The original text is a discussion on Zhihu regarding “Is Huawei’s NPU Ascend chip a major strategic misstep, and should GPGPU have been chosen, leading to the CANN software stack facing obsolescence?” Many respondents provided insightful comments, and this article organizes the excellent responses from several contributors.
——————————————
The main text begins:
The essence of the issue is that GPGPU has a SIMT front end (which encapsulates a SIMD front end), achieving general scheduling and ease of programming, resulting in excellent out-of-the-box performance. In contrast, NPU/TPU still relies on traditional SIMD, where the pipeline must be manually orchestrated, and latency hiding is not as efficient as SIMT, making it very difficult and inefficient to write high-performance kernels, with ease of use being nearly impossible, and ecosystem development being far more challenging than GPGPU.
Compared to traditional SIMD NPU, SIMT has the advantage of ease of use, as developers do not need to struggle to fit data into suitable vector lengths. It addresses most of the SIMD datapath pipeline orchestration issues from a hardware design perspective. Threads can execute independently, allowing each thread to be relatively flexible, permitting different branches for each thread, while a group of threads executing the same instruction is dynamically organized into warps by hardware, enhancing the computational parallelism of SIMD.
SIMT uses warps to mask instruction pipelines based on runtime-specific information, enabling even non-expert CUDA developers to quickly write kernels with excellent out-of-the-box performance.
For SIMD NPU, however, developers and compilers can only orchestrate the pipeline based on static information, making it challenging to achieve sufficient balance, resulting in manual/compiler-automated pipeline orchestration being relatively difficult, even for experienced developers.
Below is the microarchitecture of the Ascend NPU, which shows that there are almost no control units, with the area entirely allocated to compute + memory units, leading to an exceptionally complex software stack for Ascend. From a training perspective, the GM (global memory) in the diagram is the intersection point for all AI core data, where MTE2 and MTE3 are responsible for GM data movement tasks. During training, a large amount of data needs to be moved between GM and UB, and if the bandwidth is insufficient, the training efficiency of the Cube kernel will not be high.
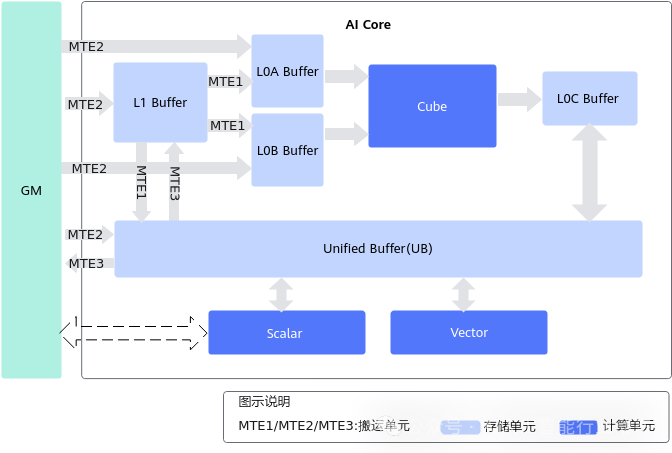
Therefore, although I often mock the weak control units of GPGPU, I must admit that at least they have control units. These control units have made many optimizations for parallel computing tasks, such as hardware thread switching, memory access control, and latency hiding.
In contrast, the NPU has almost no control units. If we analyze it according to traditional hardware classification methods, calling it a processor (PU) is quite forced; it might be more appropriate to call it a calculator/co-processor.
According to the traditional computer architecture analysis method of “processor-co-processor,” the structure of the NPU can be summarized as: CPU + NPU, while GPGPU is: CPU + GPU + DSA, corresponding to NV’s implementation as: CPU + CUDA core + Tensor Core.
Here, the GPU and DSA are not co-processors of equal status; rather, the CPU controls the GPU, which in turn controls the DSA.
This is why, despite the internal designs of Tensor Core and NPU being almost identical, we still do not consider the two to be the same in terms of architecture.
So why does the GPU need to control the DSA? Or more fundamentally, why does the GPU need control units?
In fact, early graphics cards, aside from differing tasks, had structures quite similar to today’s NPU, both being pure co-processors. However, unlike floating-point co-processors that were integrated into the CPU and eventually became part of the CPU, graphics cards have always been independent, and the physical distance of the bus means that the CPU’s control over the graphics card cannot be real-time. As tasks became more complex, it was inevitable that some real-time control logic would be integrated into the graphics card. This is also a commonly used control transfer strategy in hardware design.
However, if NV were to rely solely on such a mediocre strategy, it would not be considered a great company. NV’s strength lies not only in creating these control units but also in abstracting the SIMT programming model, which is a milestone achievement in the field of parallel computing.
Returning to the recent practices in the AI chip field, as tasks become increasingly complex and variable, this will objectively lead to the expansion of control units; only powerful control units can adapt to the ever-changing world. Although SIMT is no longer the best programming model for AI chips, AI computation, from a broad perspective, still belongs to parallel computing, and thus will inevitably encounter some common issues in parallel computing. At this point, people realize that NV’s GPU design, which superficially seems to merely apply a patch of Tensor Core, lacks innovation or boldness, but in practice, it turns out to be quite advantageous.
Therefore, it is entirely reasonable for HW to introduce a SIMT front end in the next generation of NPU products, the 910D.
On the surface, the gap between HW and NV appears to be that HW chose the wrong technical route. However, the more significant issue lies in HW’s lack of emphasis on programming models, or rather, that HW is currently not capable of meeting external expectations.
It should be noted that while both implement DSA, NV has also designed TMA; although this programming model cannot be compared with SIMT, it at least indicates that NV’s design is supported by a methodology. Whether HW’s NPU has a systematic programming model is currently in doubt.
The inherent hardware flaws of the Ascend products are not easily compensated for through software or compilers, as evidenced by Huawei’s large software optimization team and the actual performance of Ascend products in client applications.