

Written by / Financial Technology Department of Everbright Bank Zhang Zhifeng Zheng Haoguang Xie Shuhua
To meet the growing reliability and performance demands of business systems, the IT systems of banks are transitioning towards a distributed architecture. During this transformation, we face numerous challenges such as cloud deployment of distributed systems and self-developed hardware and software adaptation. This article shares some practical experiences in the performance optimization process of a large-scale business system at Everbright Bank.
Environment Introduction
In addition to the transformation to a distributed architecture, this system also synchronously implements self-developed hardware and software adaptation and cloud deployment. The specific architecture and technologies used are as follows.
1. Introduction to Infrastructure Layer Deployment Model
This system is deployed on Everbright Bank’s latest generation cloud computing platform—full-stack cloud deployment, where self-developed hardware and software solutions are chosen from the underlying hardware to the operating system, middleware, and database. The platform is mainly divided into three parts: distributed cloud-native applications, distributed databases, and cache databases. The cloud-native applications and cache databases are deployed in the form of containers and virtual machines, while the distributed database is deployed on bare metal servers paired with NVMe local storage, and the operating system is entirely based on a self-developed Linux system.

Figure 1 Architecture Diagram of a Large Distributed Business System
2. Business Model
To verify the support capability of the distributed architecture under high concurrency scenarios, this optimization specifically selected an online transaction system with high concurrency requirements.
As shown in Figure 2, the GW (Gateway) service, DP (Deposit) service, IA (Internal Account) service, UNISN (Global Sequence Number) service, and SEATA open-source distributed transaction are all running in a microservices architecture within a container cluster. Microservices continuously perform heartbeat checks on the service registry and periodically obtain the microservice list and configuration information to achieve configuration updates and service discovery.
Business requests are identified by the GW service calling the DP service interface to recognize the business type, and based on business logic, they flow between various microservices and databases. This system needs to ensure low latency and high concurrency for online transactions under high-frequency internal remote procedure calls.
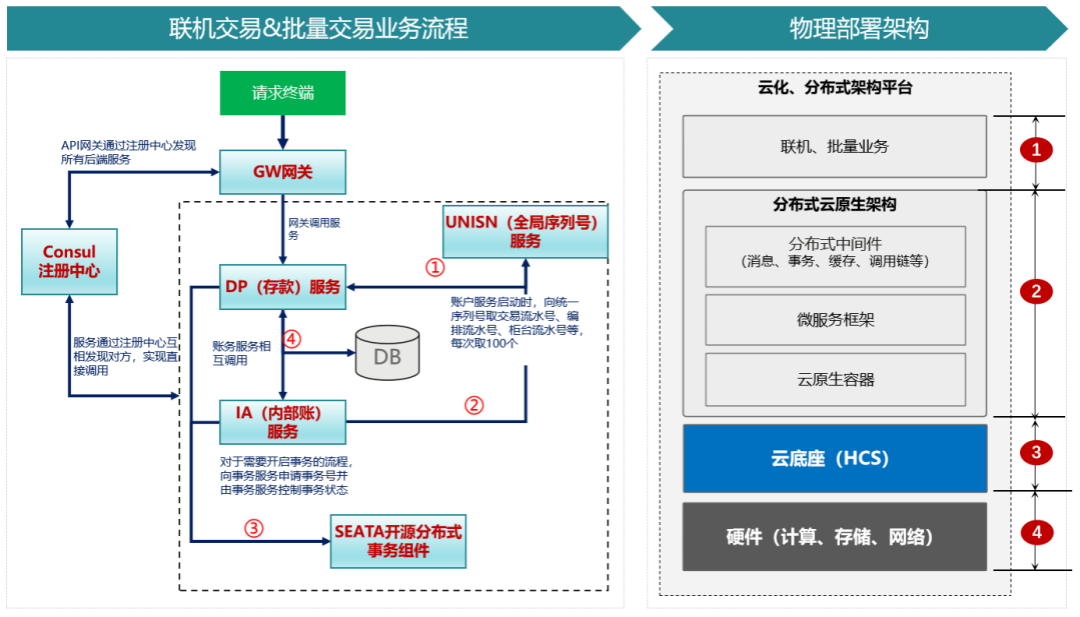
Figure 2 Business Model Diagram of a Large Distributed Business System
Compared to traditional architectures, it is not difficult to find that after the microservices transformation, the overall architecture of the system becomes more complex, with a large number of remote procedure calls between microservices, resulting in increased network interaction overhead, which is further amplified under the cloud computing SDN network.
