A Brief Overview of Meta’s Multi-Token Attention

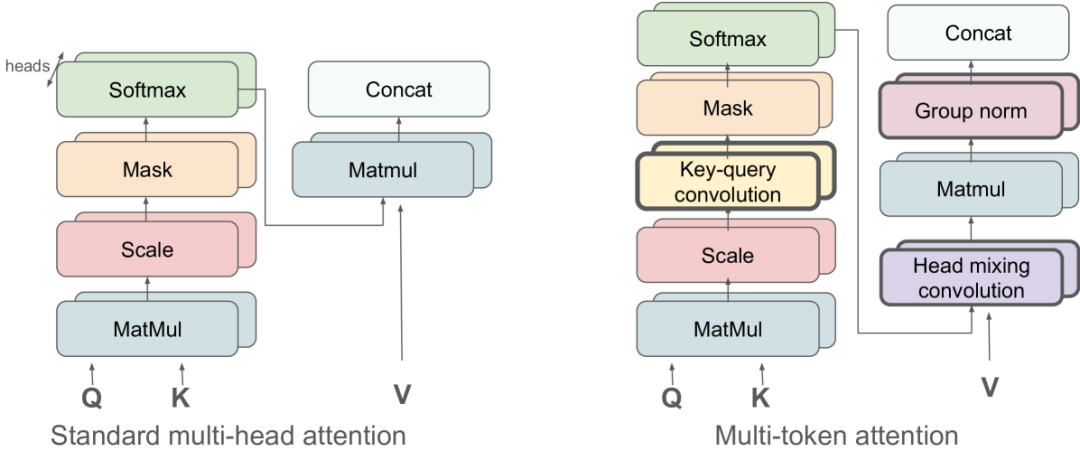
Meta’s new attention mechanism, MTA (Multi-Token Attention), enhances the model’s ability to perceive the locations of key information by incorporating convolution, allowing the model to attend to more information across tokens and attention heads during the attention computation phase.
Traditional multi-head attention can split multiple heads to focus on different directions during querying, calculating attention, and then using it for subsequent inference analysis. For example, if the query is: “Find the rows that simultaneously contain characters x and y.” Initially, two heads can be split: one focusing on tokens related to character ‘x’, and the other focusing on tokens related to character ‘y’.
After calculating attention, these two heads provide references for subsequent inference, allowing for a comprehensive analysis to find the relevant rows.
Their current approach is to merge (convolve) the attention values of these two heads in advance. This way, the target rows become very apparent in the merged attention matrix. This method is called: Head Mixing Conv
They also have another solution where a single attention head simultaneously focuses on multiple directions. The method involves performing 1-to-1 attention calculations within a head, followed by an additional 2D convolution, which allows for consideration of nearby tokens. This enables a single attention head to simultaneously check if a row contains both ‘x’ and ‘y’. This method is called: Key-Query Conv
Their final solution employs both methods simultaneously, resulting in the ability to focus on relevant important information during the early attention phase, thus saving computational overhead required for subsequent inference and reducing parameter usage. Although adding convolution increases the parameter count (specifically the weights of the convolution kernels), the increase is minimal (approximately 0.001% as mentioned in the text). The addition of these clearly useful efficient weights is much more effective than simply increasing the model size (adding more standard attention parameters), leading to a reduction in the overall parameter count.
According to their experiments, MTA shows significant effectiveness in the following tasks:
- • LAMBADA: Predicting the last word of a text segment. Its design requires understanding the context of earlier parts, as merely looking at the last sentence is often insufficient for prediction.

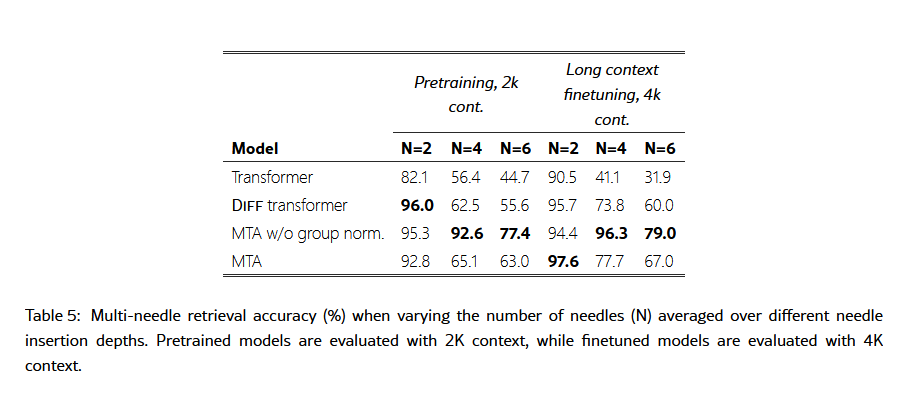
- • Needle-in-the-Haystack: In a long document (the “haystack”), a specific sentence or fact (the “needle”) is artificially inserted, requiring the model to find and restate this “needle”. This directly tests the model’s ability to locate information amidst a lot of interference. The paper also used a version with multiple needles to increase difficulty.
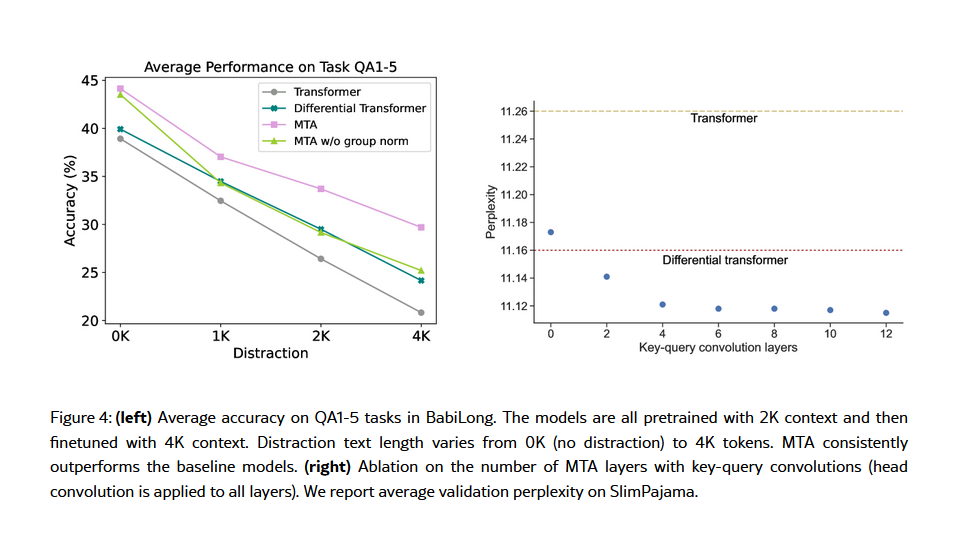
- • BabiLong: This is a variant of the bAbI reasoning task, where a large amount of irrelevant distracting text is inserted between the original short stories and questions, testing the model’s reasoning ability under long distances and interference.
A major limitation of MTA is that its attention computation can only consistently perceive information from other heads at the same position within a group, or tokens near a position within the same head (in the experiments, this was 6-11 nearby tokens). This means it cannot attend to two information points that span beyond this distance.