
Qwen2.5-VL:the new flagship vision-language model of Qwen and also a significant leap from the previous Qwen2-VL.
Axera Tongyuan:an AI computing processor based on operator as the atomic instruction set. It efficiently supports mixed precision algorithm design and Transformers, providing a strong foundation for large models (DeepSeek, Qwen, MiniCPM, etc.) in “cloud-edge-end” AI applications.
https://www.axera-tech.com/Skill/166.html
TLDR
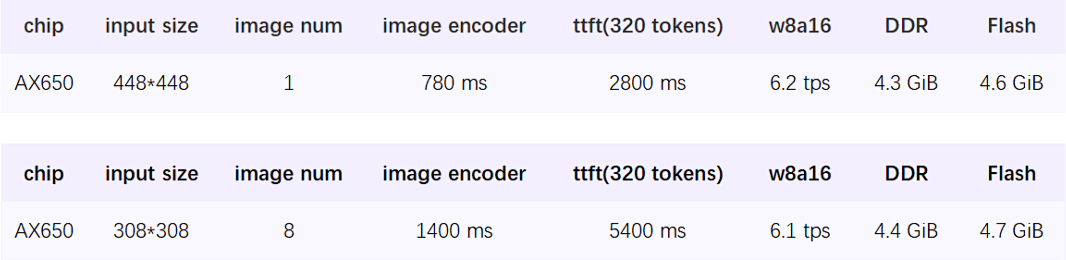
Background
Those familiar with the Axera Tongyuan NPU know that since last year, we have been actively keeping pace with the adaptation of multimodal large models on the edge. We have successively adapted the earliest open-source multimodal large model MiniCPM V 2.0, the Shusheng multimodal large model InternVL2.5-1B/8B/MPO from the Shanghai Artificial Intelligence Laboratory, and the world’s smallest multimodal large model SmloVLM-256M launched by Huggingface. This has provided the industry with a feasible solution for offline deployment of multimodal large models (VLM) to achieve efficient local understanding of images.
Starting from this article, we will gradually explore video understanding solutions based on VLM, allowing for greater imaginative space for intelligent upgrades of edge devices.
This article provides a brief overview of how VLM extends from image understanding to video understanding based on Qwen2.5-VL-3B, showcasing the latest adaptation status on the Axera Tongyuan NPU platform, and finally brainstorming some potential product landing scenarios.
Qwen2.5-VL
Qwen2.5-VL is a visual multimodal large model open-sourced by the Tongyi Qianwen team. So far, four scales have been open-sourced: 3B, 7B, 32B, and 72B, meeting the flexible deployment needs of different computing power devices.
-
Official Link:https://github.com/QwenLM/Qwen2.5-VL
-
Huggingface:https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
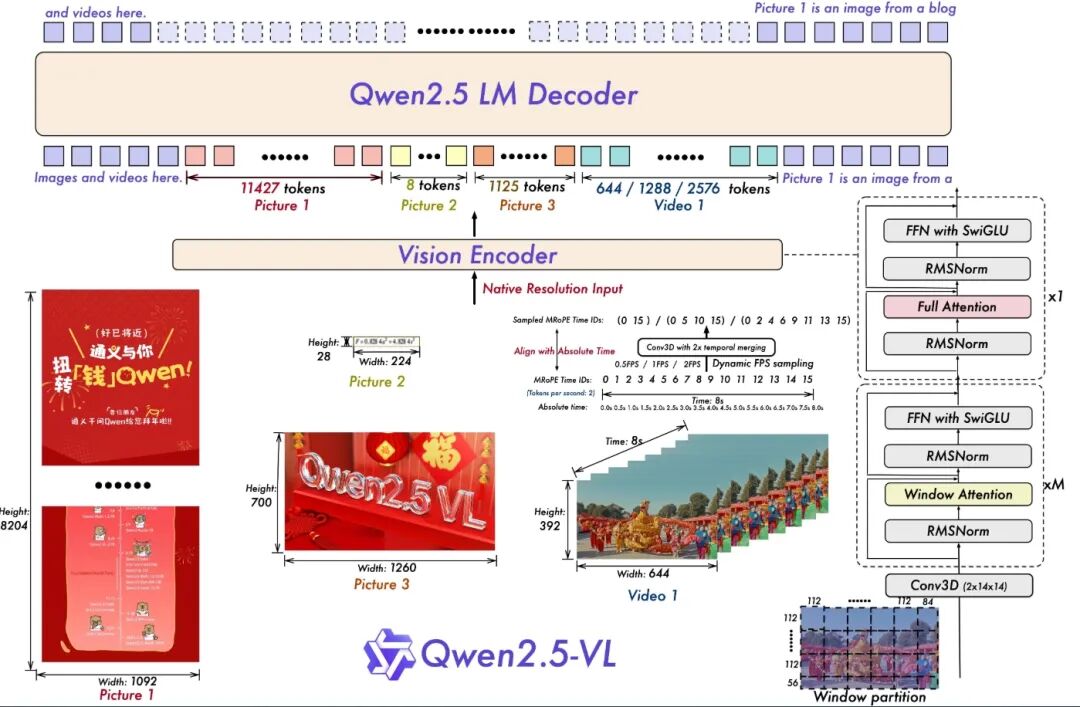
Qwen2.5-VL is an updated version of Qwen2-VL, and the following feature updates demonstrate the powerful capabilities and broad application prospects of Qwen2.5-VL in the field of visual-language processing.
