Efficient TinyChat Engine
-
LLM Deployment Steps
-
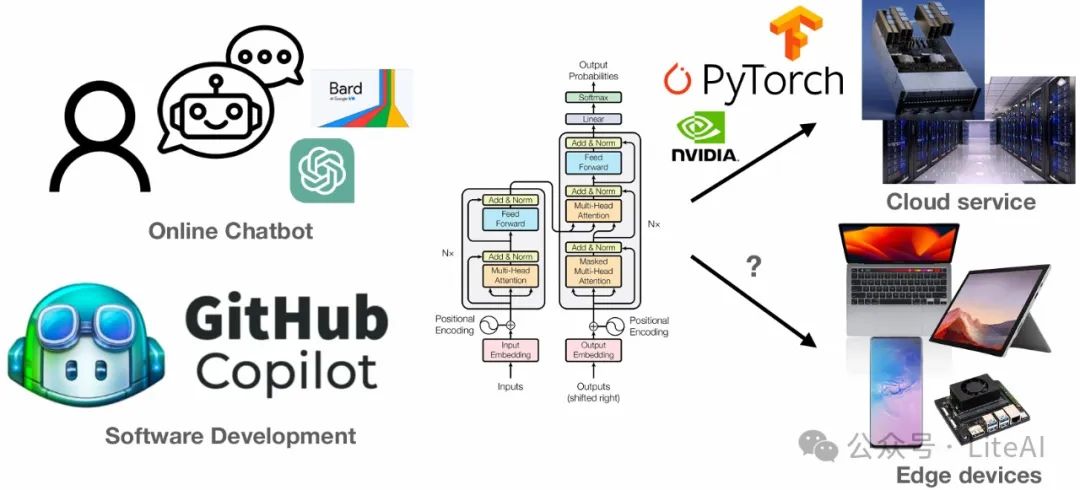
Introduction to TinyChat Engine
-
TinyChatEngine: An inference library designed for efficiently deploying quantized large language models (LLMs) on edge devices. -
General Framework -
No dependence on large libraries -
High performance -
Easy to use
-
TinyChat Engine includes: -
Pure C/C++ implementation -
LLM runtime control flow -
Various device-specific kernels -
Python toolchain model conversion and quantization -
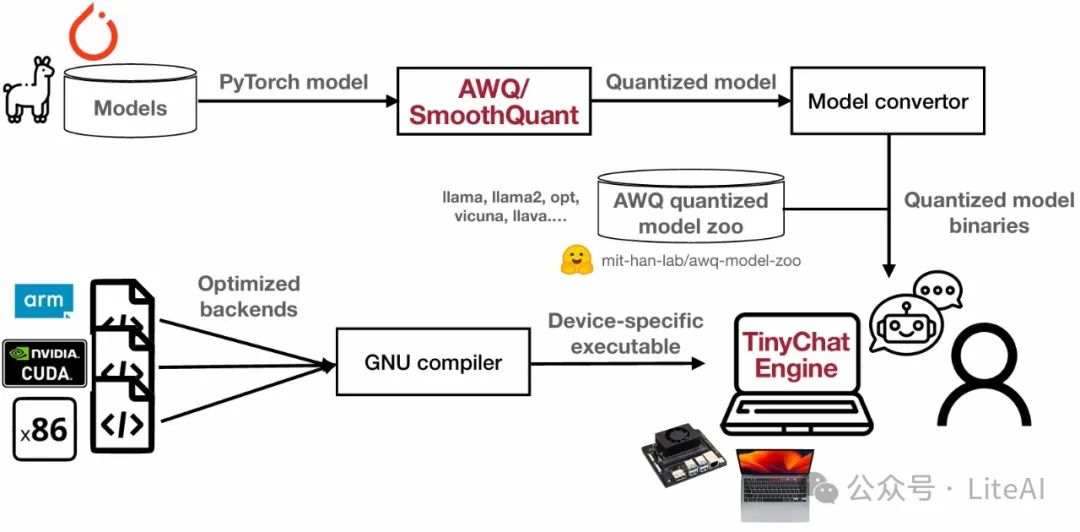
Workflow for deploying TinyChat Engine models: as shown in the figure below
-
Flexible backends and quantization methods: -
W8A8 quantization process (SmoothQuant)
– By default, activation values are stored as FP32 unless the device natively supports FP16
– Uses int8 operations for most operator calculations
– Provides kernels specifically for different output precision and activation functions
-
W4A16/W4A32 quantization process (AWQ)
– Applies low-bit computation only to compute-intensive linear layers
– Keeps the input and output of each operator as FP16/FP32
– Provides high-performance int4 linear kernels for CPU and GPU
-
High-performance int4 linear operators
– Utilizes int8 SIMD MAC operations to enhance performance
– Speeds up 1.3 times on Intel i7-9750H and 3 times on M1 Pro
