Overview
The official PyTorch plugin provided by Huawei: <span>torch-npu</span> enables running PyTorch code on Huawei Ascend servers, facilitating AI development—training and inference—based on the open-source PyTorch ecosystem.
Although Huawei has its own machine learning development framework: MindSpore, similar frameworks exist from companies like Baidu and Alibaba, such as Baidu’s PaddlePaddle. Essentially, these frameworks are directly competing with PyTorch. However, a significant issue arises regarding the open-source ecosystem; currently, in the fields of machine learning and deep learning, the mainstream development frameworks are based on PyTorch, making its development ecosystem the most comprehensive. If companies limit themselves to their proprietary development frameworks, it can be detrimental to their hardware development and software ecosystem. Consequently, more hardware manufacturers, such as Huawei Ascend and Cambricon, are integrating PyTorch for development on their hardware platforms.
Adaptation and Integration
PrivateUse1
An important feature was released in PyTorch version 2.1: <span>PrivateUse1</span>; <span>PrivateUse1</span> is a type of device in PyTorch. In PyTorch, the device type indicates the hardware environment where tensors and operations are executed, with CPU and GPU being common device types. <span>PrivateUse1</span> is a special device type typically designed for custom or specific hardware backends. With <span>PrivateUse1</span>, developers can adapt PyTorch code to non-standard hardware, such as specific accelerators or experimental hardware platforms.
The source code of the torch-npu[1] plugin library provided by Ascend integrates the NPU device into the PyTorch backend through specific interfaces of <span>PrivateUse1</span>.
torch.utils.rename_privateuse1_backend("npu")
# rename device name to 'npu' and register funcs
torch._register_device_module('npu', torch_npu.npu)
unsupported_dtype = [torch.quint8, torch.quint4x2, torch.quint2x4, torch.qint32, torch.qint8]
torch.utils.generate_methods_for_privateuse1_backend(for_tensor=True, for_module=True, for_storage=True,
unsupported_dtype=unsupported_dtype)
Of course, having just this code is not enough; <span>PrivateUse1</span> is a special device type provided by PyTorch for third-party hardware vendors to integrate. By utilizing PyTorch’s PrivateUse1 feature, operations originally intended for CUDA devices (such as <span>torch.cuda</span>) can be seamlessly replaced with <span>torch.npu</span>, allowing hardware backend switching without modifying most native code. However, distributing operators to the <span>PrivateUse1</span> device requires additional mechanisms.
Dispatcher
<span>Dispatcher</span> is the official scheduling and dispatch mechanism of PyTorch, a key component in the core architecture of PyTorch. <span>Dispatcher</span>‘s main responsibility is to dispatch operations to the appropriate kernel functions based on the input tensor’s device type, data type, and other information. In simple terms, when you call an operation (like addition or multiplication) in PyTorch, <span>Dispatcher</span> determines which device the operation will execute on and which specific implementation will be used to complete the operation.
Roughly speaking, from an implementation perspective, dispatch is similar to Spring IOC; it essentially finds specific implementations for interface definitions to support extensions. Since the default operator implementations in PyTorch are on CPU and GPU, the dispatcher is introduced to facilitate operator extension and integration with third-party devices.
The dispatcher is essentially a large map/dictionary; when executing an operator, the dispatcher finds the corresponding dispatch key for that operator and then locates the appropriate kernel function based on that key.
