Article Summary
The core content of this article introduces an efficient architecture design named LitePose for real-time multi-person 2D human pose estimation on resource-constrained edge devices.
1. Background and Challenges:
– Human pose estimation plays a crucial role in many visual applications that require understanding human behavior.
– Existing HRNet-based pose estimation models are computationally expensive and difficult to deploy on resource-constrained edge devices.
2. Research Objectives:
– Design an efficient architecture for real-time multi-person pose estimation on edge devices while maintaining good performance.
3. Method Introduction:
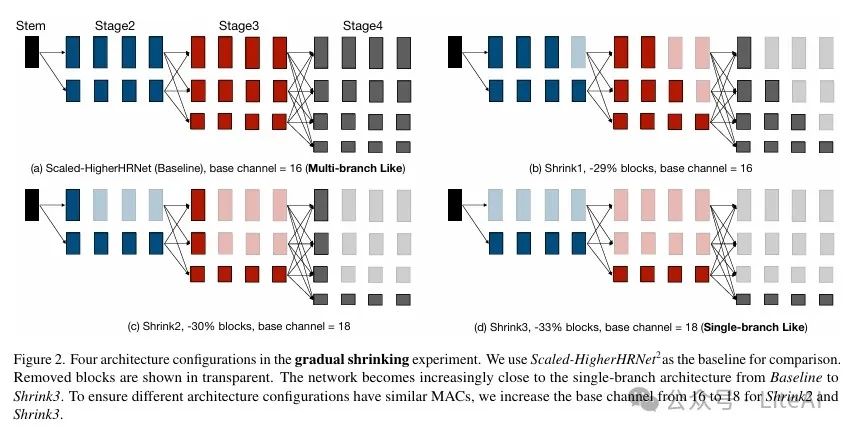
– Gradual Shrinking Experiment: By gradually reducing the depth of the high-resolution branch, it was found that the model performance improves in low-computation areas.
– LitePose Architecture: A single-branch architecture named LitePose was designed, enhancing model capability through the fusion of deconvolution heads and large kernel convolutions.
– Fusion Deconv Head: Eliminates redundancy in the high-resolution branch, allowing for low-overhead scale-aware feature fusion.
– Large Kernel Convs: Significantly improves model capability and receptive field while maintaining low computation costs.
4. Experimental Results:
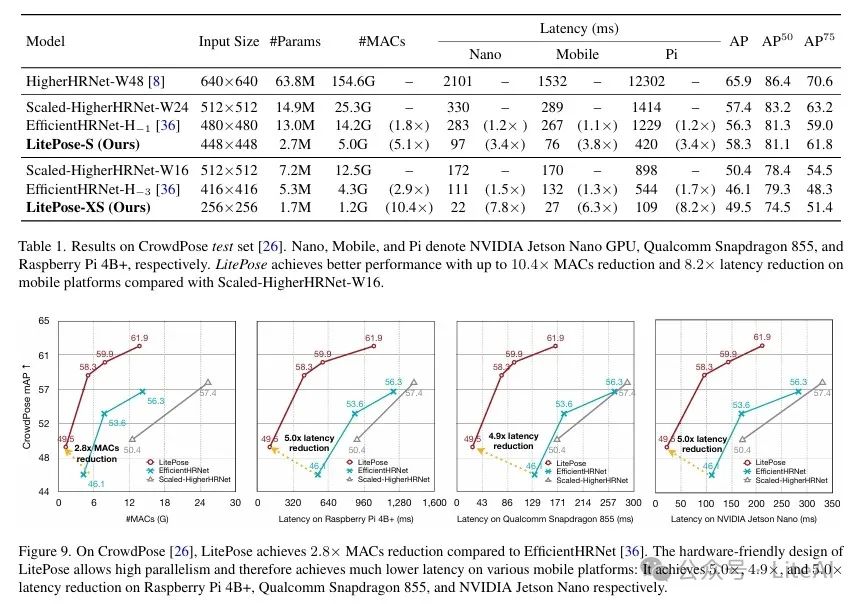
– On the CrowdPose dataset, LitePose achieved a 2.8x reduction in MACs and up to a 5.0x reduction in latency while performing better.
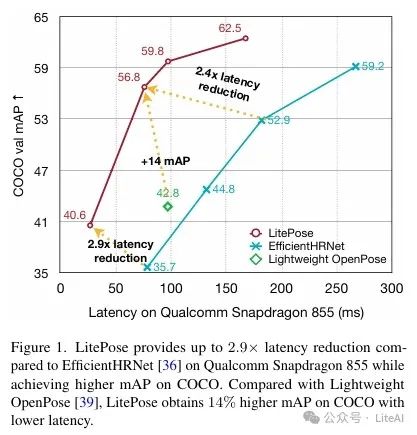
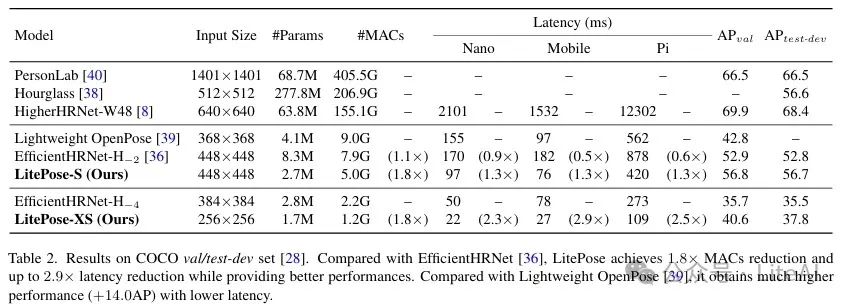
– On the COCO dataset, compared to EfficientHRNet, LitePose achieved a 2.9x reduction in latency while providing better performance.
