Follow us to stay updated Introduction:This intelligent scenario focuses on UI automation testing, with a case study from Meituan, highlighting the exploration of multi-agent collaboration.The complete materials can be obtained at the end of this article.
Introduction:This intelligent scenario focuses on UI automation testing, with a case study from Meituan, highlighting the exploration of multi-agent collaboration.The complete materials can be obtained at the end of this article. The pain points of testing will not be elaborated here; let’s get straight to the point.Three modes of human-machine collaboration are discussed here, similar to the L1-L5 classification shared previously by Tencent, though one is coarse and the other is fine.
The pain points of testing will not be elaborated here; let’s get straight to the point.Three modes of human-machine collaboration are discussed here, similar to the L1-L5 classification shared previously by Tencent, though one is coarse and the other is fine.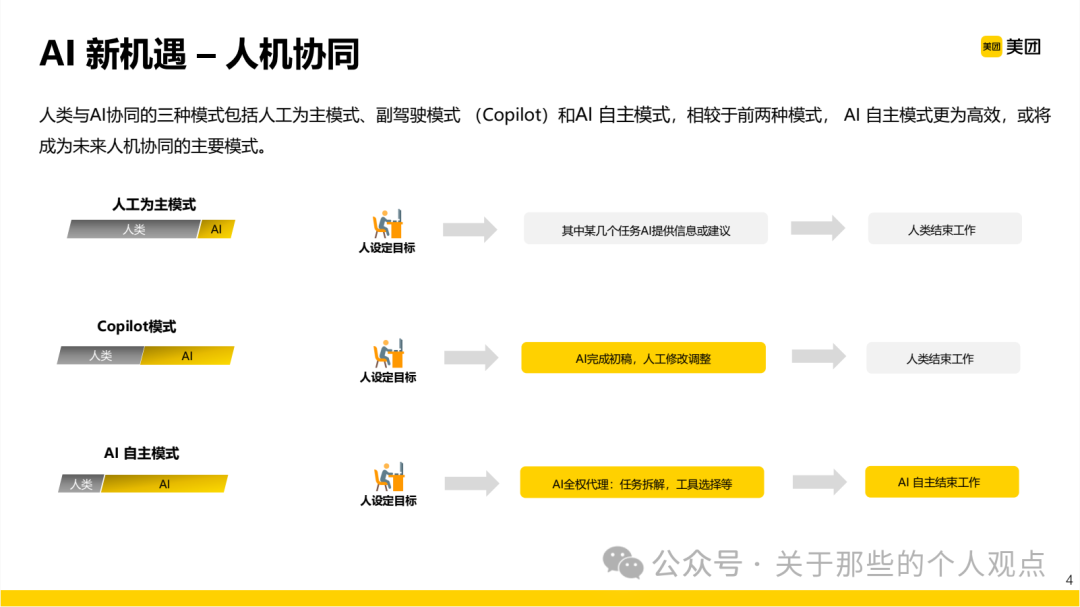 When the concept of Agents first emerged, it indeed significantly enhanced the capabilities of large models, allowing them to handle most simple tasks through task planning, tool usage, and contextual memory.However, for long processes and auxiliary scenario tasks, a multi-agent collaborative framework is still required. The industry has proposed MCP and A2A protocols, which will not be discussed in depth here; if interested, you can read previous articles:MCP Principles and Some Deep Code AnalysisAgents, MCP, and A2A are Accelerating the Disruption of the Software Industry
