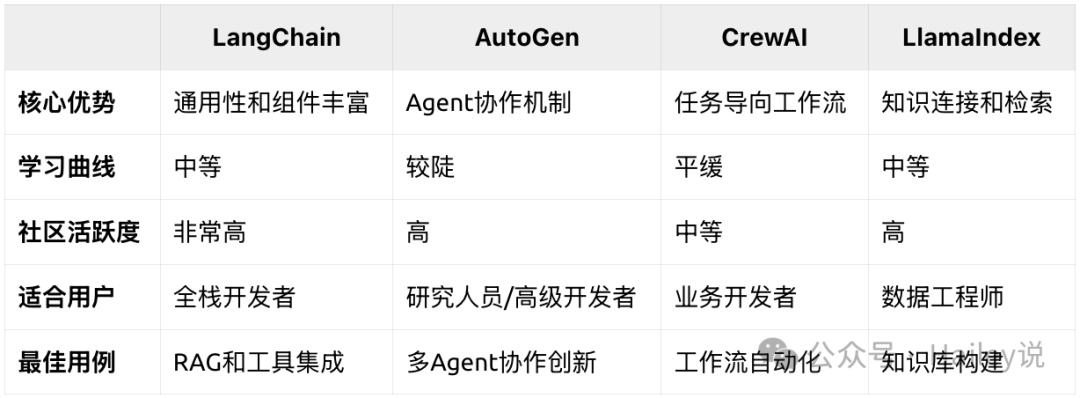
According to the comparison results in the image above, the choice of framework depends on specific needs:
- Quickly build fully functional Agents: LangChain
- Complex Agent team collaboration: AutoGen
- Clear workflow and task allocation: CrewAI
- Focus on knowledge management and retrieval: LlamaIndex
LangChain
Has a mature ecosystem and rich components (various LLMs, vector databases, document loaders), supporting multiple programming languages such as Python and JavaScript.
# LangChain Example: Create a simple RAG application
from langchain.agents import initialize_agent, Tool
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
# Create vector database
embeddings = OpenAIEmbeddings()
db = Chroma(embedding_function=embeddings)
# Define tools
tools = [
Tool(
name="Knowledge Base Search",
func=db.similarity_search,
description="Search for relevant documents"
)
]
# Initialize Agent
agent = initialize_agent(
tools,
ChatOpenAI(temperature=0),
agent="chat-conversational-react-description",
verbose=True
)
# Run Agent
agent.run("Tell me about quantum computing")
AutoGen
Supports complex dialogue flows, such as cross-examination, aggregation, and critique dialogue modes, with a powerful MA collaboration mechanism.
# AutoGen Example: Create a collaborative Agent team
import autogen
# Configure Assistant Agent
assistant = autogen.AssistantAgent(
name="Assistant",
system_message="You are a helpful AI assistant",
llm_config={"model": "gpt-4"}
)
# Configure Critic Agent
critic = autogen.AssistantAgent(
name="Critic",
system_message="Your role is to critically evaluate the assistant's answers and point out potential issues",
llm_config={"model": "gpt-4"}
)
# Configure User Proxy Agent
user_proxy = autogen.UserProxyAgent(
name="User",
human_input_mode="TERMINATE",
max_consecutive_auto_reply=10
)
# Create Group Chat
groupchat = autogen.GroupChat(
agents=[user_proxy, assistant, critic],
messages=[],
max_round=10
)
manager = autogen.GroupChatManager(groupchat=groupchat)
# Start conversation
user_proxy.initiate_chat(manager, message="How to invest in cryptocurrency?")
CrewAI
Each Agent has specific responsibilities and skills, with an intuitive team-building approach and clear role definition mechanisms, built-in task planning and allocation functions.