Enhanced Features
-
Visual Understanding Ability:Qwen2.5-VL excels not only in recognizing common objects such as flowers, birds, fish, and insects but also efficiently analyzes text, charts, icons, graphics, and layouts within images;
-
Ability as a Visual Agent:The model can directly act as a visual agent, possessing reasoning capabilities and dynamic tool guidance, suitable for use on computers and mobile phones;
-
Long Video Understanding and Event Capture:Qwen2.5-VL can understand video content exceeding one hour and has added the ability to capture events by accurately locating relevant video segments;
-
Visual Localization in Different Formats:The model can accurately locate objects in images by generating bounding boxes or points, providing stable JSON output containing coordinates and attributes;
-
Structured Output:For scanned invoices, tables, forms, and other data, Qwen2.5-VL supports structured output of its content, which has significant application value in finance, business, and other fields.
Architecture Updates
-
Dynamic Resolution and Frame Rate Training for Video Understanding:By adopting dynamic FPS sampling, dynamic resolution is extended to the temporal dimension, allowing the model to understand videos at various sampling rates. Accordingly, we updated mRoPE with IDs and absolute time alignment in the temporal dimension, enabling the model to learn time series and speed, ultimately gaining the ability to locate specific moments.
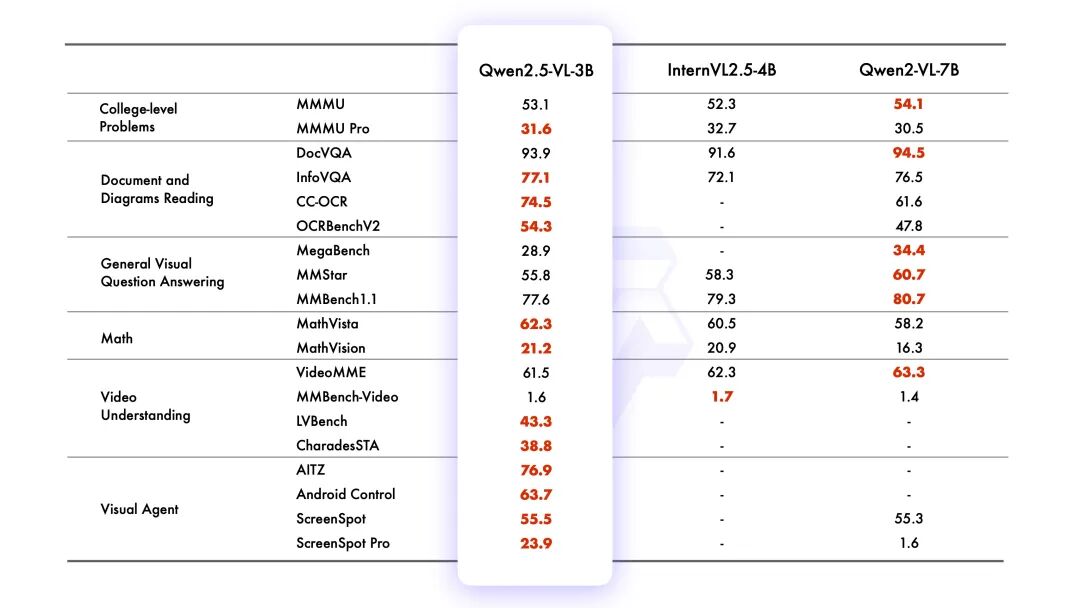
Performance Scores
Axera Tongyuan
Axera Tongyuan is the NPU IP brand independently developed by Axera Yuan Zhi. This article demonstrates examples based on the Axera Pi Pro (AX650N) with the built-in Axera Tongyuan NPUv3 architecture.
Axera Pi Pro
Equipped with Axera Yuan Zhi’s third-generation high-efficiency intelligent vision chip AX650N. It integrates an octa-core Cortex-A55 CPU, 18TOPs@INT8 NPU, and a VPU with H.264 and H.265 encoding/decoding. In terms of interfaces, AX650N supports 64bit LPDDR4x, multiple MIPI inputs, Gigabit Ethernet, USB, and HDMI 2.0b output, and supports 32 channels of 1080p@30fps decoding, providing high computing power and strong encoding/decoding capabilities to meet the industry’s demand for high-performance edge intelligent computing. By incorporating various deep learning algorithms, it achieves applications such as visual structuring, behavior analysis, and state detection, efficiently supporting large models with Transformer architecture. It provides rich development documentation to facilitate secondary development by users.

Model Conversion
We provide pre-compiled models on Huggingface and recommend using them directly.
