Reposted from Big Company Talk
Recently, Meituan launched the audio-driven multi-person dialogue video generation framework MultiTalk, which has been open-sourced on GitHub. It introduces the innovative L-RoPE binding technology, which accurately addresses the challenges of multi-audio streams and character misalignment through label rotation positional encoding. This framework innovatively employs local parameter training and multi-task learning strategies, maintaining the ability to follow complex action instructions while achieving adaptive dynamic character positioning. By simply inputting multiple audio streams, reference images, and text prompts, it can generate interactive videos with precise lip-syncing and natural body movements, supporting tool upgrades in scenarios such as film production and live e-commerce.
Table of Contents
-
1. Introduction: Beyond the “Talking Head” – The Next Frontier of AI Portrait Video
-
2. Framework Diagram of MultiTalk: How to Achieve AI Dialogue Video Generation
-
2.1 Basic Model Structure: DiT and 3D VAE
-
2.2 Making AI “Talk”: Single-Person Audio Integration
-
2.3 Core Challenges: When Multiple Voices Confuse AI
-
2.4 Making AI “Converse”: L-ROPE Achieves Seamless Multi-Person Binding
-
2.5 Training Strategies
-
2.6 Long Video Generation
-
3. MultiTalk in Practice: Performance Evaluation
-
4. Summary and Outlook
-
5. More Effect Demonstrations
-
6. About Meituan’s Visual Intelligence Department
If you are given a picture and an audio clip, how can you perfectly blend them together so that the characters in the image naturally speak and move, and even interact with each other? Recently, the visual intelligence team at Meituan has open-sourced a product called MeiGen-MultiTalk, which cleverly solves this problem. First, let’s watch a video to see its capabilities:
1. Input Image + Dialogue Audio

Note: The image and audio are both generated by AI.
2. Using MultiTalk to Generate Video
All the shots in the short film “Smile” below were also synthesized by MeiGen-MultiTalk. Isn’t it stunning?
Note: The first frame image and audio source are from “Smile” – Morgan Wallen.Not only this style, but there are also many other types of blends, such as making a kitten talk, dubbing cartoons, and even performing duets, which it handles quite well. Interested readers can scroll to the end of the article to see the effects. The demonstration is complete, and now for the most important part, here are the links!
- Project Homepage:https://meigen-ai.github.io/multi-talk/
- Open Source Code:https://github.com/MeiGen-AI/MultiTalk
- Technical Report:https://arxiv.org/abs/2505.22647
1. Introduction: Beyond the “Talking Head” – The Next Frontier of AI Portrait Video
Currently, artificial intelligence has made remarkable progress in the field of visual content generation, especially in audio-driven portrait videos. Whether it is the “talking head” or “talking body” technology, they can generate videos that are highly synchronized with facial movements and visually satisfactory from audio signals. These technologies perform excellently in simulating single-person speech, showcasing realistic effects in applications such as virtual anchors or digital avatars.
However, existing methods increasingly reveal their limitations when dealing with more complex scenarios, facing three major challenges in generating multi-person dialogue videos:
- Multi-Audio Stream Input Adaptation: How to distinguish and bind the audio signals of different characters?
- Dynamic Character Positioning: How to accurately locate the movement area of characters when they move in the frame?
- Instruction Following Ability: How to ensure that the generated video strictly follows the complex actions described in the text (such as large body movements)?
These challenges prompt researchers to consider where the next frontier of AI portrait video lies. From initially focusing on facial expressions with the “talking head” to simulating full-body movements with the “talking body”, and now to the “multi-person dialogue video generation” proposed by MultiTalk, this clearly reveals the evolution trend in the AI portrait video field from focusing on local details to full-body actions, and then to simulating complex social interactions. This evolution is not merely a simple enhancement of technical capabilities but reflects the growing demand for simulating the complexity of the real world and the potential for AI to play a more advanced role in content creation. Users’ demands for the “realism” and “complexity” of AI-generated content are increasing; simply being able to “move” is no longer sufficient; now AI needs to be able to “interact naturally” and “understand and execute complex instructions”.
