June 4, 2019 Original Author: Felix Yu, Source: https://flyyufelix.github.io/2019/06/04/pixmoving-hackathon.html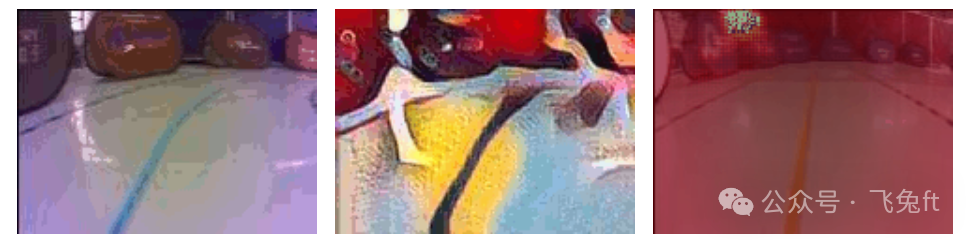
Using style transfer as a data augmentation technique to improve model robustness
1. Introduction During my time in the United States last year, I attended several Donkey Car meetups and noticed that Donkey Cars using end-to-end neural networks (i.e., directly outputting steering and throttle) performed worse than those using traditional optimal control methods (such as line following, path planning, etc.). No matter how hard people tried, the neural network models always lost to the carefully optimized control algorithms. Even more frustrating was that during actual competitions, when there were spectators around the track, most neural network-driven Donkey Cars couldn’t even complete a lap!
So, why do neural networks perform poorly? As enthusiasts of neural networks and deep learning, how can we improve the performance of neural network-driven Donkey Cars and make them strong competitors against those driven by traditional optimal control algorithms? In this blog post, I will discuss some of the main drawbacks of neural network models and outline various techniques we tried to overcome these challenges.
2. Pixmoving Hackathon Pixmoving is a Chinese autonomous vehicle startup that organized a hackathon in May 2019, bringing together participants from around the world to explore new ideas in autonomous driving. I was fortunate to participate in the small car category with my friends Fei and Marco. We assembled a Donkey Car equipped with the newly released Jetson Nano (replacing the Raspberry Pi) to compete in this hackathon. Compared to the Raspberry Pi, the Jetson Nano has a GPU, providing more computational power, allowing us to test new ideas in neural network modeling while achieving higher frame rates.

Our Jetson Nano Donkey Car assembled by Fei
For those who want to set up a Jetson Nano on their Donkey Car, you can check out this excellent guide written by Fei.
Due to a busy schedule, we could only test the new Jetson Nano Donkey Car on a scaled-down track (only 60% of the full-size track) a few days before the hackathon (thanks to the Hong Kong Autonomous Model Car Association for providing the venue). However, the testing went well, and we had high expectations for its performance in the competition.

Testing our new Jetson Nano Donkey Car at the Hong Kong Polytechnic University
Until we finally arrived at the hackathon venue and saw the actual track:

Small car track at the Pixmoving factory in Guiyang Science City
Note that the track is set on a smooth surface covered with moving shadows and sunlight glare. Additionally, the lack of strong color contrast between the ground and the track lines makes the track more challenging. The suboptimal track conditions undoubtedly made things more difficult; however, it also provided us with a rare opportunity to truly test the robustness of the neural network approach and see how far it could go.
Interesting anecdote: At one point, Fei suggested equipping the Donkey Car with polarized lenses to filter out sunlight glare. We even tried to find a pair of sunglasses to experiment with this idea, but we couldn’t find any!
Using polarized lenses to filter sunlight glare
3. Our Initial Attempts to Improve the Model Our first attempt was to train a baseline model through behavior cloning. The principle of behavior cloning is to first collect a set of training data through manual driving, and then train a convolutional neural network (CNN) to learn the mapping from images captured by the car’s front camera to the recorded steering angles and throttle values through supervised learning.
As expected, the initial behavior cloning model performed poorly. Whenever the car encountered shadows and sunlight reflections, the model completely failed, and these situations were everywhere on the track. Sometimes, the model even failed due to moving people in the background, clearly indicating that the neural network model was overfitting to the background rather than the track itself.

