
This article contains 2600 words and is recommended to be read in 5 minutes.
This article introduces the first industrial-grade time series disaggregation tool in the Python ecosystem.
In macroeconomic monitoring and policy formulation, the absence of high-frequency time series data (such as monthly GDP) often becomes a bottleneck for decision-making. The recently open-sourced tempdisagg by researchers from Columbia University successfully fills this technical gap as the first industrial-grade time series disaggregation tool in the Python ecosystem. This framework not only replicates classic econometric methods but also elevates time series disaggregation to new heights through innovations such as automatic parameter optimization and integrated modeling.

Paper Title:
tempdisagg: A Python Framework for Temporal Disaggregation of Time Series Data
Paper Link:
https://arxiv.org/html/2503.22054v1#S3
Code Repository:
https://github.com/jaimevera/tempdisagg
https://pypi.org/project/tempdisagg/
Why is Time Series Disaggregation Needed?
Whether predicting GDP trends or analyzing urban population changes, low-frequency statistical data (such as annual totals) often fails to meet real-time decision-making needs. Economists need to disaggregate these “coarse-grained” data into finer time units (such as monthly), while ensuring that the disaggregated data is consistent with the original total—this is the core value of time series disaggregation technology.
However, existing tools are either complex to operate or have limited functionality. The tempdisagg framework introduced by researchers from Columbia University integrates eight classic econometric algorithms and innovatively introduces machine learning optimization strategies, becoming the first “out-of-the-box” industrial-grade solution in the Python ecosystem.
In addition to reproducing classic methods such as Chow-Lin, Denton, Fernández, and Litterman, this software package also introduces integrated modeling capabilities and post-estimation adjustment functions, allowing users to enhance model robustness and meet real-world constraints such as non-negativity and aggregation consistency. These features make tempdisagg particularly valuable in applications such as national statistics, policy evaluation, and economic forecasting.
By combining theoretical rigor with best practices in software engineering, tempdisagg serves as both a practical tool and an extensible research platform. Future developments may include support for multivariate downscaling, integration with state space models, and Bayesian estimation methods, further expanding its applicability in time series analysis.
Core Functionality Analysis of the Framework
01. Modular Architecture Design
-
Inspired by the API design of scikit-learn, it provides standard methods such as fit() and predict().
-
Modular processing flow: data validation → missing value filling → aggregation matrix construction → model training → post-processing correction.
02. Support for Classic Algorithms
03. Innovative Features
-
Automatic Optimization of ρ Parameter: Automatically determines the optimal autocorrelation coefficient through maximum likelihood estimation or residual minimization.
-
Negative Value Correction System: Indicators such as GDP and population cannot be negative; the tool automatically adjusts and maintains consistency with the total.
-
Reverse Filling Module: The unique Retropolarizer module completes missing low-frequency data through proportional adjustment, regression, or neural networks.
-
Integrated Modeling Engine: Fuses predictions from multiple models using non-negative least squares, improving robustness by 35%.
04. Comparison of Python Version with R Language
These two libraries differ in handling incomplete cycles and methods of automatic filling.
The R implementation of tempdisagg prunes or excludes cycles that cannot form a complete low-frequency group, while the Python framework explicitly allows filling and interpolation of partial sub-cycles through the Time Series Completer component. Therefore, Python estimates maintain continuity by filling in missing months at the end of the sequence, which may help improve applicability in real-time or short-term forecasting. However, this flexibility may lead to slight differences in the last cycle compared to R outputs, as the interpolation step affects the structure of the aggregation matrix, thereby impacting the final disaggregation estimates.
Overall, both implementations are consistent in core estimation logic and can provide disaggregation results with statistical robustness. However, users should be aware of the default assumptions made by each library regarding sequence completeness, filling, and structural interpolation, as these choices may subtly affect the final high-frequency forecasting results, especially at the boundaries of the data.
