Source: Zhuangzhi
This article introduces the thesis, recommended reading time 5 minutes.
A new trend is to utilize learning paradigms on devices, bringing the end-to-end ML process closer to edge devices.

Modern machine learning (ML) applications are often deployed in cloud environments to leverage the computing power of clusters. However, traditional cloud computing solutions cannot meet the needs of emerging edge intelligence scenarios, including providing personalized models, protecting user privacy, adapting to real-time tasks, and saving resource costs. To overcome the limitations of traditional cloud computing, a new trend is to utilize learning paradigms on devices, bringing the end-to-end ML process closer to edge devices. Thus, the promising advantages of learning on devices have facilitated the rise of micro machine learning (TinyML) systems, a field focused on developing ML algorithms and models on resource-constrained edge devices, such as microcontrollers, Internet of Things (IoT) sensors, and embedded devices. The term “micro” emphasizes the limited processing power, memory capacity, and energy resources on these devices. As discussed in §1.1 of the research background, TinyML has become an important research topic due to the growth of edge intelligence applications, including smart homes, wearables, robotics, and healthcare services. By applying TinyML systems on ubiquitous edge devices, developers and researchers can effectively reduce inference latency, save resource costs, enhance user experience, and protect user privacy.
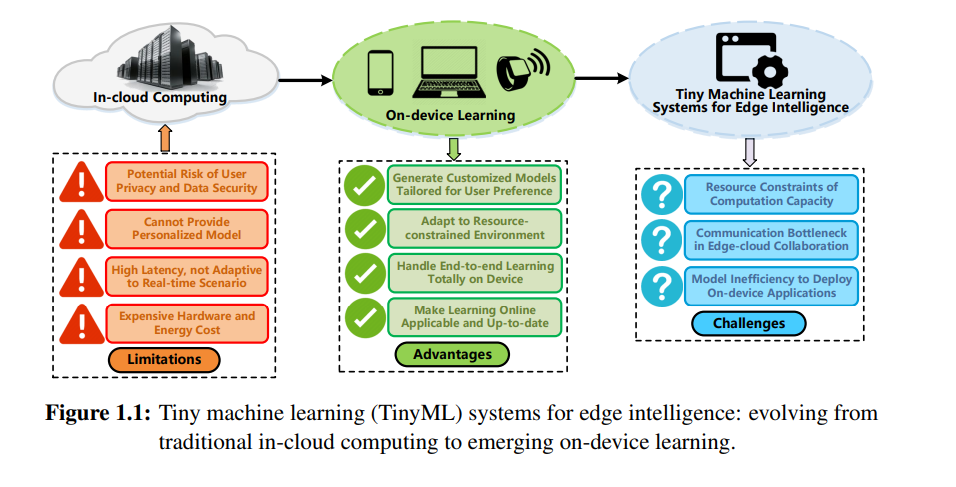
However, implementing a high-performance TinyML system in practice is not easy. We need to delve into infrastructure design and framework implementation from a full-stack system implementation perspective, including reducing data scale, model complexity, computational overhead, and communication traffic. To build an efficient TinyML system, we summarize three core challenges in system design and implementation in §1.2. These challenges inspired the design principles of our methodology, corresponding to the main contributions of this thesis in §1.3. More specifically, by conducting a comprehensive background review of TinyML systems in Chapter 2, we intend to optimize system design from three aspects: (1) utilizing INT8 quantization-aware training to break through the computational resource limitations on edge devices in Chapter 3, (2) leveraging hierarchical channel-space coding to alleviate communication bottlenecks during edge-cloud collaboration in Chapter 4, and (3) exploring patch automatic skip schemes to improve model execution efficiency on devices in Chapter 5.
First, as discussed in Chapter 3, we focus on breaking the constraints of limited resources, alleviating computational overhead, and discussing how to improve the computational speed of learning on devices. We demonstrate that using 8-bit fixed-point (INT8) quantization in the forward and backward passes of deep models is a promising way to enable learning on micro devices in practice. A key to an efficient quantization-aware training method is to utilize hardware-level acceleration while preserving the training quality of each layer. We implemented our method in Octo, a lightweight cross-platform system for learning on micro devices. Experiments show that Octo outperforms state-of-the-art quantization training methods in training efficiency while achieving appropriate acceleration in processing speed and memory reduction with sufficient precision training.
Secondly, as discussed in Chapter 4, we also cover continuous data analysis and video streaming applications. In this case, improving communication efficiency by reducing traffic size is one of the most critical issues in real-world deployments. Existing systems primarily compress features at the pixel level, neglecting the structural characteristics of features that can be further utilized for more effective compression. In this work, we achieve a scalable CL system through hierarchical compression of features, adopting a new insight called Stripewise Group Quantization (SGQ). Unlike previous unstructured quantization methods, SGQ captures spatial similarities in both channels and pixels, encoding features at both levels for higher compression ratios. Experiments show that SGQ can maintain learning accuracy consistent with the original full-precision version while significantly reducing traffic. This verifies that SGQ can be applied to a wide range of edge intelligence applications.
Thirdly, as discussed in Chapter 5, real-time video perception tasks on resource-constrained edge devices are often challenging due to accuracy degradation and hardware overhead issues, where saving computation is key to performance improvement. Existing methods primarily rely on domain-specific neural chips or previously searched models, which require specialized optimization based on different task attributes. These limitations inspired us to design a general and task-independent methodology called Patch Automatic Skip Scheme (PASS), which supports various video perception settings by decoupling acceleration from tasks. The key point is to capture inter-frame correlations and skip redundant computations at the patch level, where a patch is a non-overlapping square block in vision. Experiments show that applying PASS can enhance video perception performance on devices, including processing acceleration, memory reduction, computation savings, model quality, prediction stability, and environmental adaptability. PASS can be extended to real-time video streams on commercial edge devices, such as NVIDIA Jetson Nano, achieving efficient performance in real-world deployments.
In conclusion, TinyML is an emerging technology that paves the last mile for enabling edge intelligence, eliminating the limitations of traditional cloud computing, which requires substantial computational power and memory. Building an efficient TinyML system requires breaking the constraints of limited resources and alleviating computational overhead. Therefore, this thesis proposes a soft and hardware co-design for the implementation of TinyML systems. Extensive evaluations on commercial edge devices demonstrate significant performance improvements of our proposed system over existing solutions.