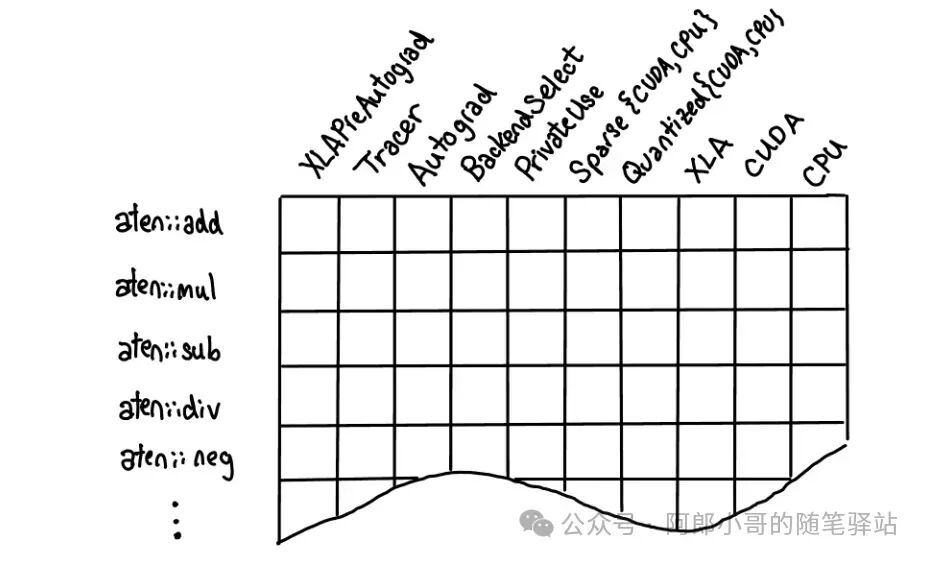
There are three ways to register operators, after which the dispatcher will dispatch the operators to the corresponding function implementations for execution.
- TORCH_LIBRARY_IMPL
- m.impl
- m.fallback
- TORCH_LIBRARY
- m.def
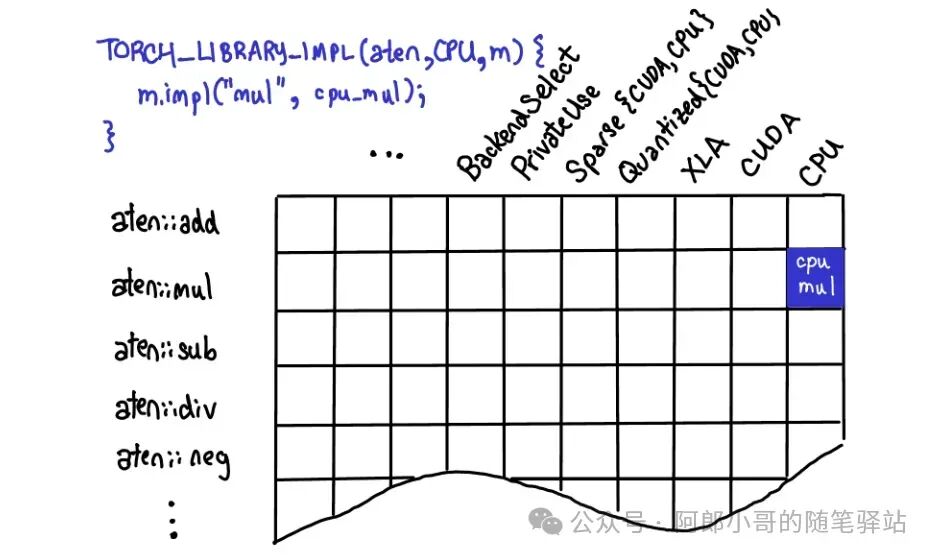
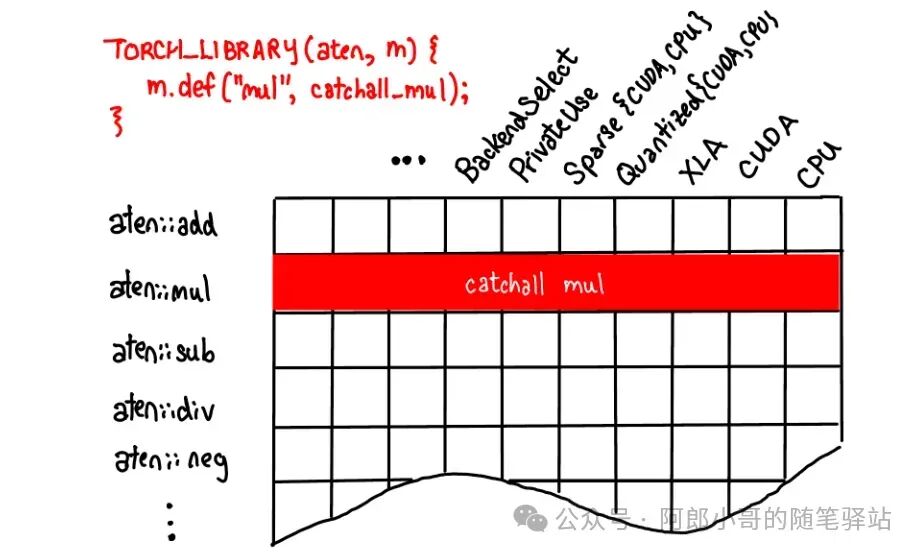
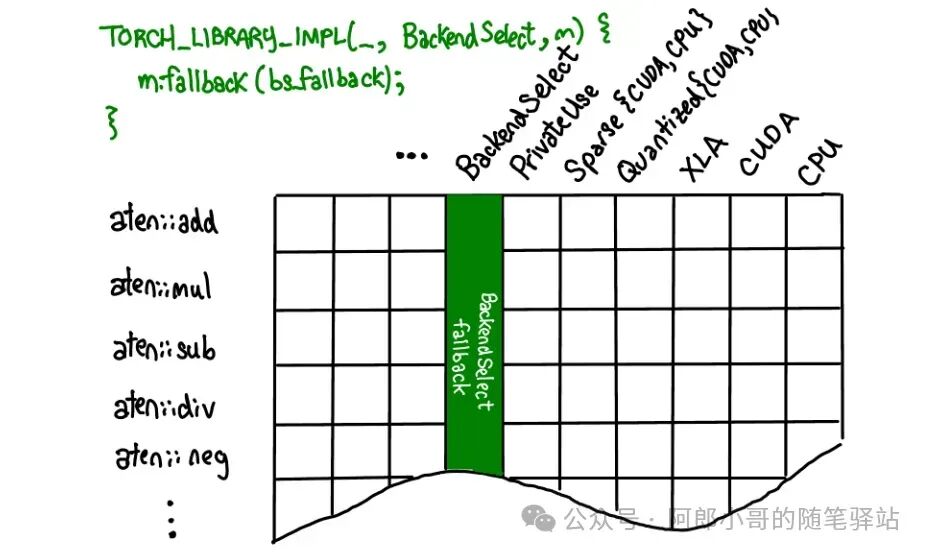
In the source code of the <span>torch-npu</span> plugin, various registration functions are present to call its own hardware on Huawei Ascend NPU to run various operators. This is why there are many versions of the torch-npu plugin provided by Ascend, which has been available since the PyTorch 1.x version. However, starting from PyTorch 2.1, the <span>torch-npu</span> plugin provided by Ascend can be considered as natively supporting PyTorch, and the MindSpeed series of training and inference acceleration middleware is heavily based on the <span>torch-npu</span> plugin.
OpenReg Example Project
The official PyTorch team has provided an example project[2] that demonstrates how to dispatch custom operators to new hardware using the <span>PrivateUse1</span> feature and dispatcher in an out-of-tree scenario.