General Optimization
The overall optimization work is divided into two phases. The first phase aims to sort out the business model, establish optimization ideas, and perform general optimizations on the cloud network, database, and system environment. Experts from various technical fields of our bank participated in the optimization process, optimizing the network model, database objects, and environment to make the basic components and facilities more suitable for the distributed architecture, fully leveraging the advantages of the distributed architecture.
1. Cloud Network Section
The full-stack cloud uses a basic network architecture (three-layer SDN network model), with nodes primarily using Vxlan communication. The tunnel endpoint VTEP, responsible for Vxlan tunnel decapsulation, is widely distributed among computing resources, SDN network elements, bare metal gateways, etc., leading to complex traffic paths for inter-node communication. Considering that high-frequency remote procedure calls in a distributed architecture result in significant network overhead, a dedicated network deployment model needs to be designed for optimal performance. We deployed all virtual machines and containers within the same subnet under the same VPC, allowing network communication between virtual machines and containers to converge below the Leaf switch, avoiding frequent forwarding at the SDN layer. After optimizing the network deployment model, the overall network performance significantly improved, with the average latency controlled to within 250 microseconds, a nearly 30% improvement from the average latency of 350 microseconds before optimization, and overall performance increased by over 20%.
Figure 3 Physical Deployment Diagram of Full-Stack Cloud Network
2. Database Section
Transitioning from a traditional centralized database to a distributed database presents significant challenges. It is essential to fully leverage the performance advantages of distributed databases in handling massive data and high concurrency while avoiding the drawbacks and shortcomings that come with the shift from centralized to distributed architecture. Therefore, we implemented the following optimization measures.
■ Reduce the use of auto-increment columns: In a typical distributed database architecture with separated storage and computation, to ensure that the auto-increment column values remain unique and incrementing across all shards, a unified service is required to generate such incrementing sequences, namely the GTM component. The write efficiency of auto-increment columns in distributed databases is not as high as that of centralized databases, which can become a performance bottleneck in high-concurrency write scenarios. Therefore, we removed the global auto-increment property to avoid the performance bottleneck caused by generating global incrementing sequences.
■ Batch Optimization: To fully leverage the high concurrency performance advantages of distributed databases, we horizontally partitioned the business tables by account and also hashed the partitions by account within each shard. Applications can utilize multithreading and the database STORAGEDB syntax features to transparently pass SQL to the corresponding shards, significantly reducing the execution time of interest calculation batches through parallel execution across multiple shards and partitions. As the number of shards increases in subsequent constructions, the batch execution time will further decrease with increased parallelism, potentially surpassing the performance of centralized databases used in traditional architectures.
Additionally, we adjusted memory management and disk data management strategies for database servers based on industry practices and our bank’s actual situation.
■ Timely cleaning of buff/cache: In high-concurrency read/write scenarios, high occupancy of server buff/cache can easily become a performance bottleneck. We introduced a timed cleaning strategy to reduce instability in TPS and latency caused by delayed server cache releases.
■ Striping: Distributed database DN nodes are I/O intensive services, and minimizing read/write latency on NVMe local disks is a key consideration. Through striping configuration, data reading and writing can achieve maximum I/O parallelism, thereby reducing the time overhead of SQL statement execution and transaction commits.
Targeted Optimization for Performance Bottlenecks
After general optimization, the overall performance of the system improved significantly, but there was still a gap from expectations. We found that the CPU and memory usage rates of various computing nodes were relatively low, indicating that performance bottlenecks still existed. Therefore, we shifted our focus to improving resource utilization of each component under stress testing, and used cloud overlay traffic observation, underlay network probes, and application log embedding to analyze hidden performance bottlenecks, accurately pinpointing bottlenecks with tools to enhance “shortboard performance”.
Segmented Latency Acquisition,
Pinpointing Bottlenecks and Targeted Optimization
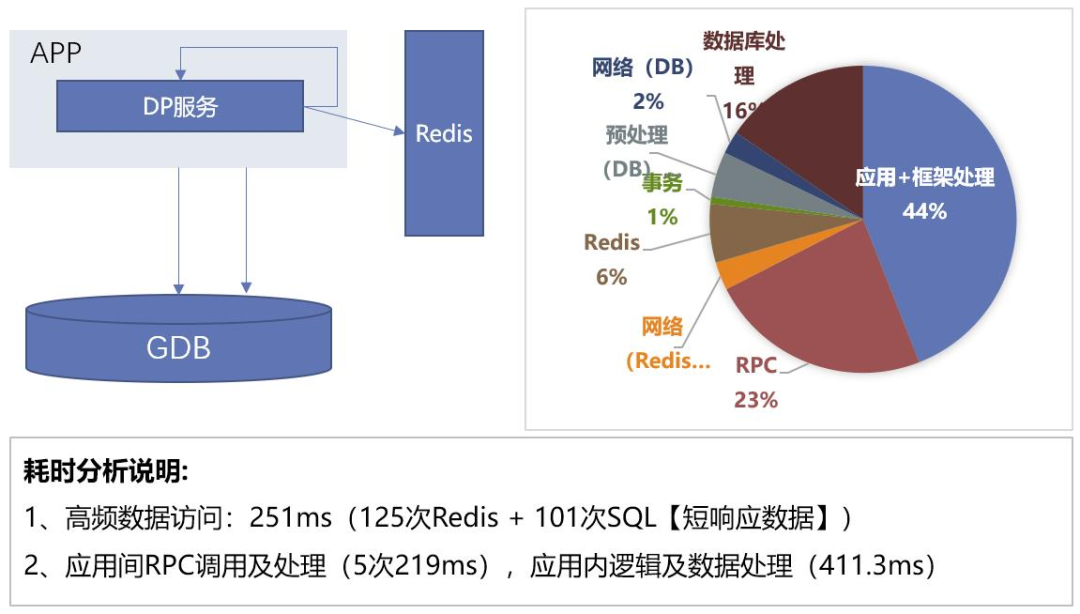
Figure 4 Acquisition and Analysis of Segmented Latency for a Single Transaction
Link monitoring captures segmented latency by capturing key log keywords from application services and databases.Although log output may sacrifice system performance, it effectively helps us analyze the number of calls and latencies at each stage and identify hidden performance bottlenecks.
Analysis revealed that the time overhead of a single transaction mainly comes from data processing within the application, transaction processing in the database, and RPC between microservices. Therefore, we conducted targeted optimizations.
1. At the business layer, we mainly performed cache optimization, batch optimization, and communication optimization.
Cache Optimization:
(1) For parameter library tables that require high-frequency access and are rarely modified, we considered optimizing access efficiency by using cached data.
(2) Generally, applications pre-compile SQL before each database call. In scenarios with many SQL statements, the pre-compilation time can be amplified. By caching the results of SQL pre-compilation, we can reduce the time spent on SQL pre-compilation.
(3) We optimized the availability of the service registry by implementing a multi-level caching strategy with local service list memory cache and local service list file cache, minimizing the impact on the business system during overall downtime of the service registry.
Batch Optimization: Fully leveraging the advantages of distributed architecture, we further increased the concurrency of task processing within resource limits, breaking down batch tasks into smaller units to comprehensively enhance batch processing efficiency. At the same time, we aimed to avoid large transactions by reducing the size of individual transactions, effectively mitigating potential lock conflicts in business processing.
Lower-level Communication Optimization: In scenarios with high-frequency interactions between internal services, we changed the communication protocol between services from HTTP to a socket-based long connection protocol, reducing communication overhead.
2. In the database direction, we mainly optimized transactions and bare metal networks.
Transaction Optimization: Ensuring that relevant tables and data rows do not involve concurrent read/write distributed transactions, we targetedly reduced the isolation level of some transaction session levels through hints, minimizing unnecessary query active transaction lists and select for update time overhead.
Bare Metal Network Optimization: Since distributed databases involve communication coordination between multiple nodes, the overhead on the network link is much higher than that of centralized databases. Therefore, our full-stack cloud experts also conducted targeted optimizations on the internal network of distributed databases.
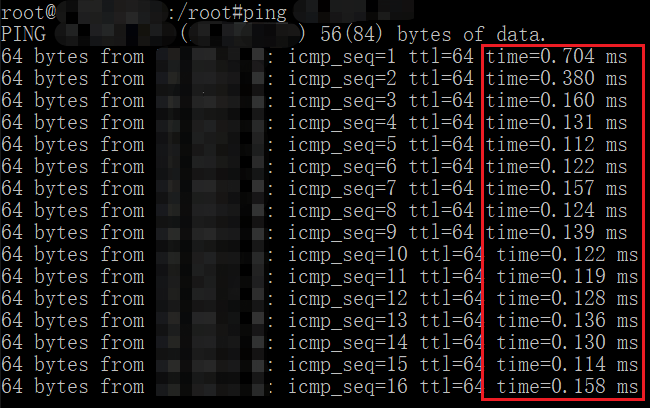
Figure 5 Ping Test Data Before Bare Metal Network Optimization
We added a private network address for each bare metal node, specifically for communication between bare metal nodes,and adjusted the traffic model and communication matrix of the internal network of the database, allowing internal communication between bare metal nodes to achieve the fastest network path through direct forwarding by the Leaf switch, reducing average ping latency from 130us to 80us, significantly improving performance.

Figure 6 Ping Test Data After Bare Metal Network Optimization
Overlay Layer Packet Analysis
In cloud environments, it is challenging to obtain complete network traffic information using traditional underlay probes. Therefore, we utilized network visualization tools to deploy agents on cloud resources to observe overlay layer networks.
Through network packet capture with cloud network visualization tools, we found multiple retransmissions and zero-window phenomena in communication packets, as shown in Figure 7.
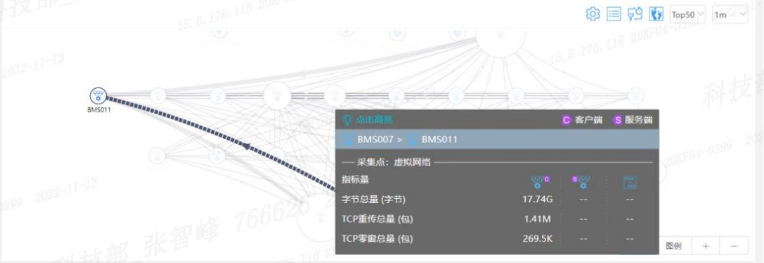
Figure 7 Locating Network Issues Using Cloud Network Visualization Tools
Considering that our self-developed ARM servers differ significantly from the familiar Intel X86 servers not only in instruction sets but also in multi-core architectures, the server configuration methods based on X86 parameters need to be adjusted.
Business analysis revealed that the zero-window and retransmission issues were concentrated in the communication lines between BMS007->BMS011 and BMS008->BMS011 bare metal servers, leading to suspicions of performance bottlenecks in this part of the network link. After upgrading the business logic and expanding the network card buffer, disabling network card interrupt aggregation, and adjusting the network card interrupt queues and core binding, the retransmission and zero-window phenomena were significantly optimized, with the retransmission rate dropping below 0.1%.
In the second phase of optimization, the joint optimization team conducted bottleneck analysis using multiple cloud system observation tools and implemented several targeted optimizations, resulting in over 80% improvement in overall system performance compared to before optimization, but there remains some gap from the overall expected performance of the project. During the optimization implementation, while we gained insights, we also deeply recognized our shortcomings. Facing the complex scenario of “distributed + cloud + self-developed adaptation,” we still have issues such as insufficient cloud tool construction, incomplete microservices transformation, and self-developed hardware and software adaptation still in the exploratory stage.
Review and Summary
Self-developed hardware and software adaptation is still in the experience accumulation stage, and there is still a distance to achieving “out-of-the-box” usability. Important application systems pursuing high stability and extreme performance require relatively complex performance optimization adaptation work during construction to find the “optimal solution” needed for each system. In the future, Everbright Bank will strengthen cooperation with relevant vendors to specifically meet the different needs of application systems such as “economic,” “balanced,” “stability,” and “performance,” forming best practices for the integration of operation and maintenance resources with applications.
In the current technological trend, the construction of application systems faces a series of challenges, including infrastructure cloudification, distributed architectural transformation, self-controllable adaptation of system software, and application containerization. All these introduce a series of uncertain variables into system performance optimization, significantly increasing the difficulty of what was originally a relatively standardized performance optimization process. Since it involves multi-level coordination from infrastructure to applications, it requires infrastructure builders, cloud platform developers, system software and hardware engineers, and application developers to “move towards each other,” collaborate for mutual benefit, and jointly achieve the optimization of system performance.
Faced with complex tasks and multi-level personnel coordination, a systematic and structured approach is needed for situation analysis, goal setting, personnel coordination, and task organization. In this performance optimization process, both the standard testing methodology for segmented data acquisition and the tools introduced for application logs, network traffic, and intelligent operation and maintenance to obtain performance conditions are worth accumulating and promoting in future work. Everbright Bank will actively promote the accumulation of relevant methodologies, tools, and processes to quickly form a set of standardized and efficient performance optimization methodologies, further enhancing the efficiency of agile delivery.









New Media Center
Director / Kuang Yuan
Editors / Yao Liangyu Fu Tiantian Zhang Jun Tai Siqi
