Introduction
When AI first emerged, it was simply a chatbot interface. Over time, it has gradually added functionalities, such as internet connectivity, tool configuration, and custom workflows for agents. With agents, AI can be applied to various real-world business scenarios, marking a process of gradual evolution and implementation.
For instance, AI programming, which we programmers are most familiar with, is a successful application of AI agents that has become widespread in just the past year. Platforms like Dify and Coze allow users to manually define workflows, configure personalized AI agents, and publish them for use.
At the end of August, the government issued the “Artificial Intelligence +” action plan, indicating that AI applications in both China and globally will continue to develop and flourish over the next decade.
I personally will continue to delve into the field of AI agents, empowering areas I specialize in, such as interviews, coding practice, resumes, and tutorials, using AI to increase efficiency and serve more users more quickly.
This article provides an overview of the knowledge required for developing AI agents from the perspective of frontend developers, for your reference.
LLM
The foundation of AI is the LLM (Large Language Model), such as the well-known ChatGPT, Gemini, Claude, Deepseek, Qwen, Grok, and Llama. The common usage is to call their APIs online (which may require purchasing tokens), but they can also be deployed locally for internal use.
What is LLM? The core understanding of all current LLMs is simply: predicting the next word.
LLMs are not “smart” and cannot understand human language; rather, they are “fed the entire internet’s data and then wildly complete it.” The better you design it, the more accurately it completes. The parameters of an LLM are like “memory units,” similar to human neurons; the more parameters (higher training and operational costs), the more “intelligent” it becomes, and the more accurate its completions are.
For example, if your input is “monkeys like to eat,” the LLM will calculate from its vast training data and find a list where “banana” has the highest probability, and it will return “banana.” This includes writing poetry, coding, and drawing, which are also based on prompt inputs to complete content, but not just a word, rather a structured output trained from massive data.
Agents and tools also represent a form of “completion,” guessing which tools to use based on prompts (each tool has descriptions and parameter structures).
There are two interaction modes for LLMs:
- Completion mode (pure text completion) 👉 GPT-3 — now basically obsolete
- Chat mode (dialogue format, input message list, output new content) 👉 GPT-3.5/4
MoE (Mixture of Experts) mode splits multiple sub-LLMs (the total is too large with too many parameters), activating only a few at a time to reduce operational costs. Model fine-tuning also adjusts a small number of parameters to change its prediction orientation.
Prompt Engineering
The generated content and quality of AI heavily depend on the prompt keywords you provide; if your prompts are vague, the answers generated will also be vague.
For example, when using Cursor, we generally need to write a cursor rule file to standardize code standards, which is part of the prompt.
Strictly speaking, Prompt Engineering is not a skill; it is simply a way of communication that is easy to understand.
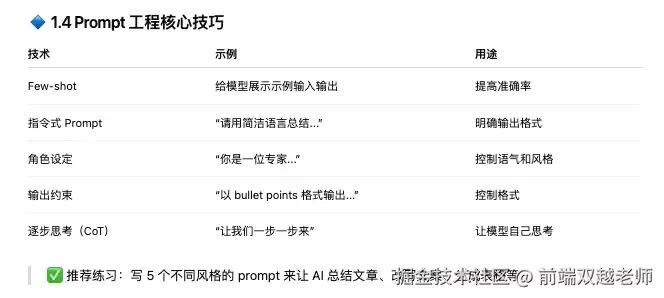
We can constrain user questions through prompts, such as GitHub Copilot focusing solely on programming; it will not answer other questions.
We can also guide the large model to think according to our ideas through the CoT (Chain of Thought) mode. Additionally, we can standardize the AI’s output format or make the AI make certain judgments and choices.
In actual development, we carefully consider how to write prompts for each AI request, and we may even use AI to write prompts or generate them online. It is not just about passing the user’s input directly to the AI interface; a lot of packaging and paraphrasing is required.
LangChain.js
LangChain.js is the preferred choice for frontend developers using Node.js to develop AI applications. Its LangGraph allows for custom agent workflows, and LangSmith tracks and analyzes agent operation processes. LangChain is a very good development ecosystem.
I have previously written several articles related to LangChain, which can serve as learning references:
- 30 Lines of Code: Develop Your First Agent with LangChain.js
- Implement RAG Knowledge Base Semantic Search Using LangChain.js
- Implement Juejin’s “Smart Summary” with LangChain.js Considering Large Documents and Token Limitations
RAG
Retrieval-Augmented Generation (RAG) is an effective method for AI to search for information to assist in generating answers.