If anyone wants to delve into how to convert the safetytensor model from the native Huggingface repository using the Pulsar2 NPU toolchain to generate axmodel models, please refer to our open-source project:
https://github.com/AXERA-TECH/Qwen2.5-VL-3B-Instruct.axera
Model Deployment
Pre-compiled Files
Available from Huggingface
https://huggingface.co/AXERA-TECH/Qwen2.5-VL-3B-Instruct
pip install -U huggingface_hubexport HF_ENDPOINT=https://hf-mirror.comhuggingface-cli download --resume-download AXERA-TECH/Qwen2.5-VL-3B-Instruct --local-dir Qwen2.5-VL-3B-InstructFile Description
root@ax650:/mnt/qtang/llm-test/Qwen2.5-VL-3B-Instruct# tree -L 1.|-- image|-- main|-- python|-- qwen2_5-vl-3b-image-ax650|-- qwen2_5-vl-3b-video-ax650|-- qwen2_5-vl-tokenizer|-- qwen2_tokenizer_image_448.py|-- qwen2_tokenizer_video_308.py|-- run_qwen2_5_vl_image.sh|-- run_qwen2_5_vl_video.sh`-- video-
qwen2_5-vl-3b-image-ax650:stores the axmodel file for image understanding
-
qwen2_5-vl-3b-video-ax650:stores the axmodel file for video understanding
-
qwen2_tokenizer_image_448.py:tokenizer parsing service suitable for image understanding
-
run_qwen2_5_vl_image.sh:execution script for image understanding example
Preparing the Environment
Use the transformer library to implement the tokenizer parsing service.
pip install transformers==4.41.1Image Understanding Example
First, start the tokenizer parsing service suitable for image understanding tasks.
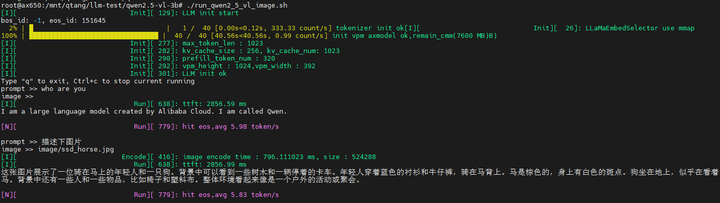
python3 qwen2_tokenizer_image_448.py --port 12345
Run the Image Understanding Example
./run_qwen2_5_vl_image.shInput Image

Input Text (prompt):Describe the image
Output Result
Input Text (prompt):Object detection, person wearing blue clothes, output the highest probability result
Output Result

After resizing the original image to 448×448 resolution, using the returned coordinate information [188, 18, 311, 278], the hand-drawn box result is quite accurate.

Video Understanding Example
First, extract 8 frames from a segment of the video at appropriate timestamps. Start the tokenizer parsing service suitable for video understanding tasks.
python qwen2_tokenizer_video_308.py --port 12345
Run the Video Understanding Example
./run_qwen2_5_vl_video.shInput Video
Input Text (prompt):Describe the video
Output Result
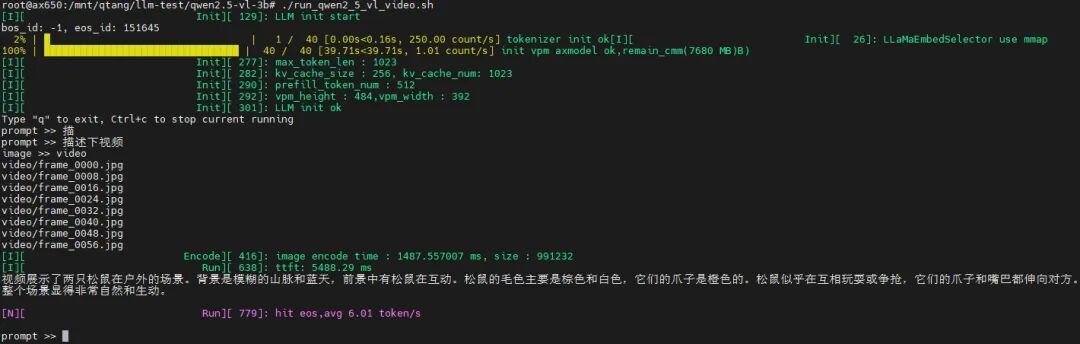
Application Scenario Discussion
Video understanding can combine information from the temporal sequence in the video, allowing for a more accurate understanding of real-world behavioral semantics.
-
Home Scenarios:Fall detection, fire detection
-
Industrial Scenarios:Defect detection, hazardous behavior detection
-
In-Vehicle Scenarios:Cabin and external environment perception
-
Other Scenarios:Wearable visual assistive devices
Conclusion
With the breakout of DeepSeek earlier this year, the general public has accepted the integration of large models with various aspects of daily life. Purely language-based large models can no longer meet the public’s needs; multimodal and full-modal large models have become the mainstream this year.
Axera Tongyuan NPU, combined with its native support for Transformers, high efficiency, and ease of use, will actively adapt to the industry’s excellent multimodal large models, providing a comprehensive hardware and software solution for efficient deployment of large models at the edge and end. This will promote “inclusive AI creating a better life.”
END