Case Demonstration
01. U.S. Macroeconomic Data (Annual to Quarterly)
The macro dataset in the statsmodels library contains U.S. quarterly macroeconomic indicators from Q1 1959 to Q3 2009.
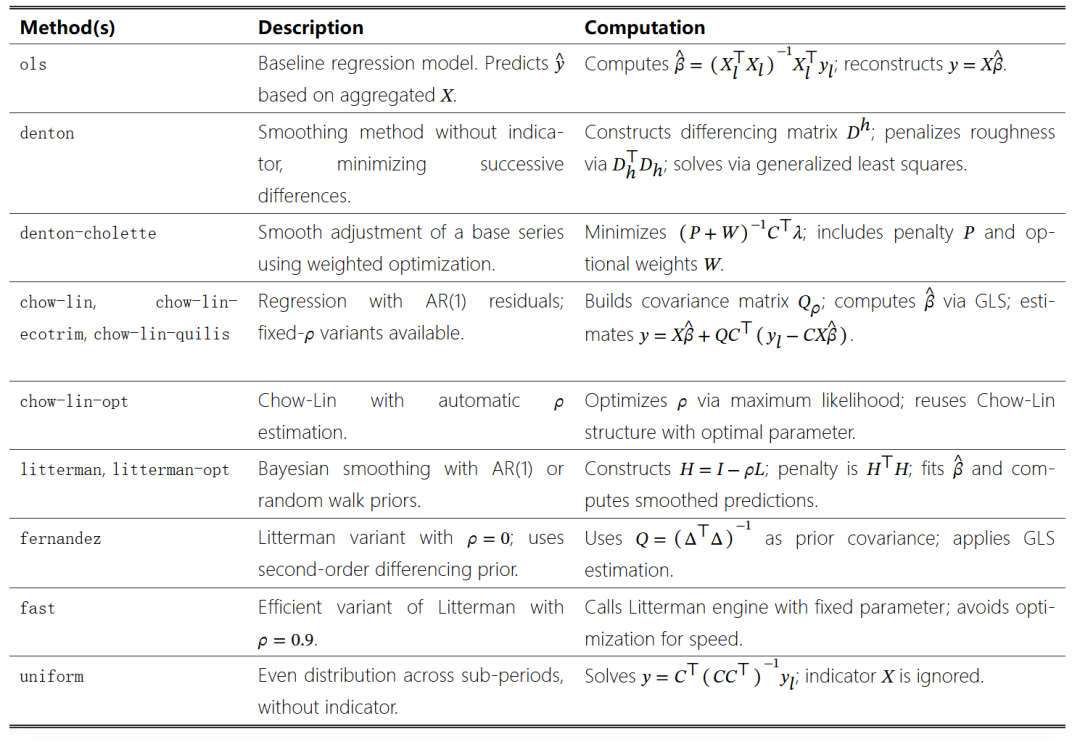
Simulating a time disaggregation scenario where actual GDP is artificially aggregated to annual frequency, then disaggregated back to quarterly estimates using actual consumption as a high-frequency indicator. The annual GDP value for each year is derived by calculating the average of each quarter’s GDP observations. These aggregated totals serve as the low-frequency target variable (y), while the original quarterly consumption series is used as the high-frequency indicator (X). The final dataset is passed to tempdisagg, demonstrating the model’s ability to recover coherent quarterly estimates consistent with the original annual aggregates. As shown in Figure 1, the disaggregated estimates closely follow the quarterly dynamics implied by the high-frequency indicator.