When the concept of Agents first emerged, it indeed significantly enhanced the capabilities of large models, allowing them to handle most simple tasks through task planning, tool usage, and contextual memory.However, for long processes and auxiliary scenario tasks, a multi-agent collaborative framework is still required. The industry has proposed MCP and A2A protocols, which will not be discussed in depth here; if interested, you can read previous articles:MCP Principles and Some Deep Code AnalysisAgents, MCP, and A2A are Accelerating the Disruption of the Software Industry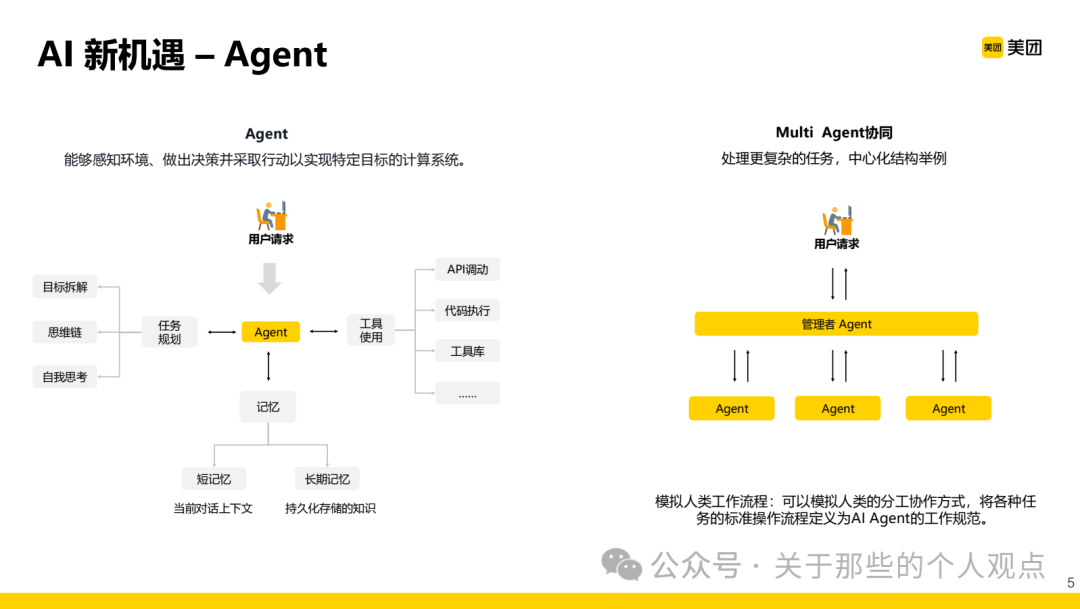 Using the food delivery scenario as an example, the React and Execute modes in the multi-agent collaboration process are explained. Currently, the Execute mode remains mainstream in the industry.
Using the food delivery scenario as an example, the React and Execute modes in the multi-agent collaboration process are explained. Currently, the Execute mode remains mainstream in the industry.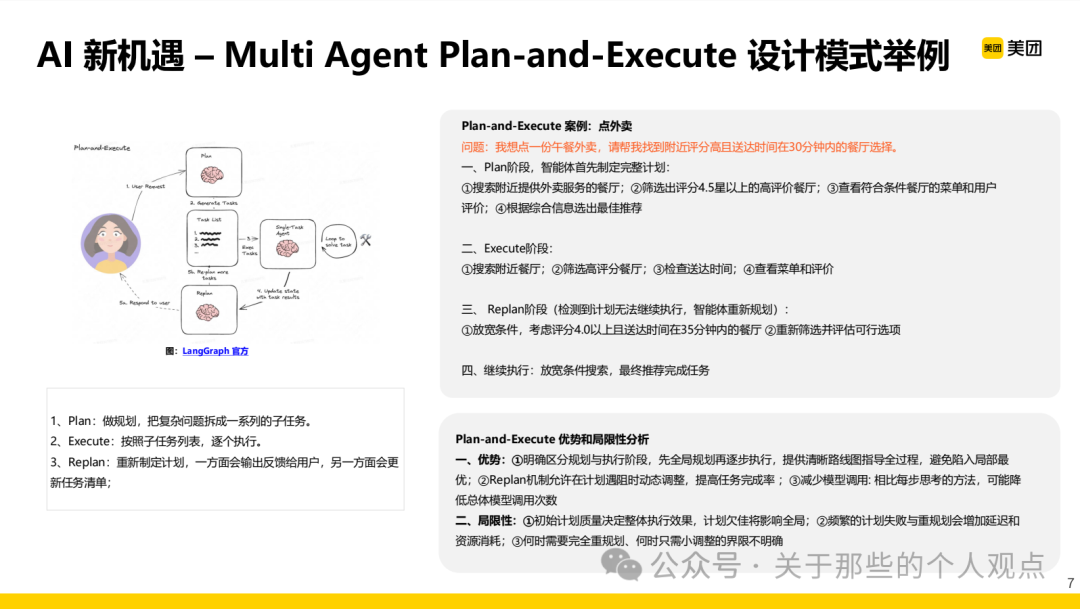 By detailing the above case, we arrive at a multi-agent collaborative “system” for UI automation testing.From a literal perspective, there are five agents: task analysis, next step prediction, instruction execution, evaluation reflection, and self-healing (environment perception is also included in the architecture diagram, which seems to be omitted in the text
By detailing the above case, we arrive at a multi-agent collaborative “system” for UI automation testing.From a literal perspective, there are five agents: task analysis, next step prediction, instruction execution, evaluation reflection, and self-healing (environment perception is also included in the architecture diagram, which seems to be omitted in the text  ).