– Improves efficiency through weight decoding and activation quantization
-
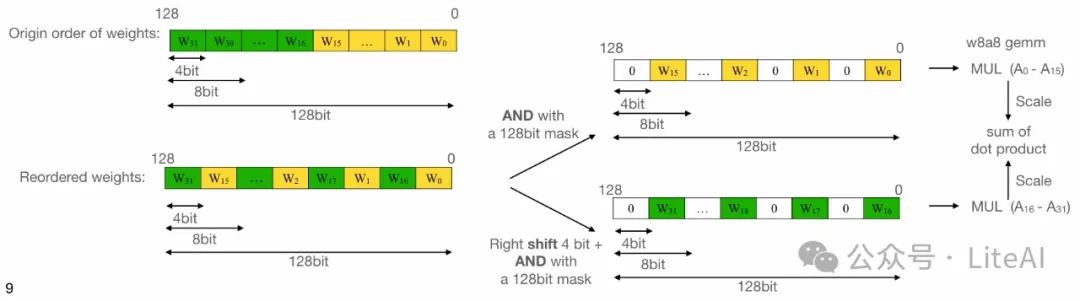
Device-specific weight reordering
– Reorders weights during model conversion to fit the operational bit width/kernel implementation on the device
– Eliminates runtime reordering to enhance performance
– Example demonstrates the process of weight decoding using ARM NEON (128-bit wide SIMD)
-
Efficient memory management
– Pre-allocates runtime buffers during initialization
– Reuses memory buffers to reduce memory footprint
– Utilizes unified memory on edge GPUs to reduce peak memory (e.g., Jetson Orin and Apple GPU)
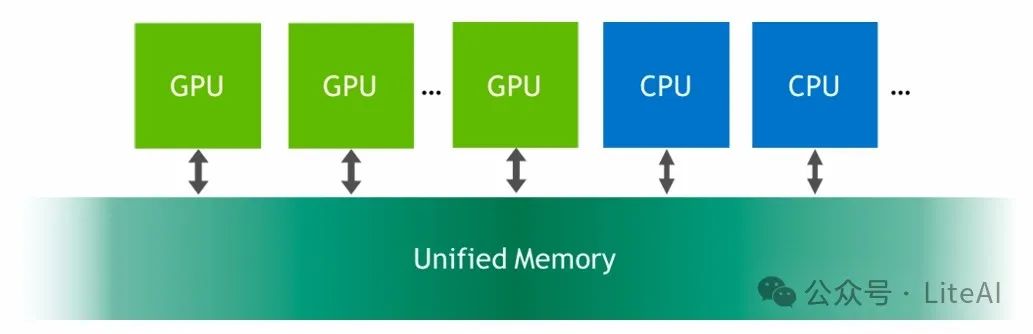
-
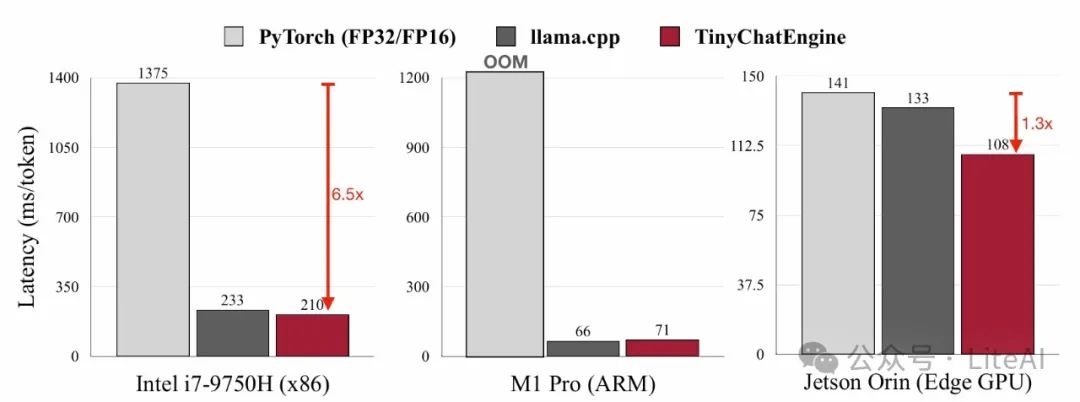
Efficient LLM deployment on edge devices
– TinyChatEngine achieves fast text generation of LLaMA2-7B on various devices
– Compared to PyTorch (FP32/FP16), TinyChatEngine shows significant performance improvements
-
Demo for deploying LLaMA2 chatbot
– Provides ready-to-use quantized models for download and deployment
– Demonstrates how to download the model, compile the program, and start the chatbot through examples
In Conclusion
Scan the code to add me, or add WeChat (ID: LiteAI01) for technical, career, and professional planning discussions, please note “Research Direction + School/Region + Name”