Its core steps are: 1. Split the data into vector format and store it in a vector database; 2. When a user asks a question, retrieve relevant answers from the vector database; 3. Send these relevant answers to the AI to generate the final answer. For specific cases, refer to my blog on using LangChain.js to implement RAG knowledge base semantic search.
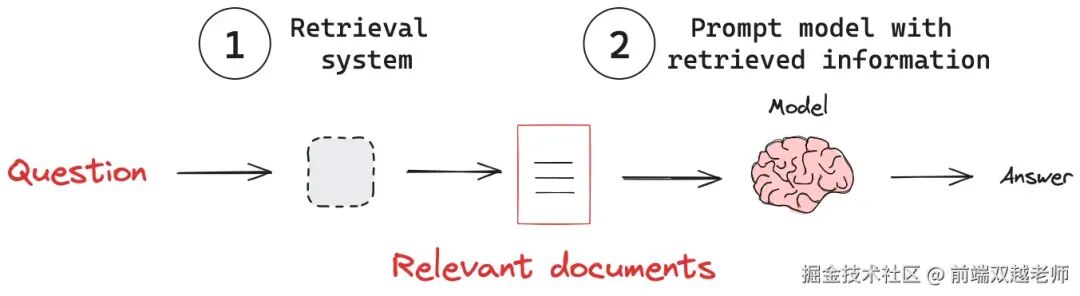
For frontend developers, the concept of vectors may be difficult to understand.
A vector is essentially a coordinate. Commonly seen in two-dimensional and three-dimensional coordinates, it facilitates distance calculations.
We can convert a piece of text, an image, etc., into multi-dimensional (hundreds of dimensions) coordinates (float arrays), and the distance between two coordinates (such as Euclidean distance or cosine similarity) represents the similarity between two pieces of text (or images).
Elastic Search can implement a search engine, but it only matches keywords; for example, the keyword “tutorial” will not match “course” as it is strict text matching. However, vectors can match them as they are similarity-based matching, enabling semantic search. PS. Elastic Cloud now also supports vector storage.
Vector storage technology selection: use Chroma during the development phase, and switch to Pinecone or Supabase after deployment, both of which offer free trial quotas.

Agent
An agent is a composite entity that mainly includes:
- LLM (Large Language Model), responsible for thinking and generating content; an agent can have multiple LLMs, with different nodes configured with different LLMs.
- Workflow: defining nodes, directions, and judgments to implement Re-Act, allowing the AI agent to make logical judgments on its own.
- Tools: calling external services, such as searching and querying databases.
- Memory and storage: recording key information about the current conversation and user.
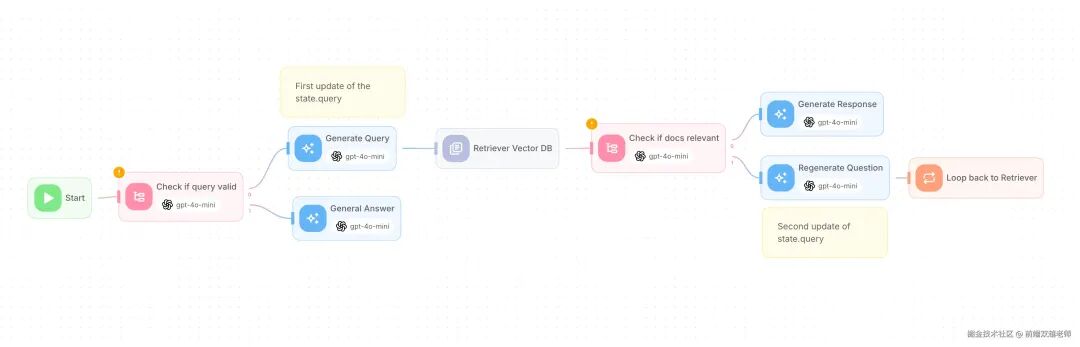
The following image is an example of a RAG agent workflow configuration provided by Flowise (similar to Dify and Coze).
MCP
Model Context Protocol (MCP) is a protocol that defines the parameters and calls of large models, allowing AI to uniformly call third-party services.
Currently, when we talk about AI MCP, we mainly refer to the capabilities provided by various MCP servers. For example, in my previous article, I summarized common MCP servers used in programming that allow writing code in natural language.
Additionally, we need to be able to develop our own MCP servers and clients to call these servers, which requires capability in this area. You can refer to my blog on developing MCP Server and Client with Node.js + Deepseek and the pitfalls encountered.