).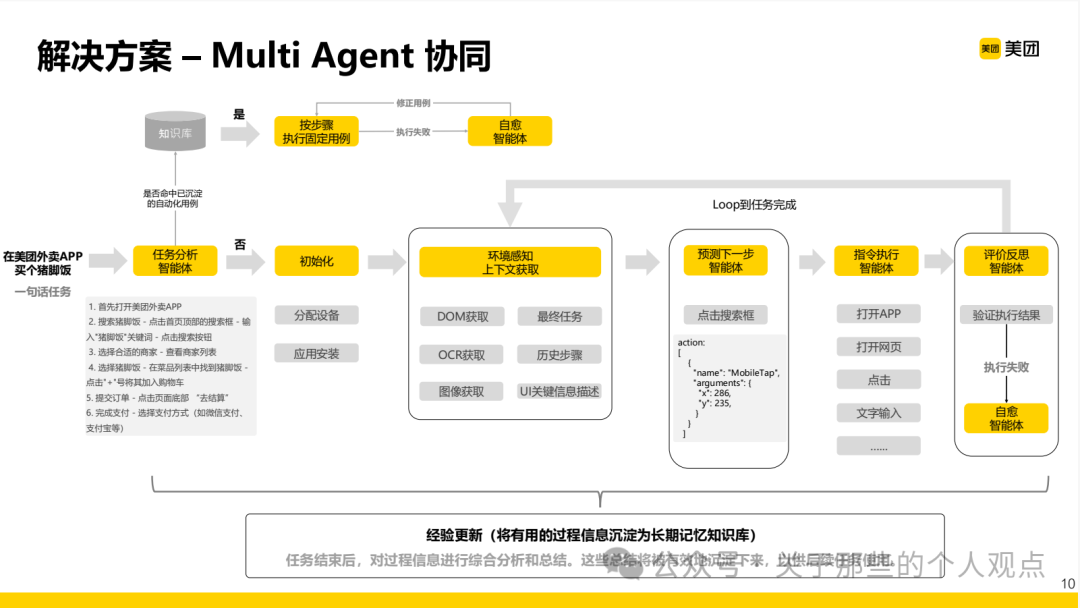 This process also involves a knowledge base, but unlike the typical knowledge bases we are familiar with that store testing and business domain content, this one is used to store existing automation cases (at least based on the textual description).This actually touches on a very important point: At this stage, when leveraging large models to achieve natural language-based UI automation testing, should we retain natural language as the use case or keep the final generated script as the use case?Based on a comprehensive analysis of solutions from other major companies, the current optimal solution is still to retain the final generated script as the use case.The main reasons are as follows:1. Consistency issues with large model executions2. Efficiency issues in executing automated tests3. Cost issues related to model dependencies during executionIf natural language is used as the use case, given the current model capabilities, the outputs from each input will inevitably be inconsistent, which conflicts with the reproducibility and regression nature of test cases.Executing natural language use cases requires multiple steps to call the model, which will exponentially increase the time, and the multi-agent collaborative approach further exacerbates the time and token consumption, leading to double costs.Of course, it is not ruled out that one day in the future, when model capabilities evolve to a level where intelligence is sufficiently high, speed is fast enough, and costs are low enough, the process of generating “test scripts” may no longer be necessary.Next, we will break down the core points:In the environment perception aspect, it can actually combine DOM extraction, OCR recognition, and multimodal perception methods. As model capabilities improve, it will gradually shift to a primarily multimodal recognition approach.
This process also involves a knowledge base, but unlike the typical knowledge bases we are familiar with that store testing and business domain content, this one is used to store existing automation cases (at least based on the textual description).This actually touches on a very important point: At this stage, when leveraging large models to achieve natural language-based UI automation testing, should we retain natural language as the use case or keep the final generated script as the use case?Based on a comprehensive analysis of solutions from other major companies, the current optimal solution is still to retain the final generated script as the use case.The main reasons are as follows:1. Consistency issues with large model executions2. Efficiency issues in executing automated tests3. Cost issues related to model dependencies during executionIf natural language is used as the use case, given the current model capabilities, the outputs from each input will inevitably be inconsistent, which conflicts with the reproducibility and regression nature of test cases.Executing natural language use cases requires multiple steps to call the model, which will exponentially increase the time, and the multi-agent collaborative approach further exacerbates the time and token consumption, leading to double costs.Of course, it is not ruled out that one day in the future, when model capabilities evolve to a level where intelligence is sufficiently high, speed is fast enough, and costs are low enough, the process of generating “test scripts” may no longer be necessary.Next, we will break down the core points:In the environment perception aspect, it can actually combine DOM extraction, OCR recognition, and multimodal perception methods. As model capabilities improve, it will gradually shift to a primarily multimodal recognition approach. After perceiving the environment, the recorded element information and task information are organized into corresponding prompts for the next step prediction, with the entire process transmitted in JSON format for ease of processing and parsing.
After perceiving the environment, the recorded element information and task information are organized into corresponding prompts for the next step prediction, with the entire process transmitted in JSON format for ease of processing and parsing. This part is about self-healing of use cases, but from the flowchart perspective, Tencent’s approach is undoubtedly more comprehensive.
This part is about self-healing of use cases, but from the flowchart perspective, Tencent’s approach is undoubtedly more comprehensive.
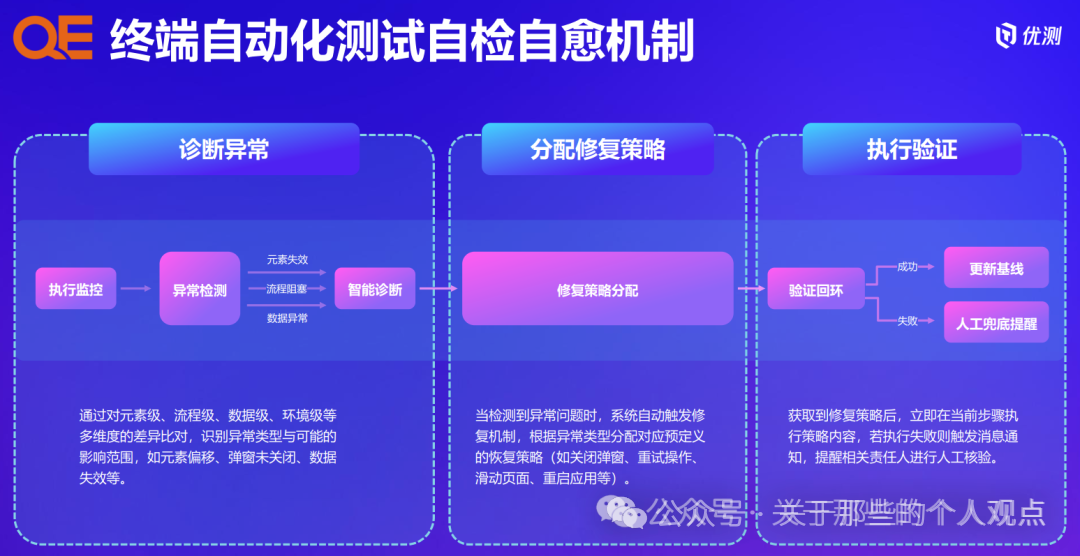 Experience updates actually refer to the persistent storage of test scripts mentioned earlier, and the reasons are consistent.
Experience updates actually refer to the persistent storage of test scripts mentioned earlier, and the reasons are consistent. In terms of overall architecture, the reference significance of the basic tool layer is greater. To produce usable intelligent agents, it is essential to encapsulate the tool layer. Meituan mainly focuses on mobile and web platforms, hence listing these two types.Some of these tool operations correspond to code blocks in the test scripts; for example, our company’s product has its own front-end framework, so it instructs the large model to output the encapsulated style when generating script code for operations like “click button”.