# CrewAI Example: Create a market research team
from crewai import Agent, Task, Crew
# Create Researcher Agent
researcher = Agent(
role="Market Researcher",
goal="Find the latest market trends and competitor information",
backstory="You are an experienced market research expert",
tools=[search_tool, browser_tool]
)
# Create Analyst Agent
analyst = Agent(
role="Data Analyst",
goal="Analyze market data and extract valuable insights",
backstory="You excel at discovering business opportunities from data",
tools=[calculator_tool, visualization_tool]
)
# Create Tasks
research_task = Task(
description="Research the latest trends in the smart home market",
expected_output="Detailed market research report",
agent=researcher
)
analysis_task = Task(
description="Analyze the competitive landscape of the smart home market",
expected_output="Competitive analysis report and opportunity points",
agent=analyst,
dependencies=[research_task]
)
# Assemble team and execute tasks
crew = Crew(
agents=[researcher, analyst],
tasks=[research_task, analysis_task]
)
result = crew.kickoff()
LlamaIndex
Has powerful and flexible knowledge base construction and retrieval capabilities, excellent document processing and structuring capabilities, vector retrieval, and hybrid retrieval methods.
2.7 When building an Agent based on Retrieval-Augmented Generation (RAG), how can we address knowledge conflicts and outdated information?
Solutions to Knowledge Conflict Issues
1. Information Source Priority Mechanism
Establish a credibility scoring system for information from different sources:
- Assign source weights: official documents > academic papers > news reports > social media
- Implement conflict detection algorithms to identify contradictory information, and in case of conflict, select information from the higher priority source
2. Timestamp-aware Retrieval
Add time metadata to all knowledge entries, and arrange data in time-sensitive fields according to the principle of “freshness priority”.
3. Structured Knowledge Network
Validate and cross-check multiple documents and compare information, calculating information consistency scores. Alternatively, build knowledge graphs to connect related information and use graph algorithms to detect and resolve conflicts.
Solutions to Outdated Information Issues
1. Hierarchical Knowledge Base Architecture
Layer knowledge base data, for example, placing “evergreen layer” for fundamental principles, historical facts, and other unchanging information, and “timeliness layer” for news, market data, and other information that changes over time.
2. Automatic Update and Half-life Mechanism
Establish regular update processes for time-sensitive knowledge data, set half-lives for different types of information, and provide warnings for overly outdated information.
2.8 In a Multi-Agent System (MAS), how can we design effective Agent collaboration mechanisms? Discuss the design differences between homogeneous and heterogeneous Agent systems.
- Involves communication protocols, role division, task allocation, conflict resource coordination, and shared knowledge management. In practical applications, hybrid collaboration mechanisms are often employed (refer to CrewAI’s Best practice).
- In homogeneous Agent systems, all Agents have similar capabilities, tasks are interchangeable, and Agents use peer-to-peer communication networks (each Agent can communicate directly with any other Agent), making decisions through voting, consensus, or auctions.
- In heterogeneous Agent systems, Agents have complementary capabilities, Agents publish their capabilities, and other Agents can discover and call them, with a predefined hierarchical structure and workflow determining the order of Agent interactions.
2.9 Memory management for Agents is crucial. Discuss the implementation methods and limitations of long-term and short-term memory in Agent systems.
The Agent memory system is divided into short-term memory and long-term memory:
- Short-term memory: maintains recent dialogue and task context, has limited capacity but quick access.
- Long-term memory: stores persistent information, learning experiences, and user preferences, has large capacity but complex retrieval.
Implementation Methods for Short-term Memory
1. Context Window
Directly retain recent dialogue history in the model input context window.
Limitation: Limited by the size of the model’s context window, history beyond the window will be forgotten, and increasing the window size leads to linear increases in computational costs.
2. Summary Compression Techniques
Regularly compress earlier dialogues into summaries, retaining key information while reducing token usage.
Limitation: Information compression inevitably leads to information loss, summary quality depends on the base model’s capabilities, and increases LLM invocation costs.
3. Hierarchical Attention Mechanism
Store dialogue history hierarchically by importance and time, and dynamically call relevant parts using attention mechanisms.
Limitation: Requires accurate judgment of information importance mechanisms, and the logic of adjusting attention weights is complex, still subject to overall context window limitations.
Implementation Methods for Long-term Memory
1. Vector Database Storage
Convert dialogues and information into vector embeddings and store them in a vector database, supporting semantic search.
Limitation: Retrieval is based on semantic similarity, which may overlook key information. Limitations of embedding models will affect memory quality. Large-scale memory requires optimization of indexing results. Difficult to capture time-series related results.
2. Knowledge Graph Method
Construct structured graphs of entities and relationships to capture logical relationships between information.
