
Background
In mid-January, ZDI announced the rules for the 2017 competition, which included a substantial reward for teams that could break VMware and achieve virtual machine escape. VMware is no longer a new target; it was identified as a target in 2016.
As a target, VMware has undergone various attacks, with many points of attack available.
Interestingly, as early as between 2006 and 2009, virtual machine escape was achieved through vulnerabilities in D&D and C&P. However, in 2015, Kostya Kortchinsky and lokihardt discovered similar vulnerabilities in D&D and C&P. Since then, researchers have begun to study these codes more deeply.
From our perspective as observers, this phenomenon is thought-provoking. We wonder, how many vulnerabilities does VMware have? Which of them can we discover?
Although a series of vulnerabilities have been exposed, no team was able to successfully achieve virtual machine escape at Pwn2Own 2016. While traditional desktop software like VMware is not our research area, we are still very interested in finding vulnerabilities within VMware.
We decided to take on this challenge and see how difficult it is to uncover vulnerabilities in VMware. We set a plan to spend a month of our spare time searching for vulnerabilities. Although we did not complete this before Pwn2Own, we did discover some high-risk vulnerabilities and attempted to find exploitable attack points within VMware through these vulnerabilities.
Attack Surface
Previously unfamiliar with the details of VMware, we were initially unsure where to start implementing attacks. Would focusing on the internal details of instruction simulation be helpful? How many instructions are simulated, given that some CPUs support VT? To avoid colliding with others, aside from printing and interacting with host-client like D&D or C&P, what else is left?
The following is our research findings. As stipulated by Pwn2Own, all vulnerabilities must be exploitable by ordinary users within the virtual machine.
VMware Modules
Among the various modules of VMware, the GUI is the least scrutinized part. VMware has kernel modules on both the host and virtual machine side (at least vmnet/VMCI), thnuclnt (responsible for virtual printing), vmnet-dhcpd, vmnet-natd, vmnet-netifup, vmware-authdlaucher, vmnet-bridge, vmware-usbarbitrator, vmware-hostd, and the most important vmware-tools on the virtual machine side.
Almost all of these modules run as privileged processes, making them subjects of analysis for researchers. Virtual printing has been attacked multiple times.
vmnet-dhcpd caught our attention because it runs in root mode and is derived from ISC-DHCPD. More interestingly, vmware-dhcpd is based on isc-dhcp2. We began to target it for attacks.
However, after discovering publicly available vulnerabilities (CVE-2011-2749, CVE-2011-2748), we abandoned this idea. VMware had patched these vulnerabilities in the latest isc-dhcp to prevent exploitation.
Thus, we decided to perform fuzz testing on some small patches of vmware-dhcpd using QEMU and AFL. A month of fuzzing did not reveal any vulnerabilities. vmware-hostd is also an interesting process; it acts as a web server for virtual machine sharing and can be accessed from within the virtual machine. However, we decided to focus our efforts on studying VMware’s core components.
vmware-vmx is the primary virtual machine monitor module, running as a root/system process on the host, with some interesting features. In fact, it has two versions, vmware-vmx and vmware-vmx-debug.
If the debugging option is enabled in VMware’s settings, the latter is used. This is important because when we perform reverse engineering, starting from a version with a lot of debugging information is always much simpler. Perhaps this is not the most suitable method, but it is very effective. We will discuss this later.
RPC/RPCI
Have you ever wondered how the file drag-and-drop feature between the VM and the host is implemented? RPC plays a significant role in this. VMware internally provides an interface on port 0x5658 as a “backdoor.” Through this port, the virtual machine can communicate with the host via I/O instructions.
By passing a VMware-recognizable magic number through registers, VMware automatically parses the additional parameters. I/O instructions are typically privileged instructions, but this “backdoor” interface is an exception. Such exceptions are rare. When executing a backdoor I/O instruction, VMware performs a series of checks to determine whether the I/O instruction comes from a privileged virtual machine.
On top of this “backdoor” interface, VMware uses RPC services to exchange data between the host and client. On the client side, vmware-toolsd executes “backdoor” commands while utilizing RPC services.
This is why you can only use features like drag-and-drop files after installing vmware-toolsd on the client. The combination of kernel driver and user-space functionality enables this feature.
In the initial “backdoor” interface, data could only be passed through registers, which would slow down the process when transferring large amounts of data. To address this issue, VMware introduced another port (0x5659) to achieve high-bandwidth “backdoor” communication. In fact, this port is used by RPC.