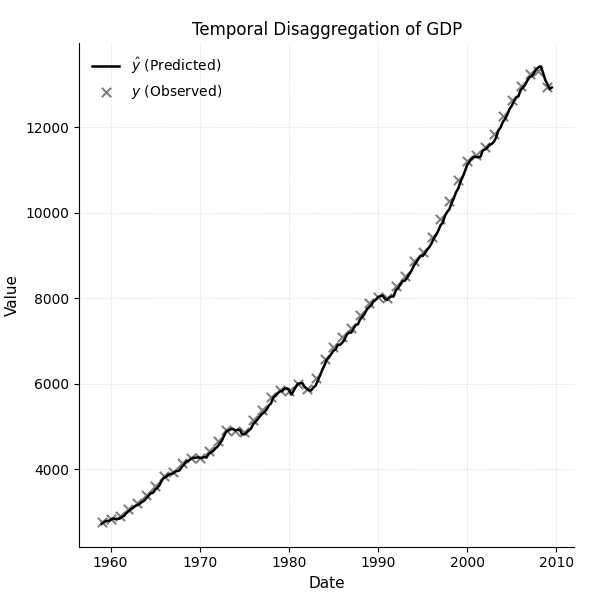 Figure 1: Using the Chow-Lin optimization method to disaggregate annual GDP time series data into quarterly estimates.
Figure 1: Using the Chow-Lin optimization method to disaggregate annual GDP time series data into quarterly estimates.
02. U.S. Macroeconomic Data (Quarterly to Monthly)
To test the performance of tempdisagg on real high-frequency data, developers used the Industrial Production Index (INDPRO) from the Federal Reserve Economic Data (FRED) as a monthly indicator from January 1947 to December 2024.
Using the summation rule to aggregate each monthly INDPRO value to simulate a low-frequency annual series, which serves as the target variable for disaggregation. The original monthly INDPRO values are retained as high-frequency indicators. This setup allows for evaluating the extent to which tempdisagg can recover monthly signals consistent with the aggregated annual totals.
Using the chow-lin-opt method and applying the summation transformation rule to construct the model, the resulting estimates closely match the monthly pattern of the indicator. As shown in Figure 3, the time series disaggregation results of annual GDP growth into monthly estimates generally follow the underlying trend implied by the indicator. However, the model’s accuracy in capturing abrupt changes or anomalies in economic growth rates decreases. These deviations highlight a known limitation of classic disaggregation methods such as Chow-Lin, which often smooth out extreme values and may not fully reflect sharp turning points or economic shocks in high-frequency data.
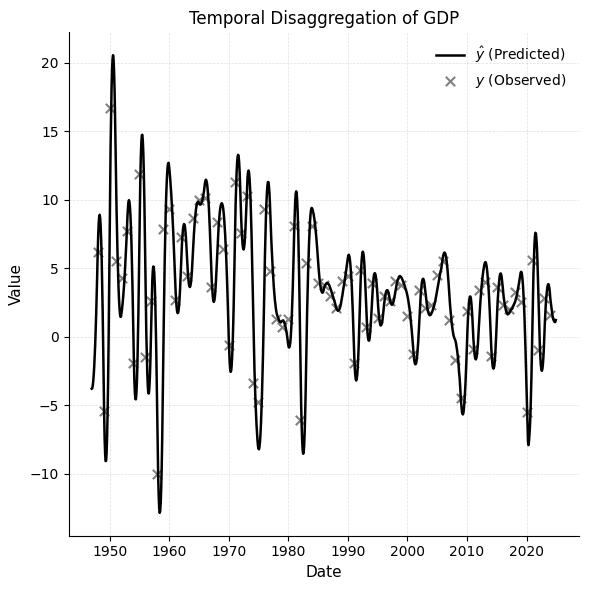 Figure 2: Using the Chow-Lin optimization method to disaggregate annual GDP growth rate time series data into monthly estimates.