Our baseline model could not complete sharp turns
Subsequently, we tried various approaches in modeling:
3.1 Stacking Frames We no longer used a single RGB frame as input to the neural network, but instead stacked four grayscale frames from consecutive time steps as input to the model. The purpose of this approach was to allow the model to capture important temporal information by learning the subtle changes between consecutive frames.
3.2 Long Short-Term Memory (LSTM) We also trained an LSTM model using seven time steps to capture more information in the temporal dimension. For each time step, a three-layer convolutional neural network (CNN) was used to extract features from the original RGB frames, and these features were then used as input to the LSTM model.
3.3 Reinforcement Learning Before the competition, I successfully trained the Donkey Car using reinforcement learning in a simulator. If you want to know the specific implementation, please refer to my previous article. The reinforcement learning algorithm I used to train the model was the Double Deep Q-Network (DDQN).
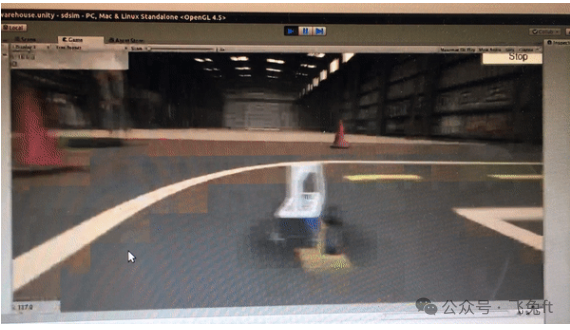
Training the Donkey Car driving using DDQN in the Unity simulator. Thanks to Robin for helping me customize the scene environment.
My initial idea was to try zero-shot transfer from simulation to reality (i.e., training the model entirely on a virtual track and then directly deploying it to a real track). However, due to the significant differences between the virtual and real tracks, I switched to using the DDQN model to initialize the neural network weights and then used the data we collected on the real track for supervised learning.
My goal was to improve the data efficiency of behavior cloning so that we wouldn’t need to collect too much data for the model to work properly. Additionally, the pre-trained reinforcement learning model might help improve the overall robustness of the final model. It is well known that data collected through human demonstrations and models trained on such data are often not robust enough because human-collected data tends to be biased towards certain states while neglecting others.
To our disappointment, none of the above methods significantly improved the performance of the Donkey Car. Our Donkey Car still couldn’t complete a full lap. We had to come up with other methods to enhance the robustness of the Donkey Car under different track conditions.
4. Robustness Issues of Neural Network Behavior Cloning As mentioned earlier, behavior cloning learns the mapping from RGB images to steering and throttle using convolutional neural networks (CNNs) (i.e., end-to-end training). Ideally, the CNN model should learn that the track lines are the most important information, while objects in the background and shadows and reflections on the track are irrelevant information that should be ignored.
However, due to the way convolutional neural networks (or neural networks in general) work, the model often overfits to the most prominent features in the image, which in our case are the objects in the background and the light reflections on the track.

Saliency heatmap of our baseline model
The video above shows the saliency heatmap of our baseline CNN model trained through behavior cloning. The heatmap is generated based on the code provided by this repository. The principle is to find the parts of the image that correspond to the maximum activation values of the CNN layer feature maps; in other words, the heatmap shows the areas the model “focuses” on when making decisions.
To thoroughly test the model’s generalization ability, the dataset we used to train the model and generate the heatmap came from two different days, containing different lighting conditions and surface reflection intensities. Note that the model’s attention is almost entirely focused on background objects and sunlight reflections rather than the track lines. Therefore, it is not surprising that the model performs poorly when background objects change or move, or when there are sunlight reflections. The model trained from the original images is very fragile!
5. Using Computer Vision Techniques to Overcome Variations in Track Conditions Our next attempt was to use computer vision techniques to remove background objects and eliminate sunlight glare on the track. We first tried using edge detection (e.g., Canny edge detector) combined with Hough line transformation to segment the track lines from the images. In my previous blog post, I briefly introduced this method for segmenting track lines in the simulator. However, after some quick experiments, I found that this method did not work on real tracks. For example, for the image below marked with strong sunlight glare:


Canny edge detection fails to capture the track lines
The edge detector couldn’t even capture the track lines!
Subsequently, we tried using color thresholds to extract the track lines by projecting the RGB color space into the HSV color space and finding suitable thresholds to separate the track lines from the images. It turned out that extracting sunlight glare through thresholding was easier than extracting track lines from the images because the glare’s color had a higher distinguishability from the background.
We used the above thresholding technique to mask out sunlight glare from the images and filled the blank areas with the average pixel value of the image. The results are shown below:

Using color thresholds to remove sunlight glare
Our method successfully filtered out most of the sunlight glare. It is worth noting that there may be false positives (i.e., the method incorrectly filtered out parts of the track that were not sunlight glare), but the impact of these false positives should be minimal and can even be seen as a form of regularization to avoid overfitting to the background!
Thus, the Donkey Car successfully navigated through the randomly occurring sunlight glare patterns on the track!

Successfully passing through areas with sunlight glare
In contrast, the Donkey Car trained directly using the raw images without preprocessing would get stuck in loops whenever it encountered strong sunlight glare.

Performance of most Donkey Cars when sunlight glare is present on the track
However, even after filtering out the sunlight glare, the resulting model was still not robust enough. While it could complete a full lap and somewhat overcome the random sunlight glare patterns, its performance was not stable. For example, when people moved around the track, background objects were moved or changed, or when the sunlight intensity decreased as it approached evening, the model could not consistently complete the task. We realized we had to try other methods to further improve the robustness of the Donkey Car.
6. Achieving Robustness Using Style Transfer At this point, Marco recalled a paper he read a few years ago that used a technique called style transfer to enhance the training dataset, making the model more sensitive to important features (like track lines) while ignoring unimportant patterns (like background objects and track surface).
We applied three different and unique styles (i.e., “The Scream,” “Starry Night,” and a candy filter) to the training image set, and below are the visual results of the dataset after style transfer:

Style Transfer Visualization (Top left: Original image, Top right: Candy filter, Bottom left: “The Scream,” Bottom right: “Starry Night”)
After some visual inspection, we found that the track lines were indeed enhanced during the style transfer process, while background objects and track surface patterns were somewhat smoothed out! Therefore, we could use this enhanced dataset to train the model to focus more on the track lines and become less sensitive to background objects.
We trained a model using both the style transfer dataset and the original dataset, and its performance and robustness significantly improved compared to our previous baseline model! The model that previously failed due to variations in track reflection intensity or moving background objects suddenly started working properly!

Model trained with style transfer dataset completing a full lap
To verify whether our model was truly focusing on the track lines, we generated saliency heatmaps for the style transfer model using the same test dataset as the baseline model:
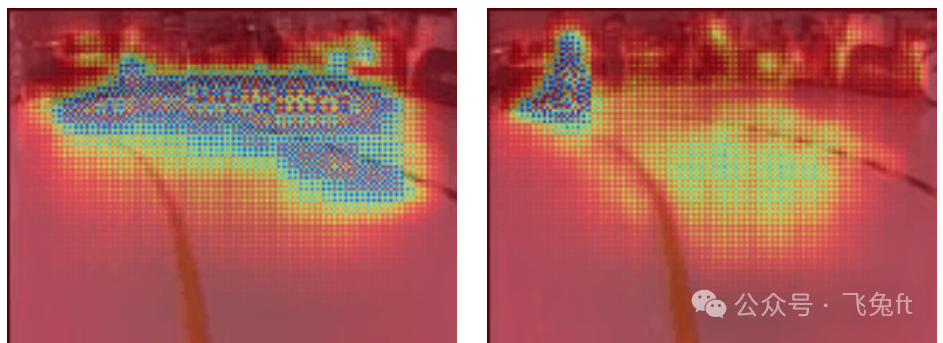
Left: Style transfer model, Right: Baseline model
We noticed that while the style transfer model still occasionally overfit to the background, it showed a significantly stronger focus on the track lines. In contrast, our baseline model hardly paid any attention to the track lines! In our view, style transfer can serve as an effective data augmentation technique to improve the model’s generalization ability and robustness, especially in cases where the dataset is small or when the model needs to adapt to new tracks.
7. Failures of Segmentation Attempts Before the hackathon, we were already aware of the fragility of using end-to-end neural networks for driving. To filter out background noise, we attempted to train a semantic segmentation model to extract track lines from images. We spent hours labeling the track lines and ultimately compiled a dataset of about 130 images, divided into four categories: left track line, right track line, center track line, and track area.