csrc is the C++ code called by torch._C, implemented through pybind for Python to call C++.
The <span>_aten_impl.py</span> file registers some new operators and kernel fallbacks in the native aten of PyTorch, as follows:
_openreg_lib = torch.library.Library("_", "IMPL")
_openreg_lib.fallback(_openreg_kernel_fallback, dispatch_key="PrivateUse1")
_openreg_lib_aten = torch.library.Library("aten", "IMPL")
_openreg_lib_aten.impl("_copy_from", _copy_from, dispatch_key="PrivateUse1")
_openreg_lib_aten.impl(
"set_.source_Tensor", _set_source_tensor, dispatch_key="PrivateUse1"
)
_openreg_lib_aten.impl(
"_local_scalar_dense", _local_scalar_dense, dispatch_key="PrivateUse1"
)
The <span>_device_daemon</span> and <span>_meta_parser</span> handle device information and context metadata conversion.
References
OpenReg
Facilitating New Backend Integration through PrivateUse1[3]
Reference[1]
torch-npu: https://gitee.com/ascend/pytorch
[2]
Example Project: https://github.com/pytorch/pytorch/blob/main/test/cpp_extensions/open_registration_extension/pytorch_openreg/init.py
[3]
Facilitating New Backend Integration through PrivateUse1: https://pytorch.ac.cn/tutorials/advanced/privateuseone.html