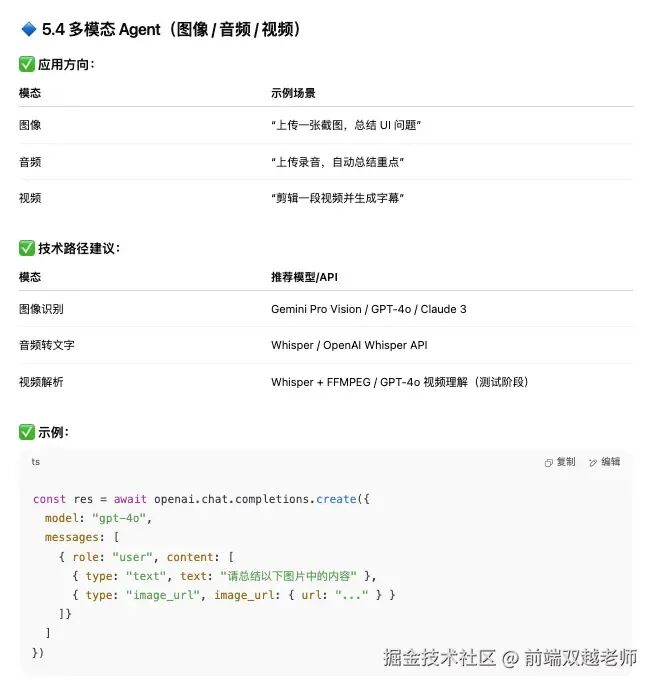
Multimodal
Current AI applications are not limited to text chat; you can upload images, PDFs, Word documents, and even audio and video, all of which can be processed by AI large models. At the same time, AI large models can also generate images, PDFs, audio, and video. Thus, current AI applications need to support multimodal capabilities.
Non-text content generated by AI is often displayed in the form of artifacts. For example, using Claude to generate an HTML webpage, it directly shows the webpage rendering effect on the right side and also supports publishing it online.
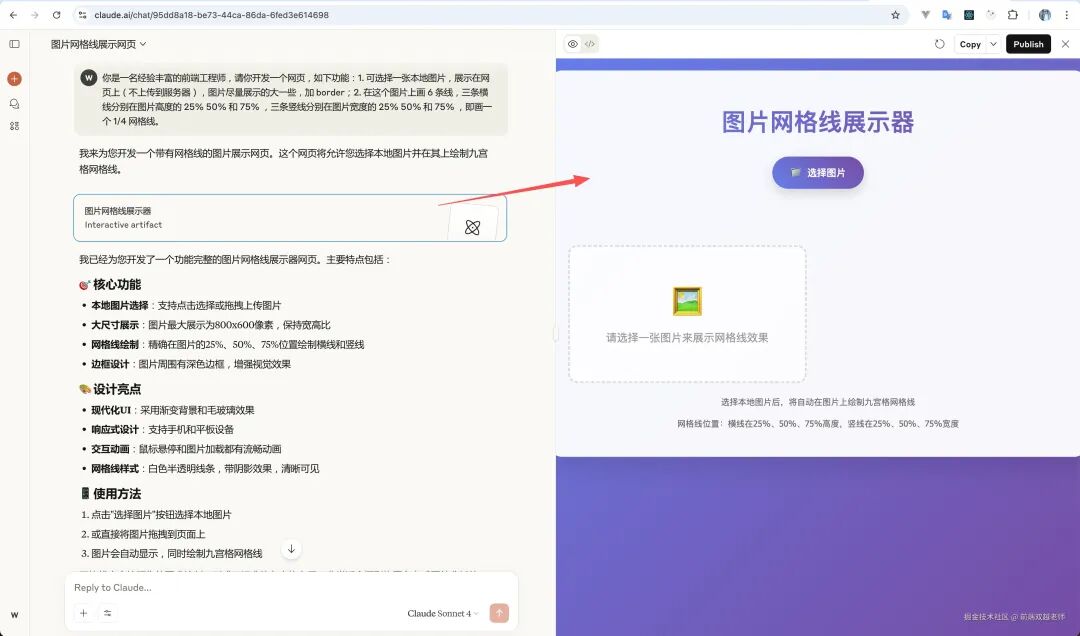
Different AI large models excel in different modal forms and have different API calling methods and parameter writing styles.
Others
AI agents are still evolving, and there are more technologies to learn and practice. I will gradually share more in the future:
- Multi-agent architecture
- A2A protocol, communication protocol between agents
- Context Engineering
- AG-UI protocol, communication protocol between agents and UI
Conclusion
I will continue to delve into the field of AI agents, empowering areas I specialize in, such as interviews, coding practice, resumes, and tutorials, using AI to increase efficiency and serve more users more quickly. Follow me for more content related to AI agents.
AI Programming Information AI Coding Zone Guide:
https://aicoding.juejin.cn/aicoding
 Click“toReadtheOriginalTextforMoreDetails~
Click“toReadtheOriginalTextforMoreDetails~