2. Framework Diagram of MultiTalk: How to Achieve AI Dialogue Video Generation
The technical framework of MultiTalk for audio-driven multi-person dialogue video generation is shown in the following diagram:
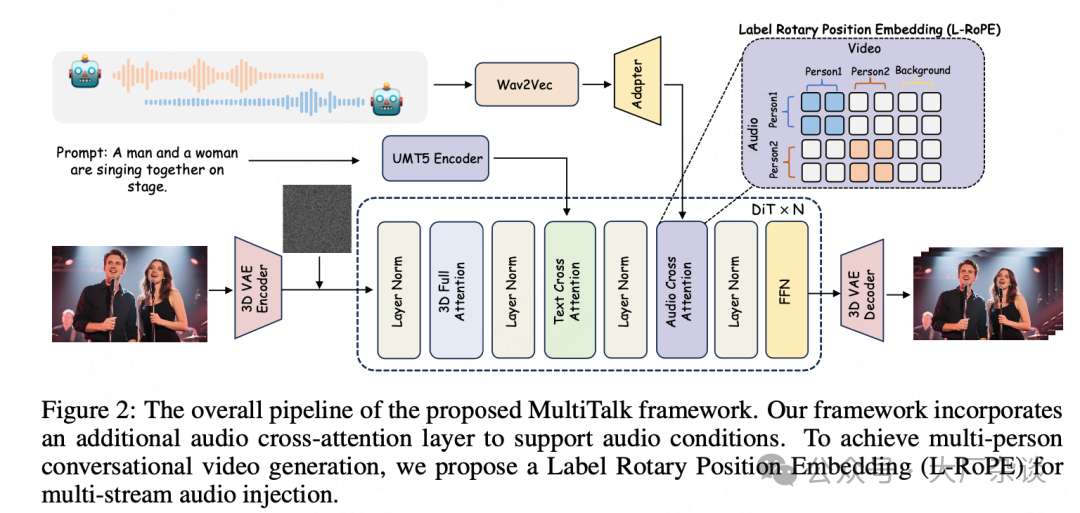
| 2.1 Basic Model Structure: DiT and 3D VAE
MultiTalk is based on the DiT (Diffusion-in-Transformer) video diffusion model as its core framework. The DiT model has gained attention for its outstanding performance in image and video generation, replacing the traditional U-Net with a Transformer structure, which better captures long-range dependencies.
To efficiently process video data, MultiTalk integrates a 3D Variational Autoencoder (VAE). The 3D VAE compresses video data in both spatial and temporal dimensions, encoding high-dimensional raw video data into more compact latent representations. This compression significantly reduces the computational burden of the subsequent diffusion model while retaining key visual information.
First, a text encoder is used to transform the user-input text prompt (for example, “A man and a woman are singing on stage”) into text condition embeddings that guide the generation of video content. Secondly, global contextual information extracted through a CLIP image encoder is also injected into the DiT model. This image context and text conditions work together through a decoupled cross-attention mechanism, providing visual and semantic guidance for the generated video, ensuring that the generated content aligns with the reference image and text prompt.
| 2.2 Making AI “Talk”: Single-Person Audio Integration
The basic image-to-video (I2V) diffusion model typically does not natively support audio input. To enable the model to “speak”, MultiTalk adds new layers after the text cross-attention layer in each DiT block, which include layer normalization and an audio cross-attention mechanism specifically designed to process and integrate audio conditions.
In terms of audio embedding extraction and contextual integration, MultiTalk employs Wav2Vec, a widely used audio feature extractor that converts audio waveforms into high-dimensional audio embeddings. In audio-driven human videos, the actions at the current moment are influenced not only by the current audio frame but also by the preceding and following audio frames. Therefore, MultiTalk follows existing methods by concatenating audio embeddings adjacent to the current frame (controlled by the context length k parameter), forming audio embeddings with richer temporal context to better capture the dynamic changes in speech.
A significant challenge is that due to the temporal compression of video data by the 3D VAE, the frame length of the video latent space is usually shorter than that of the original audio embeddings, making it impossible to perform frame-to-frame cross-attention calculations directly. To address this temporal length mismatch, MultiTalk uses an audio adapter. This adapter compresses and aligns the audio embeddings through a series of operations: first, it splits the input audio embeddings into initial frames and subsequent frames; then it downsamples the subsequent frames; next, it encodes the initial frames and downsampled subsequent frames through multiple MLP layers; it concatenates the encoded features; finally, it encodes the concatenated features again through an MLP layer to obtain compressed audio conditions that match the frame length of the video latent space. The audio adapter resolves the inherent temporal granularity mismatch between video and audio data, ensuring a smooth flow of information, allowing different modalities to interact efficiently within the same framework.
| 2.3 Core Challenges: When Multiple Voices Confuse AI
Compared to single-person videos, generating multi-person dialogue videos introduces multiple complexities that existing methods cannot address. First, in dialogue scenes, audio signals come from multiple characters, and the model needs to be able to process these different audio streams simultaneously and independently, which is the challenge of “multi-stream audio input processing”. Secondly, one of the core challenges is the “precise binding of audio to characters”. It is essential to ensure that each character in the video is driven only by its corresponding audio stream to prevent lip-sync errors from appearing across all characters, leading to the unnatural phenomenon of “synchronized speaking”, which is highly unnatural in real conversations. Finally, the characters in the generated video are dynamic, and their positions and postures change with dialogue and actions. This requires the model to have an “adaptive method” that can accurately track each character’s movement area in the video frames to map the audio correctly to the right visual area.
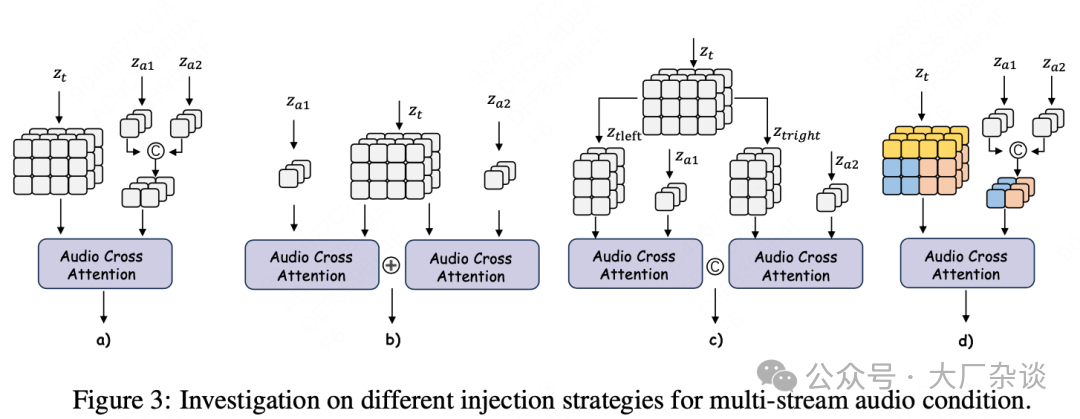
In exploring multi-stream audio injection solutions, MultiTalk has tried various intuitive methods, as shown in the above diagram. However, most have failed to effectively solve the binding problem between audio and characters, highlighting the complexity of the issue itself, which cannot be resolved by simple concatenation or segmentation. Initial attempts included:
- Directly concatenating multi-stream audio embeddings: Directly concatenating the embeddings of multi-stream audio and then performing cross-attention calculations with the video latent space. However, this method failed to bind the concatenated multi-stream audio to the corresponding specific character areas in the video, leading to chaotic synchronization.
- Calculating separately and then summing: Calculating the cross-attention results of each audio stream with the video latent space separately and then summing these results. However, this method also failed to solve the binding problem, as the model could not distinguish which audio should drive which character.
- Segmenting the video latent space (left and right areas): Considering that characters in the video are usually located on the left and right sides, MultiTalk attempted to simply segment the video latent space into left and right parts and let each part compute attention with the corresponding audio stream. Although this method somewhat successfully bound multi-stream audio to different characters, its generalization ability is extremely limited. It only applies to videos where characters have a small range of motion; once characters move or cross over a large area, this simple spatial segmentation leads to audio binding failures.
The fundamental reason for the failure of these traditional methods lies in their lack of the ability to adaptively locate dynamic subjects. Direct concatenation, simple summation, or fixed spatial position-based segmentation do not allow the model to understand which audio stream should correspond to which dynamically changing character in the video. The lack of this deep “character perception” and “semantic binding” mechanism leads to “incorrect binding” – everyone speaks synchronously, which is highly unnatural in dialogue scenes and severely affects the realism and usability of the generated video.
| 2.4 Making AI “Converse”: L-ROPE Achieves Seamless Multi-Person Binding
To solve this problem, MultiTalk proposes L-ROPE. Before applying L-ROPE for audio binding, MultiTalk first needs to address a fundamental issue: how to dynamically identify and track the position of each character in the video. Given a reference image containing multiple characters, the model first identifies the mask areas of each character and the background mask. In the DiT model, the first frame of the video usually serves as the reference image. MultiTalk utilizes the “self-attention map from the reference image to the video”. As shown in Figure 4a), by calculating the average similarity of each token in the video latent space with the character masks in the reference image, the model can obtain a similarity matrix. Using this similarity matrix, the model can adaptively determine which latent token in the video belongs to which character or background, thus achieving dynamic positioning and tracking of each character.
Label Rotary Position Embedding (L-ROPE) is the core innovation of MultiTalk, based on the idea of ROPE (Rotary Position Embedding). ROPE is a widely used relative position encoding technique in large language models (LLMs) and video diffusion models, known for its excellent ability to capture relationships between tokens and handle spatiotemporal information. The innovation of L-ROPE lies in its incorporation of “category labels” into the position encoding, thus achieving precise binding of multi-stream audio to multiple characters in the audio cross-attention layer of the DiT block.
In terms of label assignment strategy, the video latent space contains multiple categories, such as areas for multiple characters and backgrounds. MultiTalk assigns a specific numerical range as a label for each character (for example, the visual label range for the first character is {0-4}, and for the second character is {20-24}). The final label for each token in the video latent space is calculated based on its similarity to the corresponding character mask, using a normalization function within this range. The background area is assigned a static label to ensure it is not associated with any audio stream, preventing background elements from being audio-driven. For multi-stream audio embeddings, MultiTalk first concatenates them and then assigns a static, unique label to each audio stream. To bind these audio labels to the characters in the video, these audio labels are carefully chosen to be “close to” or “match” the visual label ranges of the corresponding characters (for example, the label for the first audio stream is 2, and for the second audio stream is 22).
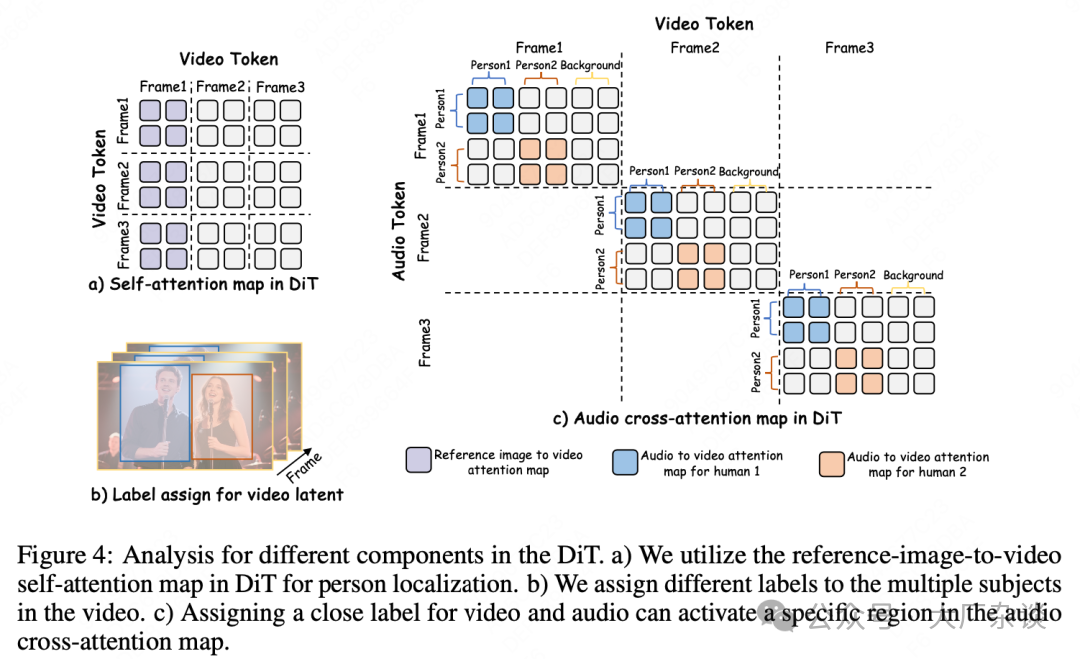
The characteristic of L-ROPE is that it cleverly integrates “category information” (which pixel belongs to which character class or background class) into the “position encoding”. Traditional ROPE deals with purely spatiotemporal positional information, while L-ROPE goes further by encoding “category” information. This allows the model to distinguish between different individuals in the scene. In the audio cross-attention mechanism, Q (from the video latent space) and K (from the multi-stream audio embeddings) are both processed with L-ROPE. Through this semantically labeled rotation, when a certain area in the video latent space (for example, the area corresponding to character 1) has a label that “matches” the label of audio 1, the attention weights between them are effectively activated, forcing the model to focus the driving effect of audio 1 on character 1, thus solving the incorrect binding problem, as shown in Figure 4c). This strategy effectively activates specific areas in the audio cross-attention map, ensuring that the audio is precisely synchronized with the lip movements and actions of the corresponding characters.
To validate the effectiveness of L-ROPE, the paper conducted an ablation study focusing on the selection of label ranges. The experimental results (as shown in Table 3) indicate that even when different label ranges are chosen for different characters, the resulting performance metrics are similar. This shows that L-ROPE is not sensitive to specific label range variations.

| 2.5 Training Strategies
The MultiTalk framework employs multiple training strategies that collectively ensure the model’s high performance, precise audio synchronization, and instruction-following ability in multi-person scenarios.
1. Two-Stage Training: Gradual Skill Enhancement
The training process of MultiTalk is divided into two stages, aimed at progressively enhancing the model’s audio processing and lip-syncing capabilities. The primary goal of the first stage is to develop the model’s strong capabilities for single-person videos, during which the model is trained on a dataset of single-person speaking videos. Once the model has mastered single-person video capabilities, it enters the second stage. The second stage uses specially collected training data containing dual-stream audio to facilitate the model’s learning of multi-person video and interaction.
2. Partial Parameter Training: Precise Tuning to Avoid Degradation
This is a key strategy in MultiTalk’s training. Throughout the training process, researchers only update the network parameters in the audio cross-attention layer and audio adapter while freezing all other base model network parameters. The findings in the paper indicate that under limited computational resources and data volume, conducting full-parameter training leads to a significant decline in the model’s instruction-following ability (especially for complex actions and character interactions), and may even cause visual artifacts such as hand and object deformation in the generated videos. In contrast, by only training specific layers directly related to audio input, MultiTalk can effectively retain the original strong instruction-following ability of the base model and avoid the aforementioned visual degradation issues.
3. Multi-Task Training: Enriching Scene Understanding and Strengthening Instruction Following
MultiTalk adopts a multi-task mixed training paradigm, dividing the model training tasks into audio + image-to-video (AI2V) training and image-to-video (I2V) training. Although the tasks are different, they share the same network parameters. In the AI2V task, the model uses both reference images and audio as conditional inputs, focusing on learning audio-driven lip-syncing and action generation. In the I2V task, the audio condition is removed (by zeroing the audio embeddings). The training data used in the I2V task is unique, primarily consisting of a large number of multi-event videos. These videos cover complex interactions between characters, objects, and scenes, such as characters picking up cups and interacting with the environment. This multi-event dataset is crucial for ensuring that the model can accurately understand and execute the complex actions and interactions described in the text prompts. The paper notes that if only speaking head and body data are used for AI2V training, the network’s instruction-following ability will be significantly weakened. However, by incorporating I2V training into the multi-task paradigm, the model can effectively retain its strong instruction-following ability, generating videos that better align with user intentions, as shown in Figure 5. This strategy embodies generalization and robustness, enhancing the model’s general understanding and instruction-following ability while maintaining specific task capabilities.

| 2.6 Long Video Generation
Although the MultiTalk model can generate high-quality short videos (for example, 3-5 seconds), this is far from sufficient for practical application scenarios (such as producing movie clips, live content), as these scenarios typically require longer videos. To overcome the limitation of single-generation length, MultiTalk introduces an autoregressive-based method to generate long videos. It uses the ending part of previously generated videos as conditions to generate new video segments, achieving temporal continuity and extension.
In terms of specific implementation mechanisms, traditional image-to-video (I2V) models typically only use the first frame of the video as a condition for generating subsequent frames. MultiTalk makes a key improvement in this regard. When generating new video segments, it no longer relies solely on the first frame but instead uses the last five frames of the previously generated video as additional conditional inputs in the current inference step. This allows the model to “remember” and continue the previous actions and scene states. These five frames of video, used as conditions, are first compressed through the 3D VAE, transforming them into more compact two-frame latent noise representations. Subsequently, to match the input format of the DiT model, the new video frames (in addition to the two frames of latent noise derived from historical information) are zero-padded. These padded frames, latent noise from historical information, and a video mask are concatenated together to form a complete input. Finally, this input containing historical context information is fed into the DiT model for inference, generating new video segments. The following video demonstrates the smoothness of the generated results.
1. Input Image + Dialogue Audio

Note: The image and audio are sourced from “2 Broke Girls”
2. Using MultiTalk to Generate Video
3. MultiTalk in Practice: Performance Evaluation
The performance of MultiTalk has been validated through extensive experiments, including quantitative and qualitative comparisons with existing state-of-the-art methods, fully demonstrating its capabilities in generating multi-person dialogue videos.
In terms of datasets and evaluation metrics, the training dataset for MultiTalk in the first stage used approximately 2K hours of single-person speaking videos to learn the basic audio-driven video capabilities; the second stage used 100 hours of dual-person dialogue videos for specialized training in multi-person interaction and binding. MultiTalk has been evaluated on three different test datasets: the talking head datasets (HDTF and CelebV-HQ), the talking body dataset (EMTDT), and the dual-person talking body dataset (MTHM). The evaluation adopted industry-standard multi-dimensional metrics: FID (Frechet Inception Distance) and FVD (Fréchet Video Distance) to assess the quality of the generated data; E-FID (Expression-FID) to evaluate the expressiveness of facial expressions in the generated videos; Sync-C and Sync-D to accurately measure the synchronization of lip movements with audio in the generated videos.
In quantitative evaluations, MultiTalk outperformed several state-of-the-art methods such as AniPortrait, VExpress, EchoMimic, Hallo3, Sonic, and Fantasy Talking in most metrics, especially demonstrating superior performance in lip-syncing (Sync-C, Sync-D) and video quality (FID, FVD).
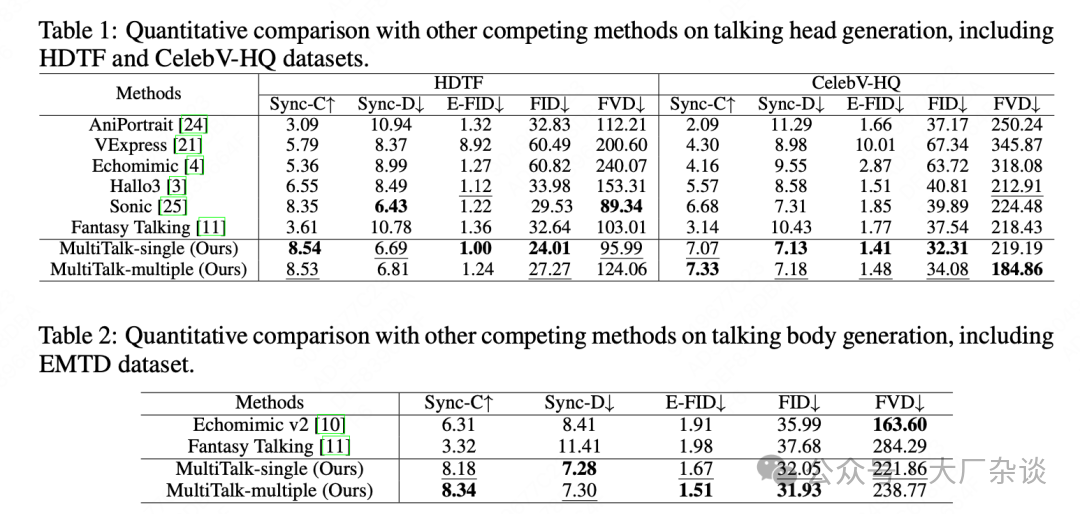
Additionally, we specifically explored whether multi-stream audio training would lead to a decline in single-person video performance (for details, refer to the paper). The experimental results (comparing “MultiTalk-single” and “MultiTalk-multiple” in Tables 1 and 2) show that the multi-person video model of MultiTalk performs comparably to the single-person video model on single-person datasets. This indicates that MultiTalk has not sacrificed its original single-person video performance when introducing multi-person processing capabilities, achieving a lossless overlay of capabilities.