Manually labeling the dataset using Labelbox
One of the main reasons we decided to replace the Raspberry Pi with the Jetson Nano was to gain enough computational power to integrate the segmentation model into the inference process. Our plan was to first input the original RGB frames into the segmentation model, obtain the mask of the track lines, and then use the mask as input to the behavior cloning neural network.
Here are the steps we attempted in chronological order, ultimately stopping due to time constraints:
- Wrote unit tests for the data loader.
- Implemented the data loader that passed the unit tests.
- Visualized the data loaded by the data loader in a notebook to ensure the data looked correct.
- Modified the U-Net Keras architecture from an existing GitHub repository.
- Wrote unit tests for the U-Net model to check if gradients were correctly passed through each layer.
- Implemented our own DICE loss function.
- Attempted to overfit a batch of data but failed to achieve training loss = 0 (stagnated at a high value).
- Loaded only the track mask instead of all four masks, still unable to achieve training loss = 0.
- Discovered we had not mapped the image range from [0, 255] to [0, 1], fixed this issue.
- Successfully overfitted a batch of data, achieving training loss = 0.
- Trained using all data and only track mask labels, but convergence was very slow.
- Checked the predicted images, all pixel values were 0.
- Added L1 loss to regularize training, encouraging sparsity, which sped up training, but both training and validation losses stagnated.
- Checked the predicted images again, all pixel values were still 0.
- We suspected that the amount of training data was too small to make the segmentation model work properly.
8. Hackathon Results The winning criterion for the competition was the fastest lap time. Due to the unexpectedly difficult track (it even rained during the competition), the organizers decided to give the 11 teams unlimited attempts! Basically, there was a timer next to the track, and we could notify the timer whenever we were ready to time our lap. I know this format is a bit strange; it somewhat encourages teams to overfit to the background since we had unlimited attempts and only needed the fastest lap time to win.
Indeed, the best lap time was recorded when the background and lighting were relatively stable (i.e., the sun was obscured by clouds, and the environment around the track was cleared). Our best lap time was 12.67 seconds, finishing fourth, just 0.02 seconds slower than third place! Part of the reason was that we left a day early before the competition (we couldn’t take another day off…), so we missed half a day of opportunities to further improve our best lap time!
9. Lessons Learned9.1 Simple Models + Quality Datasets Can Achieve Great Results From our experience at the hackathon, all significant improvements came from enhancing the quality of the training dataset rather than model innovations. We tried various methods to improve the model, including using stacked frames, LSTMs, adjusting the neural network architecture, and fine-tuning on reinforcement learning models, but none significantly improved performance. In contrast, innovations that improved dataset quality, such as computer vision preprocessing and style transfer augmented datasets, led to significant performance gains.
In fact, the winning team achieved a best lap time of 9.75 seconds using only a baseline model trained on a carefully collected dataset. He showed us how to pay extra attention to collecting quality data in the more challenging parts of the track (i.e., sending clear, strong, and consistent steering signals).
This resonates with OpenAI and Tesla’s AI problem-solving philosophy, which emphasizes learning from high-quality datasets rather than through model innovation by expanding computational infrastructure.
9.2 End-to-End Neural Network Models Still Lag Behind Optimal Control Methods After two days of unlimited attempts, the best lap time of 9.75 seconds still significantly lagged behind the optimal control Donkey Car’s best lap time of about 8 seconds (by @a1k0n). Even with data augmentation and regularization techniques, I believe that end-to-end neural network models struggle to pose a real challenge to optimal control Donkey Cars.
Neural networks excel in domains where traditional optimal control methods cannot capture underlying dynamics, such as training humanoid dexterous hands to manipulate physical objects or executing controlled drifts! We should understand their limitations and use them only in appropriate scenarios, rather than blindly applying them to all problems, especially where optimal control already has solutions.
10. Acknowledgments I would like to thank Pixmoving for organizing such a wonderful event! The venue was great, and we had the opportunity to try many ideas that would otherwise be difficult to implement. I want to thank Robin for helping me with Unity-related work. Last but not least, my teammates Fei and Marco, who participated in the hackathon with me and came up with many brilliant ideas!
If you have any questions or thoughts, please leave a comment below.
You can also follow me on Twitter: @flyyufelix.