In terms of overall architecture, the reference significance of the basic tool layer is greater. To produce usable intelligent agents, it is essential to encapsulate the tool layer. Meituan mainly focuses on mobile and web platforms, hence listing these two types.Some of these tool operations correspond to code blocks in the test scripts; for example, our company’s product has its own front-end framework, so it instructs the large model to output the encapsulated style when generating script code for operations like “click button”.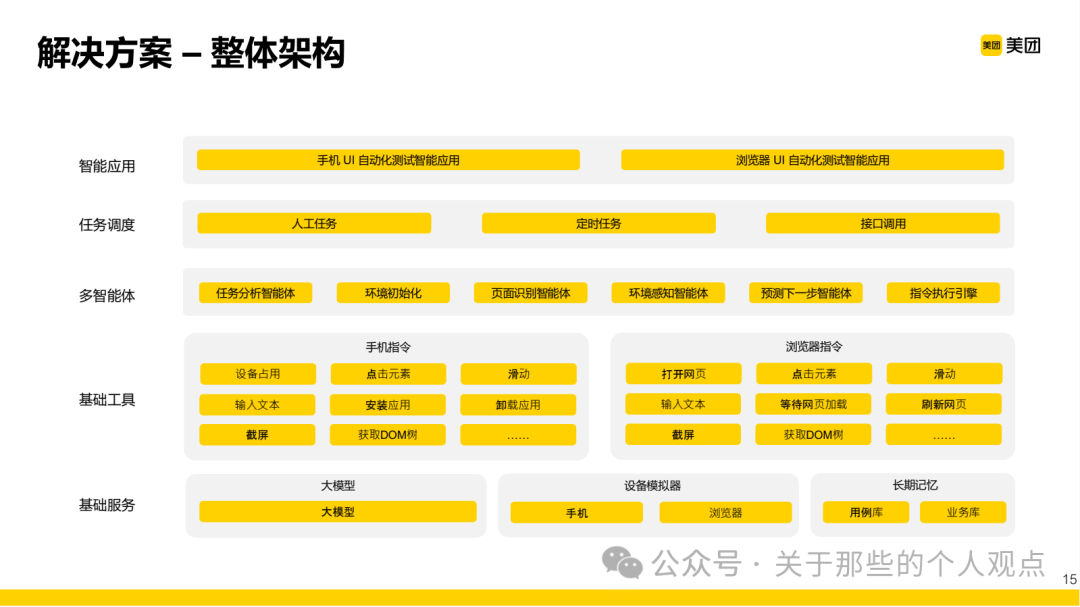 Finally, there is a capability summary comparison chart, but it overlooks a very important dimension, which is resource costs. The capabilities provided by large models are all based on sufficient computing power!Of course, for large companies, this is just a drop in the bucket~
Finally, there is a capability summary comparison chart, but it overlooks a very important dimension, which is resource costs. The capabilities provided by large models are all based on sufficient computing power!Of course, for large companies, this is just a drop in the bucket~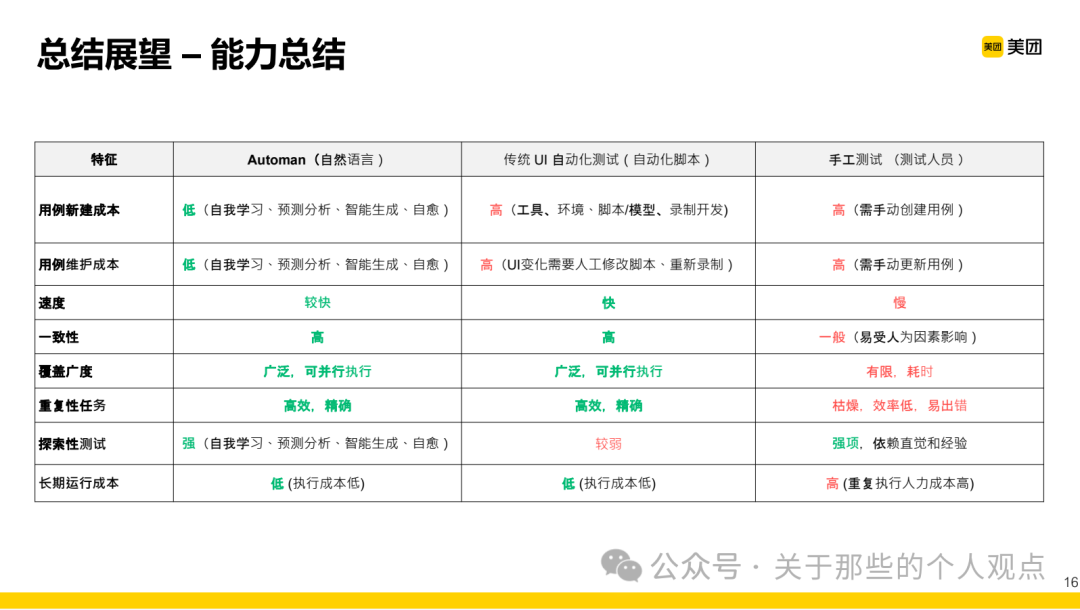 Follow our public account and send the message “Intelligent Testing” to obtain the complete content PDF
Follow our public account and send the message “Intelligent Testing” to obtain the complete content PDF
Disclaimer:
This public account is dedicated to providing valuable learning materials to readers. All shared content is sourced from the internet, and copyright belongs to the original authors. We respect originality and strive to indicate sources. If your rights are infringed, please contact us promptly, and we will delete it immediately.