By passing a data pointer, vmware-vmx can directly call read/write APIs without repeatedly invoking the IN instruction, which Derek once discovered a very interesting vulnerability within this functionality.
The RPC interface provides the following functionalities:
-
Open channel
-
Send command length
-
Send data
-
Receive reply length
-
Receive data
-
End interaction
-
Close channel
You may wonder how to prevent processes from disrupting RPC interactions. When establishing a channel, VMware generates two cookie values to send and receive data. Clearly, these two cookies are generated in a secure manner. Since these two cookies are two 32-bit unsigned integers, they cannot be compared using memcmp and other methods.
At a higher level, VMware also uses RPC commands to handle DnD, CnP, Unity, and other events. Some commands can only be executed under privileged users in the virtual machine. On the virtual machine side, vmware-tool or open-vm-tools provides rpctool to interact with the API. A simple example of saving and retrieving virtual machine information is as follows:
rpctool ‘info-set guestinfo.foobar baz’rpctool ‘info-get guestinfo.foobar’ -> baz
Information is stored in vmware-vmx and subsequently extracted. The details of how data is stored are beyond the scope of this article. VMware internally uses VMDB, a database for keyword storage, which has callback functions for specific data.
However, the number of RPC commands that can be called in non-privileged virtual machines is limited. We cannot provide a complete list of RPC commands because it varies with versions and operating systems. The simplest way to obtain the command list is to dump it from memory.
Fortunately, the Linux version of vmware-vmx provides symbols, making it easy for us to obtain.
The most interesting attack points are DnD, CnP, and Unity. However, we did not study them for two reasons. First, lokihardt successfully exploited them at Pwnfest. More importantly, at Pwn2Own 2016, using vulnerabilities in Unity and virtual printing was not allowed.
Due to this potential risk, we expect that VMware and ZDI will be more interested in virtual machine escapes unrelated to isolation settings in 2017. Although Pwn2Own 2017 did not provide details on the competition rules, we were unwilling to take on the potential risk. Ultimately, we decided not to dig into vulnerabilities in RPC.
Nevertheless, it is worth mentioning that there are many exploitable points in RPC, as it provides the ability to manipulate heap memory.
Virtualization of Peripheral Devices
Are there any other attack points? VMware’s core code implements instruction virtualization while also providing various virtual peripheral devices for the client. These devices include network, USB, Bluetooth, hard disk, graphics interfaces, etc.
User-space services, virtual machine kernel drivers, and vmware-vmx work together to provide services for virtualized devices. For example, VMware provides an SVGA graphics card adapter within the virtual machine as a PCI display device driver.
On Linux, modifying the X code of the vmwgfx kernel module establishes an interface layer for SVGA3D/2D in vmware-vmx. We believe that the default-enabled virtualized peripheral devices in modern operating systems present a broad attack surface. Therefore, we searched for modules that are default-enabled, have a wide attack surface, and can be fuzzed. Ultimately, we chose the graphics interface.
Searching for Vulnerabilities in the Renderer
Since the competition platform is VMware Workstation on Windows 10, we decided to study the graphics interface on Windows rather than Linux. Notably, the open-source implementation of VMware graphics drivers in Gallium’s svga code greatly assisted us in analyzing the relevant parts of vmware-vmx. Similarly, Microsoft’s graphics device driver routines were also very helpful in understanding how Windows drivers work.
Others have previously attacked SVGA commands, and we decided to delve deeper into the specific functionalities of this complex module to search for vulnerabilities: the translation module of the GPU renderer. An important reason for choosing the renderer bytecode over SVGA commands is that the renderer bytecode can be provided from within the virtual machine.
On Linux and Mac, the renderer is implemented using OpenGL. On Windows, it is implemented using Direct3D. Since VMware needs to support different virtual machine operating systems, various renderer codes must be translated into host rendering behavior. We believe that in such a highly complex module, a variety of vulnerabilities are likely to arise.
Our initial analysis was based on VMware Workstation 12.5.3.
Architecture
VMware has two implementations of GPU. One is VGPU9 (corresponding to DirectX 9.0), used on Linux virtual machines and older versions of Windows virtual machines. The other is VGPU 10, used on Windows 10.
For 3D accelerated graphics interfaces, VMware uses WDDM (Windows Display Driver Model) drivers on Windows 10 virtual machines. This driver consists of user and kernel parts. The user part is vm3dum64_10.dll, and the kernel part is vm3dp.sys. When using the Direct3D renderer, the bytecode undergoes multiple translations.
Since VMware provides virtual 3D support, these bytecodes cannot be used directly. They will be further translated, and the Direct3D API needs to use the corresponding renderer implementation. Therefore, the user-space driver implements callback functions stored in the D3D10DDI_DEVICEFUNC structure. They translate the bytecode into the corresponding API.
In this case, VMware SVGA3D defines the API and sets the renderer. When processing the renderer bytecode, the user-space driver calls the pfnRenderCB callback function provided by the kernel driver.
Any Windows program requiring a GPU renderer must use the Windows D3D11 API. These APIs are responsible for translating the renderer bytecode in the file and setting it for different types of renderers. The general translation process is illustrated in the following diagram.
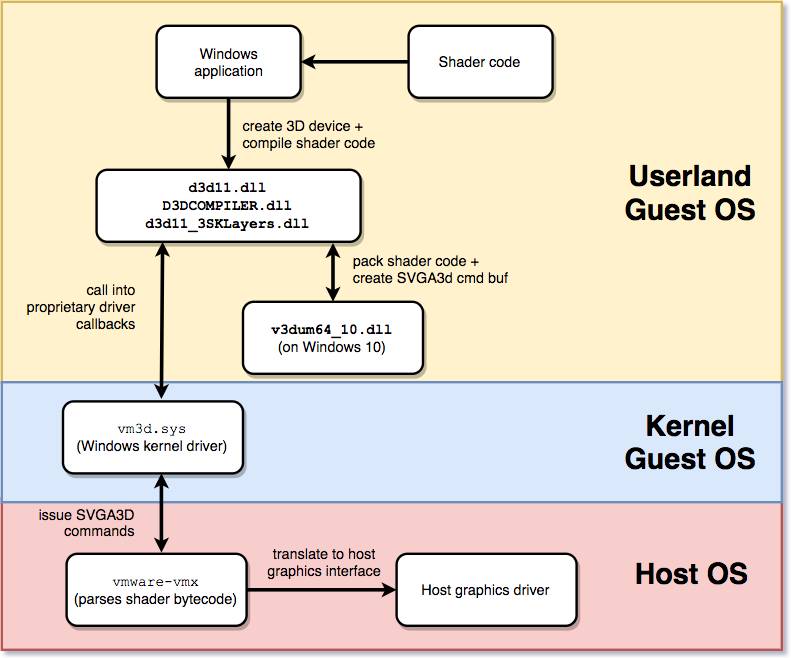
This process involves many other details, and a large number of D3D11 APIs are involved. Interested readers can refer to the Direct3D11 examples provided by Microsoft and use Windbg to trace and debug it. (Using the wt command in Windbg)
0:000> x /D /f Tutorial03!i* A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 00000000`00da1900 Tutorial03!InitDevice (void)00000000`00da28f0 Tutorial03!InitWindow (struct HINSTANCE__ *, int)00000000`00da3630 Tutorial03!invoke_main (void)00000000`00da3620 Tutorial03!initialize_environment (void)00000000`00da4680 Tutorial03!is_potentially_valid_image_base (void *)00000000`00da637a Tutorial03!IsDebuggerPresent (<no parameter info>)00000000`00da63c8 Tutorial03!InitializeSListHead (<no parameter info>)00000000`00da63aa Tutorial03!IsProcessorFeaturePresent (<no parameter info>)0:000> bp Tutorial03!InitDevice0:000> gBreakpoint 0 hitTutorial03!InitDevice:00da1900 55 push ebp0:000:x86> wt -l 8Tracing Tutorial03!InitDevice to return address 00da2dfe 259 0 [ 0] Tutorial03!InitDevice 100 0 [ 1] USER32!GetClientRect
…
Constructing Input Data for the Renderer
When interacting with VMware’s renderer, understanding the principles of the renderer is crucial.
Writing a DirectX renderer requires using a high-level rendering language (HLSL). Use the D3D11 API or the fxc.exe program to compile it into bytecode. Depending on the renderer model, HLSL provides different types of rendering features.
The HLSL compilation result is presented in the form of assembly bytecode for the renderer model. VMware currently supports SM3 and SM4 internally but does not support SM5 and SM6. This is important for our reverse engineering of the translation unit in vmware-vmx.
Unfortunately, on the Windows platform, there are no other tools to generate renderer bytecode besides using HLSL. Therefore, constructing precise inputs to trigger vulnerabilities becomes quite challenging. CSO files also need to fix checksum values. The function that checks the checksum is D3D11_3SDKLayers!DXBCVerifyHash.
To provide VMware with arbitrary renderer bytecode input, we used the powerful Frida tool to hook and modify the renderer bytecode. When vm3dum64_10.dll places the compiled bytecode into memory, we change it to any bytecode we want to input. Through reverse engineering, we identified the corresponding memmove() location and hooked it.
Below is a part of our Frida code.
var vm3d_base = Module.findBaseAddress(“vm3dum64_10.dll”);console.log(“base address: ” + vm3d_base); function ida2win(addr) { var idaBase = ptr(‘0x180000000’); var off = ptr(addr).sub(idaBase); var res = vm3d_base.add(off); console.log(“translated ” + ptr(addr) + ” -> ” + res); return res;} function start() { var memmove_addr = ida2win(0x180012840); var setShader_return = ida2win(0x180009bf4); Interceptor.attach(memmove_addr, { onLeave : function (retval) { if (!this.hit) { return; } Memory.writeU32(this.dest_addr.add(…), …); …. }, onEnter : function (args) { var shaderType = Memory.readU8(args[1].add(2)); if (!this.returnAddress.compare(setShader_return)) { if (shaderType != 1) { return; } this.dest_addr = args[0]; this.src_addr = args[1]; this.len = args[2].toInt32(); this.hit = 1; … });}
The above code uses Frida to hijack the control flow of memmove() in vm3dum64_10. Whenever the code enters memmove(), the return value is compared with setShader(). If they match, the bytecode in memory is modified before exiting memmove().
During our research, it is worth noting that we learned that Marco Grassi and Peter Hlavaty had demonstrated fuzzing of the renderer. They mentioned that VMware provided a toolkit for the renderer and some examples. This served as the basis for their fuzzing, and their research results can be found here.
Searching for Vulnerabilities
VMware is a massive software, and we do not know how to identify the renderer’s translation functions from vmware-vmx. There are only two ways: one is to directly identify the renderer’s translation unit. The second is through the SVGA3D command processing functions, which are usually the following: DXDDefine, DXBindShader, DefineSurface.
Searching for strings in the binary file is relatively straightforward, and the following image shows the strings used in SVGA3D commands.
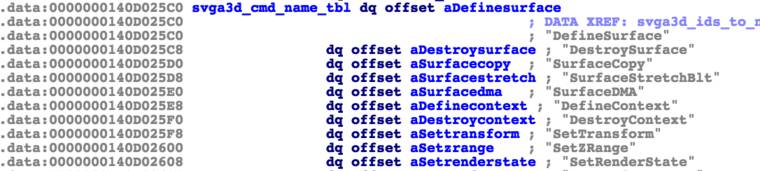
Using these strings does not directly find the corresponding processing functions, but through X references, we can find another table in memory.

By marking them with the offsets from the string table, we can find the direct processing functions. Since they are ultimately used to control the operations of the renderer, following these functions can lead us to the parsing and translation code. In the internal implementation, the kernel driver and vmware-vmx are implemented using a first-in-first-out data structure to push SVGA3D commands onto the heap for delivery to the monitor. Then these modules extract the data and process it further.
There are two ways to directly find the renderer’s code. The first is to use the strings in vmware-vmx-debug to directly find the parsing and translation code. We began to follow the cross-references of the strings “shaderParseSM4.c” and “shaderTransSM4.c.” However, auditing the debug version of the code has a significant drawback: the debug version has many checking functions that are not present in the release version.
We are unclear whether this is a design flaw in VMware during the auditing process of vmware-vmx code. In the debug version, there are many strict security checks in the parsing and translation modules, which are absent in the release version.
Thus, we utilized the immediate parameters found in the debug version to locate them in the non-debug version, greatly enhancing the readability of the IDA code. Thanks to the mesa driver, we were able to know what we needed to search for.
For example, the definitions regarding VGPU10 in the mesa driver were very helpful for our analysis.
When vmware-vmx needs to convert the renderer code of the virtual machine into the renderer code of the host, it first parses the renderer bytecode packaged by the internal library functions of the virtual machine. Due to the lack of information on the underlying renderer bytecode, reverse engineering this parsing function and constructing various inputs took us a lot of time.
The initial parsing process was relatively simple; the ParserSM4() function merely saved the parameters.
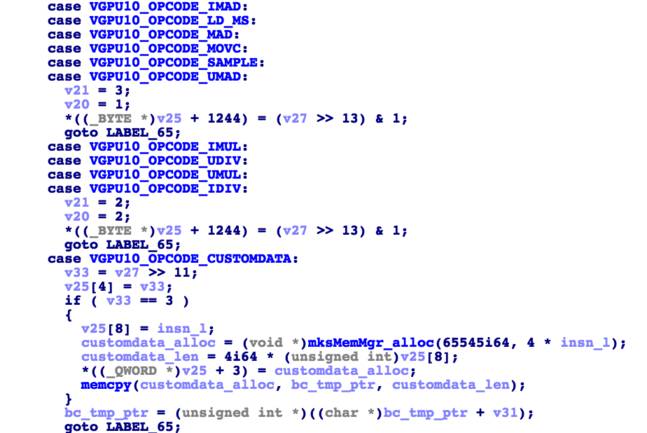
When the parser parses the bytecode, similar to other parsers, the length of the renderer code tells the parser when to stop parsing. Each bytecode has a type, an instruction length, and a value. Specifically, the 0:10 bits of each bytecode header determine the type of bytecode, the 11:23 bits encode the bytecode data, the 30:24 bits record the data length of the bytecode, and the 31st bit indicates whether the bytecode is extended (usually not).
Since most of the values included in the bytecode are one byte in length, the parser copies this byte’s value into an unknown data structure. The VGPU10_OPCODE_CUSTOMDATA mentioned above is an exception because it contains a buffer, as described by dcl_immediateConstantBuffer.
As mentioned above, we are unclear about the internal data structures used. However, this is irrelevant to finding vulnerabilities in the translation unit, as the offsets used in the data structure are the same. Therefore, if we know what the input bytecode is, auditing the binary code of TransSM4 becomes convenient.
Overall, this is still a very time-consuming step. First, we began without understanding the renderer and VMware’s graphics interface virtualization knowledge, which took a lot of time to find key points. Second, the lack of tools to directly generate sm4 bytecode meant we could only use Frida to dynamically hook the bytecode in functions.
Finally, understanding the details and principles of SM4 instructions is also a massive project. Besides the debugger, there are also some tools that can help us with reverse engineering. The ASSERT assertions in the debug version of vmware-vmx can help us understand runtime errors.
ParseSM4() provides a disassembly function for the renderer, which can be used to extract the renderer bytecode and log it in VMware’s logs.
Results
Now let’s take a look at some of the results we discovered after manual reverse engineering. On March 17, 2017, at Pwn2Own, we submitted these vulnerabilities and PoCs to ZDI.
1. Heap Overflow When Translating dcl_immediateConstantBuffer Bytecode
When parsing a token named VGPU10_OPCODE_CUSTOMDATA (which defines a buffer), the following pseudocode is executed:
case VGPU10_OPCODE_CUSTOMDATA: v41 = v23 >> 11; *(_DWORD *)(_out_p_16_ptr + op_idx + 16) = v41; if ( (_DWORD)v41 == VGPU10_CUSTOMDATA_DCL_IMMEDIATE_CONSTANT_BUFFER ) { *(_DWORD *)(_out_p_16_ptr + op_idx + 32) = insn_l; custom_data_alloc = (void *)mksMemMgr_alloc(v41, 0x10009u, 4LL * (unsigned int)insn_l);// int overflow safe *(_QWORD *)(_out_p_16_ptr + op_idx + 24) = custom_data_alloc; memcpy(custom_data_alloc, bc_tmp_ptr, 4LL * *(unsigned int *)(_out_p_16_ptr + op_idx + 32)); v37 = 0; insn_start = (int *)bc_tmp_ptr; }
At this point, insn_l represents a 32-bit constant encoded in user data instructions, which general rendering instructions do not typically use, making this a special case. This number indicates the length of the user data block. The code does not impose any restrictions on this length.
mksMemMgr_alloc internally calls calloc to allocate a heap of length 159384. The calloc function is provided by msvcr90.dll. We found that msvcr90.dll is always mapped to the lowest end of 4G memory.
On Windows 10, the calloc function allocates memory in the NT heap through RtlAllocateHeap. We will use this memory in outbuf, which is entirely controlled by the attacker.
After allocating this memory, the translation phase ends. When encountering the VGPU10_OPCODE_CUSTOMDATA token, memcpy will be called without further security checks.
result = memcpy(outbuf + 106228, custom_data_alloc, 4 * len);
custom_data_alloc is the buffer we allocated in the parsing step above. This allows us to write carefully crafted data into the header of the adjacent heap block. These adjacent heap blocks were previously parsed bytecode, which were also allocated in this memory area.
2. Heap Out-of-Bounds Write Vulnerability When Translating dcl_indexableTemp Bytecode
When processing the dcl_indexabletemp instruction, the renderer parsing module will call the following pseudocode:
case VGPU10_OPCODE_DCL_INDEXABLE_TEMP: *(_DWORD *)(_out_p_16_ptr + op_idx + 16) = *insn_start;// index *(_DWORD *)(_out_p_16_ptr + op_idx + 20) = insn_start[1];// index + value for array write operation in Trans bc_tmp_ptr = insn_start + 3; *(_DWORD *)(_out_p_16_ptr + op_idx + 24) = insn_start[2];
In the above pseudocode, part of the instruction is written to op_idx, and these values will be used in the subsequent translation module. During the parsing process, there are no restrictions on these values.
The following code represents the translation process:
case VGPU10_OPCODE_DCL_INDEXABLE_TEMP: v87 = *(_DWORD *)(bytecode_ptr + op_idx + 24); svga3d_dcl_indexable_temp((__int64)__out, *(_DWORD *)(bytecode_ptr + op_idx + 16),// idx *(_DWORD *)(bytecode_ptr + op_idx + 20),// val (1 << v87) – 1); // val2
We can see that when calling svga3d_dcl_indexable_temp(), the same offset values (20, 16, 24) are used. idx and val are directly controlled by the attacker. The fourth parameter is derived from the third DWORD operation above ((1<<val2)-1).
Entering the svga3d_dcl_indexable_temp() function:
__int64 __fastcall svga3d_dcl_indexable_temp(__int64 a1, unsigned int idx, int val, char val2){ __int64 result; // rax@5 const char *v5; // rcx@7 const char *v6; // rsi@7 signed __int64 v7; // rdx@7 *(_DWORD *)(a1 + 8LL * idx + 0x1ED80) = val; *(_BYTE *)(a1 + 8LL * idx + 0x1ED84) = val2; *(_BYTE *)(a1 + 8LL * idx + 0x1ED85) = 1; result = idx; return result;}
In the above code, a1 is the heap block used during the translation process, which is the same as the user data block we discussed earlier. With a base address of 0x1ed80, we can write a 32-bit DWORD value to any offset.
In summary, this vulnerability allows us to write a DWORD value to any address in the previously mentioned heap structure. It can also write two bytes controlled by val (the remaining two bytes are 0).
3. Stack Out-of-Bounds Write Vulnerability When Translating dcl_resource Bytecode
During the translation process when handling the dcl_resource instruction, the following code will be executed:
int hitme[128]; // [rsp+1620h] [rbp-258h]@196 int v144; // [rsp+1820h] [rbp-58h]@204 char v145; // [rsp+1824h] [rbp-54h]@303 bool v146; // [rsp+1830h] [rbp-48h]@14 char v147; // [rsp+1831h] [rbp-47h]@14 int v148; // [rsp+1880h] [rbp+8h]@1 __int64 v149; // [rsp+1890h] [rbp+18h]@1 __int64 v150; // [rsp+1898h] [rbp+20h]@14 … case VGPU10_OPCODE_DCL_RESOURCE: v87 = sub_1403C2200(*(_DWORD *)(v14 + 32)); v88 = sub_1403C2200(*(_DWORD *)(v14 + 28)); v89 = sub_1403C2200(*(_DWORD *)(v14 + 24)); v90 = sub_1403C2200(*(_DWORD *)(v14 + 20)); sub_1402FCF10(&v107, (__int64)outptr, *(_DWORD *)(v14 + 80), v86, v90, v89, v88, v87); v11 = 0i64; hitme[(unsigned __int64)*(unsigned int *)(v14 + 80)] = *(_DWORD *)(v14 + 16);
We did not follow up on the details of the sub_1403c2200() function, as it is irrelevant because it does not affect the stack structure. The offset (v14+80) is completely controlled by the input renderer bytecode. However, the value being written is subject to certain restrictions. It can only be between 0-31.
This means we can write many aligned DWORDs. We use the plural form here because this vulnerability can be triggered multiple times, allowing us to write DWORD values from hitme to addresses up to 4G.
The exploitability of this vulnerability depends on the version of VMware and the operating system. Clearly, the stack layout varies across different versions or operating systems.
4. Insecure Memory Mapping Leading to DEP Bypass
When the vmware-vmx supervisory process starts, it creates several memory mappings. Surprisingly, one of these memory mappings is created with read, write, and executable permissions. This remains the case throughout the lifecycle of the process. There is only one such memory mapping. The memory mapping created here is the first page of the data segment of the vmware-vmx process.
7ff7`36b53000 7ff7`36b54000 0`00001000 MEM_IMAGE MEM_COMMIT PAGE_EXECUTE_READWRITE Image [vmware_vmx; “C:\Program Files (x86)\VMware\VMware Workstation\x64\vmware-vmx.exe”] 0:018> dq 7ff7`36b53000 L 0n1000/800007ff7`36b53000 ffffffff`ffffffff 00000001`fffffffe00007ff7`36b53010 00009f56`1b68b8ce ffff60a9`e497473100007ff7`36b53020 00007ff7`36b54000 00007ff7`36b5400000007ff7`36b53030 00007ff7`36b54000 00007ff7`36b5400000007ff7`36b53040 00007ff7`36b54000 00000000`0000000000007ff7`36b53050 00007ff7`36b54000 00007ff7`36b5400000007ff7`36b53060 00007ff7`36b54000 00007ff7`36b5400000007ff7`36b53070 00007ff7`36b54000 00007ff7`36b5400000007ff7`36b53080 00007ff7`36b54000 00007ff7`36b5400000007ff7`36b53090 00007ff7`36b54000 00007ff7`36b54000
Clearly, this significantly lowers the risk of virtual machine escape vulnerabilities, as it provides a perfect area for executing shellcode.
.data:0000000140B33000 _data segment para public ‘DATA’ use64…0000000140B33000 FF FF FF FF FF FF FF FF FE FF FF FF 01 00 00 00 …………….0000000140B33010 32 A2 DF 2D 99 2B 00 00 CD 5D 20 D2 66 D4 FF FF 2..-.+…] .f…0000000140B33020 18 0A 76 40 01 00 00 00 08 0A 76 40 01 00 00 00 ..v@……v@….0000000140B33030 F8 09 76 40 01 00 00 00 E8 09 76 40 01 00 00 00 ..v@……v@….0000000140B33040 D8 09 76 40 01 00 00 00 00 00 00 00 00 00 00 00 ..v@…………0000000140B33050 90 09 76 40 01 00 00 00 40 09 76 40 01 00 00 00 ..v@…[email protected]@….0000000140B33060 F0 08 76 40 01 00 00 00 A0 08 76 40 01 00 00 00 ..v@……v@….0000000140B33070 60 08 76 40 01 00 00 00 20 08 76 40 01 00 00 00 `.v@…. .v@….0000000140B33080 F0 07 76 40 01 00 00 00 A0 07 76 40 01 00 00 00 ..v@……v@….0000000140B33090 50 07 76 40 01 00 00 00 00 07 76 40 01 00 00 00 P.v@……v@….
As shown, the memory is allocated with read, write, and executable permissions. The dump in Windbg is merely to illustrate that it corresponds with the data segment in IDA.
Conclusion
The first two vulnerabilities are 0-day vulnerabilities in version 12.5.3, and even after the competition, version 12.5.4 has not patched these vulnerabilities.
Shortly after the release of version 12.5.4, VMware released VMSA-2017-0006, which patched these two heap-related vulnerabilities. The details in the version update are vague, and we do not know whether these vulnerabilities have been genuinely patched.
Similarly, the debug version of vmware-vmx has error-checking mechanisms that are not present in the product version. According to ZDI, this does not conflict with vulnerabilities submitted by others; VMSA-2017-006 only mentions reports from ZDI.
As a result, we do not know whether these vulnerabilities have CVE IDs or whether other researchers have discovered them.
It is worth noting that the ASSERT assertions also affect other SM4 instructions. We are confident that until version 12.5.5, at least dcl_indexRange and dcl_constantBuffer have similar heap out-of-bounds write vulnerabilities.
The dcl_resource vulnerability has not been patched in version 12.5.5.
Currently, we believe that the initial patch was aimed at internal code refactoring rather than addressing the vulnerabilities we submitted. Because the patches in the debug version are the same as in the release version, using assert assertions instead of error handling functions. Therefore, we can still exploit these vulnerabilities to compromise VMware.
The PoCs for the vulnerabilities mentioned in this article can be found at https://github.com/comsecuris/vgpu_shader_pocs.
Others
Before concluding this article, we would like to share some findings from our work that we hope will be helpful to you. Here are a few points:
-
The Difficulty of Reverse Engineering in Different Environments
When we reverse-analyzed vmware-vmx, some strange inline function characteristics in the Linux version significantly increased the difficulty of reverse engineering (compared to Windows and Mac). After comparison, we found that the Windows version of vmware-vmx is the most suitable for reverse analysis.
The symbol information of the Linux version of vmware-vmx greatly aids reverse engineering.
-
Settings
VMware provides very useful settings options for interacting with the renderer. We found mks.dx11.dumpShaders, mks.shim.dumpShaders, and mks.gl.dumpShaders to be very useful. There are many similar settings.
-
PIE
In Linux, if the PIE option is removed from the vmware-vmx ELF file, vmware-vmx will not function properly. In Mac, using the change_macho_flage.py script can successfully handle the relocation of vmware-vmx, making debugging more convenient.
-
Binary Translation Module
After completing the above analysis, we are still pondering where the code simulating x86 instructions in vmware-vmx is located. We initially thought it would be easy to find this part of the code; however, so far, we have not found the relevant code. One possibility is hardware virtualization. However, depending on the settings and architecture, VMware can run in various modes. This part of the code must be located somewhere.
binwalk vmware-vmx.exe DECIMAL HEXADECIMAL DESCRIPTION——————————————————————————–0 0x0 Microsoft executable, portable (PE)…13126548 0xC84B94 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)13126612 0xC84BD4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)14073118 0xD6BD1E Unix path: /build/mts/release/bora-4638234/bora/vmcore/lock/semaVMM.c14256073 0xD987C9 Sega MegaDrive/Genesis raw ROM dump, Name: “tSBASE”, “E_TABLE_VA”,14283364 0xD9F264 Sega MegaDrive/Genesis raw ROM dump, Name: “ncCRC32B64”, “FromMPN”,14942628 0xE401A4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)14949876 0xE41DF4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)14954108 0xE42E7C ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)14960892 0xE448FC ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
14991124 0xE4BF14 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
The results of binwalk analyzing the ELF look strange, and there are certainly some errors. We temporarily ignore these errors. We noticed that there is an ELF header in memory. Using the binwalk tool (which is typically not used to analyze PE or ELF files), we discovered some interesting things.
A maximum ELF file looks very interesting because it contains a massive function, and more importantly, it also has symbols.
To our surprise, this embedded ELF contains x86 disassembled translation units. We are curious about how it works, but we did not delve deeper, as this is not our goal; however, it is a very interesting research direction.
Conclusion
Unfortunately, at Pwn2Own, we were unable to achieve the original goal of complete virtual machine escape. However, we are still satisfied with completing our planned timeline. We believe that VMware is not only an interesting target for vulnerability digging but also that VMware, despite implementing virtual machine monitoring functions, is not much different from traditional desktop programs.
Based on our discovery and exploration of attack points, we believe that VMware, as a highly complex and widely used software, still has many unexplored and exploitable attack points. For example, we only analyzed the surface structure of the renderer translation unit.
The internal complex implementation of the renderer functionality still needs analysis. Similarly, other components of VMware have also been attacked. After reviewing the code we analyzed and the past security recommendations made by VMware, recent security defenses have shifted from passive to active.
In addition to core components, there are many other components worth studying. For instance, vmware-hostd (an SSL-supported web server). We hope to further investigate virtual machine security issues and welcome others to research as well.
This article was compiled by jackandkx from the Kanxue Forum, sourced from comsecuris@Nico, Ralf.
Please indicate the source from the Kanxue community when reprinting.
Popular Reads
-
An Experience of Removing Ad Pop-ups
-
New Linux/AES.DdoS IoT Malware (part 1)
-
Predicting, Decoding, and Abusing WPA/802.11 Group Keys (Part 1)
-
Predicting, Decoding, and Abusing WPA/802.11 Group Keys (Part 2)
-
[Essential for Identifying Malicious Trojans] Using Command Line and Python with YARA Rules
Click to read the original article/read,
More valuable content awaits you~