In qualitative evaluations, MultiTalk achieved impressive results, as shown in Figure 6. One of its significant advantages is its strong instruction-following ability. When provided with complex text prompts (for example, “A man closes a laptop and places it on the table”, “A woman sits at a table wearing headphones, then picks up the headphones”), MultiTalk can successfully generate videos that accurately respond to these instructions, while other similar methods struggle to do so, often resulting in mismatched actions or object deformations. The videos generated by MultiTalk exhibit significantly reduced visual artifacts (such as hand or object distortions), higher overall visual quality, and a more natural and realistic appearance. As the first method specifically designed for multi-person generation tasks, MultiTalk performs excellently in handling complex interactive scenes.

Compared to simple “video stitching” methods (which generate videos for left and right characters separately and then stitch them together), as shown in Figure 7, MultiTalk can effectively handle interactions between characters, avoiding the common inconsistencies between left and right segments in stitching methods, making multi-person dialogue and interaction smoother and more natural. The paper also visually demonstrates the self-attention maps, intuitively showing that MultiTalk can adaptively identify the positioning of specific characters in the video, further proving the effectiveness of the L-ROPE method in achieving precise audio binding.

4. Summary and Outlook
MultiTalk proposes an audio-driven multi-person dialogue video generation solution, with its core breakthrough being the innovative L-ROPE method, which effectively addresses the challenges of multi-stream audio injection and character binding through the combination of adaptive character positioning and category information label encoding. Additionally, its carefully designed partial parameter training and multi-task training strategies ensure that the model maintains strong instruction-following ability and high-quality visual output even under limited resources.
The emergence of MultiTalk signifies its broad application prospects in fields such as multi-role film production, virtual live streaming, game development, and educational content creation. We firmly believe that it will greatly lower the production threshold for multi-role videos, making personalized and interactive content creation more efficient and convenient. Although there are still limitations such as the performance gap between real audio and synthesized audio, MultiTalk points the way for future research. We look forward to MultiTalk and its subsequent research further enhancing AI’s capabilities in simulating and creating complex human-computer interactions, making characters in the digital world more lifelike.
Now, MultiTalk has been open-sourced on GitHub, and we welcome more students to join us in building together.
5. More Effect Demonstrations
Example 01: Input Image + Audio File

Note: The image and audio are generated by AI
Using MultiTalk to Generate Video
Example 02: Input Image + Audio File

Note: The image and audio are sourced from “Minions”
Using MultiTalk to Generate Video
Example 03: Input Image + Audio File

Note: The image and audio are generated by AI
Using MultiTalk to Generate Video
Example 04: Input Image + Audio File

Note: The image is generated by AI, and the audio source is from “You Are The Reason”
Using MultiTalk to Generate Video
6. About Meituan’s Visual Intelligence Department
Meituan’s Visual Intelligence Department builds visual technology capabilities ranging from basic general to specialized fields around rich local life e-commerce scenarios, including: visual generation large models, multi-modal interactive virtual humans, assisting marketing creative production and low-cost live streaming for merchants; document, product, and security multi-modal large models, assisting merchants in store operations, platform product governance, and violation account governance; face recognition, text recognition, fine-grained image analysis, high-performance detection segmentation, and street scene understanding, becoming the company’s foundational infrastructure capabilities.
The Visual Intelligence Department has previously open-sourced the largest food image dataset, Food2K, which has been used by hundreds of institutions worldwide, and the target detection framework YOLOV6 has topped the 2023 global open-source contribution list, winning over 10 international competition championships, with hundreds of invention patents and over 60 top conference and journal papers. It has collaborated with many well-known research institutions in China and has won multiple provincial and ministerial science and technology progress awards.
Reposted from Big Company Talk
END
If this article has helped you
Don’t forget tolike, view, collect, and shareto support us!
Big Company Talk
Focusing on open-source and technical sharing from big companies and experts
Communication Community
Big Company Experts Open Source and Technical Operations Reposting Communication Group
Small Micro Product Research and Development, Technical Writing Self-Media Communication Group
Frontend,Backend,AI, and various cloud vendor development communication groups