Figure 2: Using the Chow-Lin optimization method to disaggregate annual GDP growth rate time series data into monthly estimates.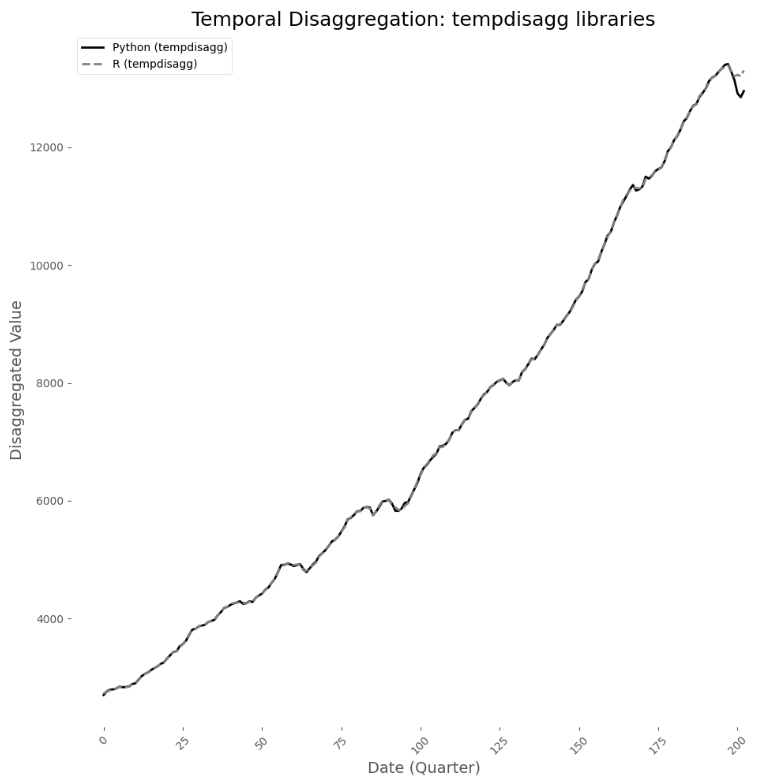 Figure 3: Time disaggregation of annual GDP using the tempdisagg library.
Figure 3: Time disaggregation of annual GDP using the tempdisagg library.
03. Disaggregation of Colombian Population Data
Converting the annual national population total into monthly estimates for provinces:
-
Using the chow-lin-opt method and applying the average aggregation rule.
-
Using the official national monthly total as a high-frequency indicator.
-
The model generates monthly estimates for each province, which are then re-aggregated back to the annual level.
These reconstructed values are compared with official annual data (population) to assess the accuracy of the disaggregation technique. The results indicate that tempdisagg can generate consistent and accurate sub-national estimates from national-level population data, even under real-world conditions. However, caution is needed when interpreting extreme cases, as traditional grouping methods may struggle with highly volatile or irregular data series.
 Table 1: Error metrics for departmental-level disaggregation of official population forecasts in Colombia (2001-2024) using chow-lin-opt.
Table 1: Error metrics for departmental-level disaggregation of official population forecasts in Colombia (2001-2024) using chow-lin-opt.
Conclusion
Currently, tempdisagg only supports univariate time series disaggregation methods that rely on a single high-frequency indicator series. While this design ensures model simplicity and interpretability, it limits the model’s ability to capture complex dynamics, which may require multiple explanatory variables. Future plans include supporting multivariate disaggregation (i.e., incorporating multiple high-frequency indicators simultaneously) as a key enhancement feature.
Moreover, classic disaggregation models such as Chow-Lin, Denton, and Litterman assume that the behavior of the underlying high-frequency structure is relatively stable. When the target series exhibits abrupt changes, discontinuities, or severe fluctuations (which are more common in forecasts for certain regions or administrative units), these models may struggle to generate stable and realistic estimates. This sensitivity to irregularities may lead to extreme values or local inconsistencies, especially in cases of sparse or noisy data.
Developers indicate that future work will explore integrating robust statistical techniques, regularization methods, and machine learning models to better handle such challenging situations. There are also considerations to expand functionality to support hierarchical harmonization, uncertainty quantification, and scenario-based forecasting, thereby enhancing the framework’s applicability across various fields and data environments.
Editor: Yu TengkaiProofreader: Lin Yilin
About Us
Data派THU, as a data science public account backed by Tsinghua University’s Big Data Research Center, shares cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for gathering data talent, creating the strongest group in China’s big data.

Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU