This article is reprinted from the Jishu Community
Jishu Column: Embedded AI
Author: High Performance Computing Research Institute
1. SIMD
ARM NEON is a SIMD (Single Instruction Multiple Data) extension architecture suitable for ARM Cortex-A and Cortex-R series processors.
SIMD uses a controller to manage multiple processors, executing the same operation on each data item in a set of data (also known as “data vectors”), thereby achieving parallelism.
SIMD is particularly suitable for common tasks such as audio and image processing. Most modern CPU designs include SIMD instructions to enhance multimedia performance.
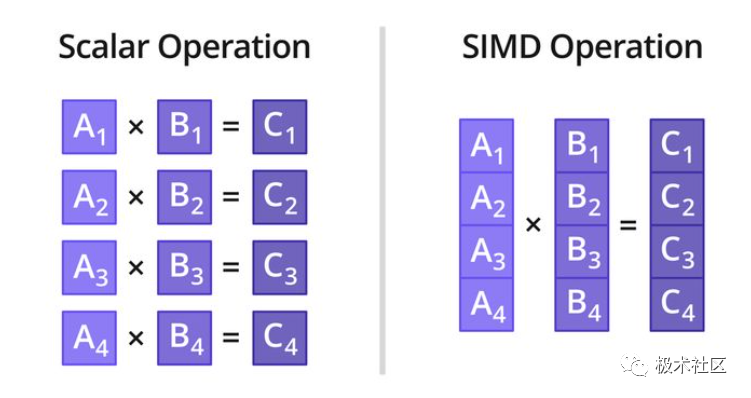
Illustration of SIMD operations
As shown in the figure above, scalar operations can only perform multiplication on one pair of data at a time, while using SIMD multiplication instructions allows for simultaneous multiplication on four pairs of data.
A. Instruction Flow and Data Flow
Flynn’s taxonomy classifies computer types based on the handling of instruction flows (Instruction and data flows (Data, resulting in four types:
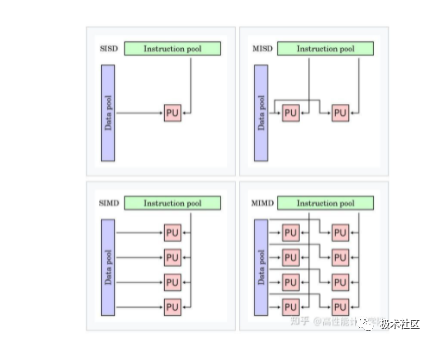
Flynn’s taxonomy illustration
1. SISD (Single Instruction Single Data)
The hardware of the machine does not support any form of parallel computation, and all instructions are executed serially. A single core executes a single instruction stream, operating on data stored in a single memory, one operation at a time. Early computers were SISD machines, such as the von Neumann architecture and IBM PCs.
2. MISD (Multiple Instruction Single Data)
This uses multiple instruction streams to process a single data stream. In practice, using multiple instruction streams to handle multiple data streams is more effective, so MISD only appears as a theoretical model and is not implemented in practice.
3. MIMD (Multiple Instruction Multiple Data)
The computer has multiple asynchronous and independently working processors. In any clock cycle, different processors can execute different instructions on different data segments, meaning multiple instruction streams operate on different data streams simultaneously. MIMD architecture can be used in various application fields such as computer-aided design, computer-aided manufacturing, simulation, and communication switches.
In addition to the above models, NVIDIA has introduced the SIMT architecture:
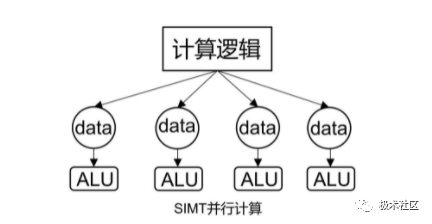
4. SIMT (Single Instruction Multiple Threads)
Similar to multithreading on a CPU, each core has its own execution unit, with different data but the same commands being executed. Multiple threads have their own processing units, unlike SIMD which shares one ALU.
B. Features and Development Trends of SIMD
1. Advantages and Disadvantages of SIMD
2. Development Trends of SIMD
Taking the next-generation SIMD instruction set under the ARM architecture, SVE (Scalable Vector Extension), as an example, it is a new vector instruction set developed for high-performance computing (HPC) and machine learning.
The SVE instruction set shares many concepts with the NEON instruction set, such as vectors, channels, and data elements.
The SVE instruction set also introduces a new concept: variable-length vector programming model.
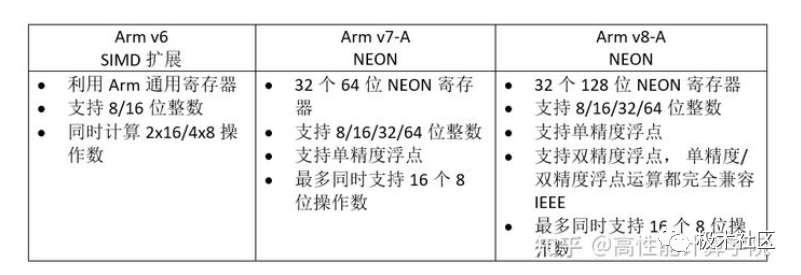
Traditional SIMD instruction sets use fixed-size vector registers, such as the NEON instruction set, which uses fixed 64/128-bit vector registers.
The SVE instruction set, which supports the VLA programming model, uses variable-length vector registers. This allows chip designers to choose an appropriate vector length based on load and cost.
The length of the vector registers in the SVE instruction set supports a minimum of 128 bits and a maximum of 2048 bits, with increments of 128 bits. SVE design ensures that the same application can run on SVE instruction machines supporting different vector lengths without needing to recompile the code.
ARM launched SVE2 in 2019, based on the latest Armv9, expanding more operation types to fully replace NEON and adding support for matrix-related operations.
2. ARM’s SIMD Instruction Set
1. SIMD Support in ARM Processors – NEON
ARM NEON units are included by default in Cortex-A7 and Cortex-A15 processors, but are optional in other ARMv7 Cortex-A series processors. Some implementations of the ARMv7–A or ARMv7–R architecture profile in the Cortex-A series may not include the NEON unit.
Possible combinations of ARMv7 compliant cores are as follows::
Therefore, it is necessary to first confirm whether the processor supports NEON and VFP. This can be checked during compilation and runtime.
History of NEON development
2. Checking SIMD Support in ARM Processors
2.1 Compile-Time Check
The simplest way to check for the existence of the NEON unit. In the ARM compiler toolchain (armcc) version 4.0 and above or GCC, check if the predefined macros ARM_NEON or __arm_neon are enabled.
The equivalent predefined macro for armasm is TARGET_FEATURE_NEON.
2.2 Runtime Check
Detecting the NEON unit at runtime requires assistance from the operating system. The ARM architecture intentionally does not expose processor features to user-mode applications. In Linux, /proc/cpuinfo contains this information in a readable format, such as:
-
In Tegra (dual-core Cortex-A9 processor with FPU)
$ /proc/cpuinfo swp half thumb fastmult vfp edsp thumbee vfpv3 vfpv3d16
-
ARM Cortex-A9 processor with NEON unit
$ /proc/cpuinfo swp half thumb fastmult vfp edsp thumbee neon vfpv3
Since/proc/cpuinfo output is text-based, it is often preferred to check the auxiliary vector /proc/self/auxv, which contains the binary format of the kernel hwcap, allowing for easy searching of /proc/self/auxv for the AT_HWCAP record to check for the HWCAP_NEON bit (4096).
Some Linux distributionsld.so linker scripts are modified to read hwcap via glibc and add extra search paths for shared libraries that enable NEON.
3. Instruction Set Relations
-
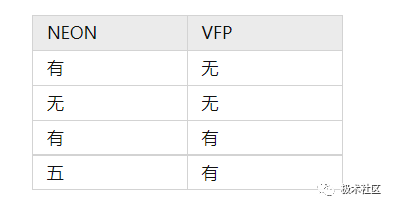
In ARMv7, NEON has the following relationship with the VFP instruction set:
-
Processors with a NEON unit but without a VFP unit cannot perform floating-point operations.
-
Since NEON SIMD operations execute vector calculations more efficiently, the vector mode operations in the VFP unit have been deprecated since the introduction of ARMv7. Therefore, the VFP unit is sometimes referred to as the floating-point unit (FPU).
-
VFP can provide fully IEEE-754 compliant floating-point operations, while _single-precision operations in the ARMv7 NEON unit are not fully compliant with IEEE-754_.
-
NEON cannot replace VFP. VFP provides some dedicated instructions that do not have equivalent implementations in the NEON instruction set.
-
Half-precision instructions are only available on systems with half-precision extensions in both NEON and VFP.
-
In ARMv8, VFP has been replaced by NEON, resolving the issues such as NEON not fully complying with the IEEE 754 standard and the lack of some instructions supported by VFP but not by NEON.
3. NEON
NEON is a 128-bit SIMD extension architecture for ARM Cortex-A series processors, with each processor core having a NEON unit, enabling multi-threaded parallel acceleration.
1. Basic Principles of NEON
1.1 NEON Instruction Execution Flow
The above figure illustrates the flowchart of the NEON unit completing accelerated calculations. Each element in the vector register executes calculations synchronously, thereby speeding up the computation process.
1.2 NEON Computing Resources
-
Relationship between NEON and ARM Processor Resources
– The NEON unit, as an extension of the ARM instruction set, uses 64-bit or 128-bit registers for SIMD processing, running on the 64-bit register file. – NEON and VFP units are fully integrated into the processor and share processor resources for integer operations, loop control, and caching. Compared to hardware accelerators, this significantly reduces area and power costs. Additionally, it uses a simpler programming model because the NEON unit shares the same address space as the application.
-
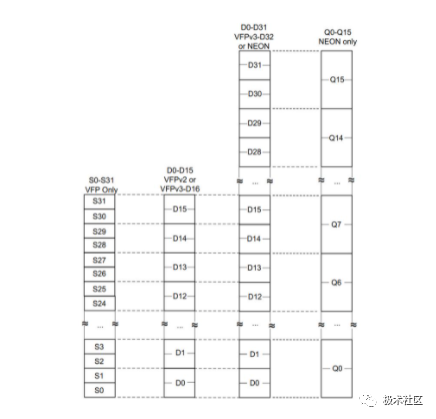
Relationship between NEON and VFP Resources
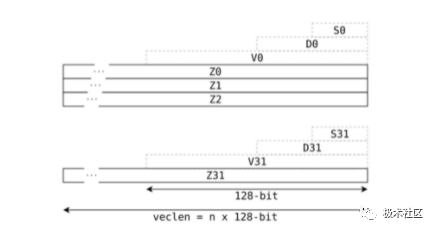
NEON registers overlap with VFP registers; ARMv7 has 32 NEON D registers, as shown in the figure below.
2. NEON Instructions
2.1 Auto Vectorization
Vectorizing compilers can use C or C++ source code to vectorize in a way that effectively utilizes NEON hardware. This means that portable C code can still achieve the performance levels brought by NEON instructions.
To assist vectorization, set the number of loop iterations to be a multiple of the vector length. Both GCC and ARM compiler toolchains have options to enable automatic vectorization for NEON technology.
2.2 NEON Assembly
For programs with particularly high performance requirements, manually writing assembly code is more suitable.
The GNU assembler (gas) and ARM Compiler toolchain assembler (armasm) both support the assembly of NEON instructions.
When writing assembly functions, it is important to understand ARM EABI, which defines how to use registers. The ARM Embedded Application Binary Interface (EABI) specifies which registers are used for passing parameters, returning results, or must be preserved, specifying the use of 32 D registers beyond the ARM core registers. The figure below summarizes the register functions.
2.3 NEON Intrinsics
NEON intrinsic functions provide a way to write NEON code that is easier to maintain than assembly code while still controlling the generated NEON instructions.
Intrinsic functions use new data types corresponding to D and Q NEON registers. These data types support creating C variables directly mapped to NEON registers.
Writing NEON intrinsic functions is similar to calling functions that use these variables as parameters or return values. The compiler handles some of the heavy lifting typically associated with writing assembly language, such as:
Register allocation, code scheduling, or instruction reordering.
-
Disadvantages of Intrinsics
It may not allow the compiler to produce the exact code desired, so there is still potential for improvement when transitioning to NEON assembly code.
NEON data processing instructions can be divided into normal instructions, long instructions, wide instructions, narrow instructions, and saturation instructions. For example, the long instruction of Intrinsic is int16x8_t vaddl_s8(int8x8_t __a, int8x8_t __b);– The above function adds two 64-bit D register vectors (each containing 8 8-bit numbers), generating a vector containing 8 16-bit numbers (stored in a 128-bit Q register), thus avoiding overflow of the addition result.
4. Other SIMD Technologies
1. SIMD Technologies on Other Platforms
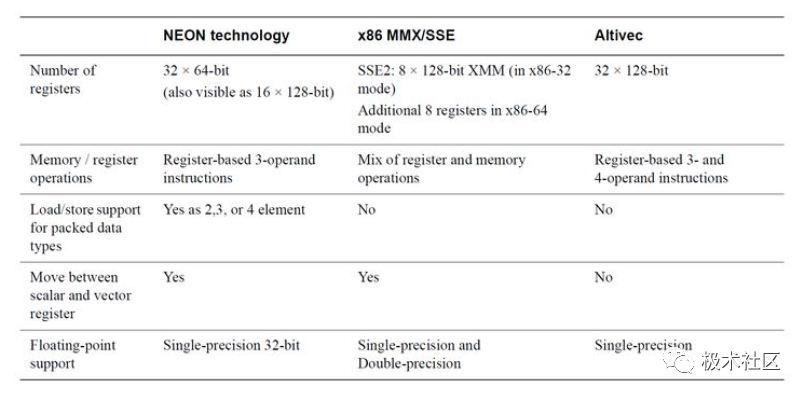
SIMD processing is not unique to ARM; the following figure compares it with x86 and Altivec.
2. Comparison with Dedicated DSP
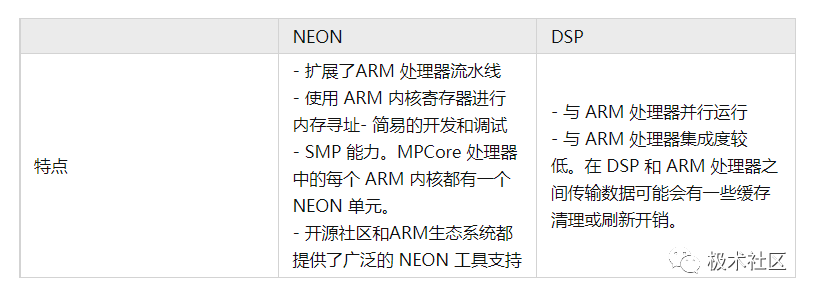
Many ARM-based SoCs also include co-processor hardware such as DSPs, allowing for simultaneous inclusion of NEON units and DSPs. Compared to DSP, NEON features include:
5. Conclusion
This section mainly introduces basic SIMD and other instruction flow and data flow processing methods, the basic principles of NEON, instructions, and comparisons with other platforms and hardware.
It is hoped that everyone can gain something.
Copyright belongs to the original author. If there is any infringement, please contact for deletion.
END
关于安芯教育
安芯教育是聚焦AIoT(人工智能+物联网)的创新教育平台,提供从中小学到高等院校的贯通式AIoT教育解决方案。
安芯教育依托Arm技术,开发了ASC(Arm智能互联)课程及人才培养体系。已广泛应用于高等院校产学研合作及中小学STEM教育,致力于为学校和企业培养适应时代需求的智能互联领域人才。