5. Contribution Summary:
– Revealed the redundancy of high-resolution branches in low-computation areas.
– Proposed the LitePose architecture and two techniques to enhance its capability: fusion deconvolution heads and large kernel convolutions.
– Demonstrated the effectiveness of LitePose through extensive experiments on two benchmark datasets.

Article link: https://arxiv.org/pdf/2205.01271
Project link: https://github.com/mit-han-lab/litepose
TL;DR
Article Methods
1. Method Overview:
– LitePose designed an efficient single-branch architecture by eliminating redundancy in the high-resolution branch.
– Introduced two techniques, fusion deconvolution heads and large kernel convolutions, to enhance model capability.
2. Key Technologies:
– Gradual Shrinking Experiment:
– By gradually reducing the depth of the high-resolution branch, it was found that model performance improves in low computation areas.
– This indicates that single-branch architectures are more efficient in low computation areas.
– Fusion Deconv Head:
– Removes redundancy in the high-resolution branch, allowing for low-overhead scale-aware feature fusion.
– Directly utilizes low-level high-resolution features for deconvolution and final prediction, avoiding redundancy in multi-branch HR fusion modules.
– Large Kernel Convs:
– Large kernel convolutions provide a more significant performance boost in pose estimation tasks compared to small kernel convolutions.
– Using a 7×7 large kernel convolution, the mAP on the CrowdPose dataset improved by 14% with a 25% increase in computation cost.
Experimental Results
1. CrowdPose Dataset:
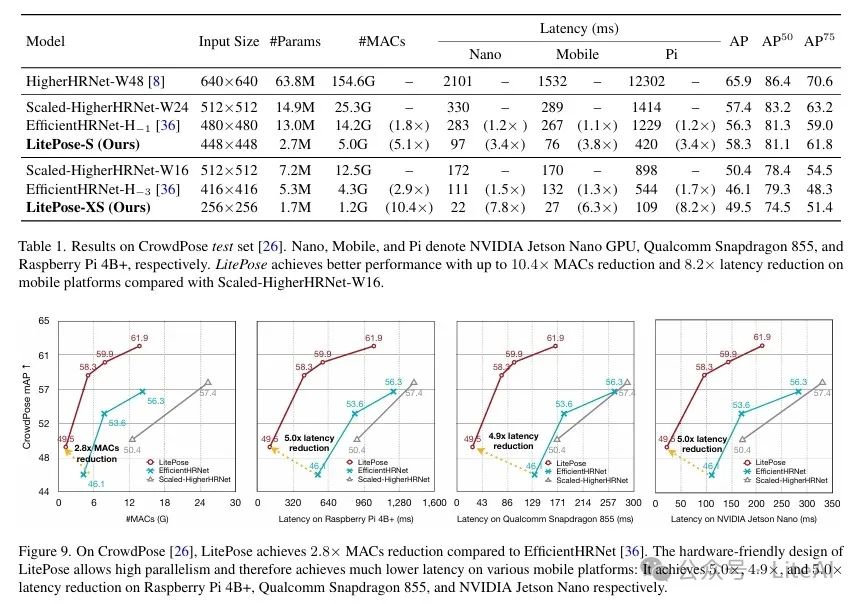
– Model Performance: LitePose achieved better performance than existing methods on the CrowdPose dataset.
– Computational Efficiency: Compared to HRNet-based methods, LitePose achieved a 2.8x reduction in MACs and up to a 5.0x reduction in latency.
– Specific Data:
– HigherHRNet-W48: 63.8M parameters, 154.6GMACs, AP of 65.9.
– LitePose-S: 2.7M parameters, 5.0GMACs, AP of 58.3.
– Latency: On Qualcomm Snapdragon 855, Raspberry Pi4B+, and NVIDIA Jetson Nano GPU, LitePose achieved latency reductions of 5.0×, 4.9×, and 5.0× respectively.
2. Microsoft COCO Dataset:
– Model Performance: LitePose also performed excellently on the COCO dataset, outperforming HRNet-based methods.
– Computational Efficiency: Compared to EfficientHRNet, LitePose achieved a 1.8x reduction in MACs and up to a 2.9x reduction in latency.
– Specific Data:
– HigherHRNet-W48: 63.8M parameters, 155.1GMACs, AP of 69.9.
– LitePose-S: 2.7M parameters, 5.0GMACs, AP of 56.8.
– Latency: On Qualcomm Snapdragon 855, Raspberry Pi4B+, and NVIDIA Jetson Nano GPU, LitePose achieved latency reductions of 2.9×, 2.5×, and 2.3× respectively.
3. Comparison with Lightweight OpenPose:
– Performance: LitePose outperformed Lightweight OpenPose by 14.0 AP on the COCO dataset.
– Latency: LitePose has lower latency on mobile platforms.
4. Ablation Study:
– Large Kernel Convolutions: The 7×7 large kernel convolution improved mAP on the CrowdPose dataset by 14% with a 25% increase in computation cost.
– Fusion Deconv Head: On the CrowdPose dataset, the fusion deconv head provided a +7.6 AP performance boost with minimal increase in computation cost.
– Neural Architecture Search: Through neural architecture search, LitePose achieved a +2.2 AP performance improvement on the CrowdPose dataset.
Final Thoughts
Scan to add me, or add WeChat (ID: LiteAI01) for technical, career, and professional planning exchanges, note “Research direction + School/Region + Name”