Limitation: The accuracy of extracting entity relationships from unstructured dialogues is uncontrollable. Large-scale graph computation is costly, and scalability is poor. Suitable for factual knowledge, but expressing emotional and contextual information is challenging.
3. Hybrid Retrieval-Augmented Generation (RAG)
Combine document retrieval and generation capabilities, dynamically obtaining relevant memories and integrating them into responses.
Limitation: LLM may ignore retrieved content or produce hallucinations, and retrieval accuracy for rare or specific memories is limited.
4. Hierarchical Memory Architecture
Simulate the multi-level structure of human memory, including episodic memory, semantic memory, and procedural memory.
Limitation: Architectural design requires domain expertise, coordination and consistency between different levels pose challenges, and high demands on memory and computational resources.
Key Challenges and Solutions in Memory Management
1. Memory Decay and Importance Judgment
How to simulate the characteristic of human memory where important information is retained while trivial details decay?
Solution: Mark memory with emotional response intensity. Frequently accessed memories receive higher retention priority. Implement time-based memory weight decay.
2. Memory Conflicts and Updates
How to handle contradictory information and knowledge that changes over time?
Solution: Set timestamps to maintain records of the same information at different points in time. Establish a trust scoring system to assign credibility to information from different sources.
3. Memory Retrieval Efficiency
How to quickly find the most relevant content in a large-scale memory base?
Solution: Implement hybrid retrieval strategies, combining keyword and semantic searches. Use a multi-stage retrieval mechanism, with coarse filtering followed by fine reordering.
4. Privacy and Security
How to ensure the security of sensitive memories while maintaining functional integrity?
Solution: Prioritize storing sensitive data locally. Set different access permissions for different levels of memory.
2.10 How to evaluate (evals) the performance and effectiveness of Multi-agent systems? What are the limitations of existing evaluation metrics?
1. Task Completion Evaluation
Metrics: task success rate, result quality scores (automated or manual), time taken and number of steps required, computational resource consumption, and number of API calls
Limitation: For open-ended tasks, the definition of “success” is vague. May overlook process quality, focusing only on the final result.
2. Collaboration Efficiency Evaluation
Metrics: number of communications required between Agents to complete tasks, proportion of redundant actions and non-actual task collaborations, task completion rate of MA collaboration.
Limitation: Difficult to define good and bad standards.
3. Emergent Capability Evaluation
Metrics: ability to generate novel insights, ability to maintain functionality in the event of Agent failure or errors, ability to solve problems beyond the capabilities of a single Agent.
Limitation: Emergent capability is inherently difficult to predict, reproduce, and quantify. Human judgment plays a large role, making automated evaluation challenging.
4. Resource Efficiency Evaluation
Metrics: total computational resource consumption to complete tasks, whether system response times are delayed.
Limitation: Resource consumption is related to underlying infrastructure. API cost calculations are complex, especially when mixing different providers.
5. Human-Machine Collaboration Evaluation
Metrics: subjective evaluation of system performance by users, rate at which the system accurately understands user intentions.
Limitation: Satisfaction is heavily influenced by user expectations.
2.11 Anthropic’s recommendations for building Effective Agents
The development history of LLMs-based AI systems, from simple functions to workflows to agents, has led to increased autonomy, practicality, and capabilities, but also increased costs, delays, and errors.
Anthropic’s Barry Zhang proposed three core concepts:
- Not all problems should be solved with Agents, Agents are suitable for complex and valuable tasks, coding is a typical scenario, complex, high-value, standardized coding workflows that can be easily verified through testing.
- Keep the initial Agent architecture simple, after building the basic architecture of the Agent, you can start validating test cases and observing tool calls and task execution.
- Think like the Agent you build, to analyze the necessary context and information for the Agent and the possible reasons for errors, thus better understanding the Agent’s decision-making process.
3 Recommended Reading
- Anthropic – “Building effective agents”https://www.anthropic.com/engineering/building-effective-agents
- DeeplearningAI – “Multi AI Agent Systems with CrewAI”https://www.deeplearning.ai/short-courses/multi-ai-agent-systems-with-crewai/
- “Why do multi-agent LLM systems fail?”https://www.alphaxiv.org/abs/2503.13657
- “Large Language Model based Multi-Agents: A Survey of Progress and Challenges”https://www.alphaxiv.org/abs/2402.01680