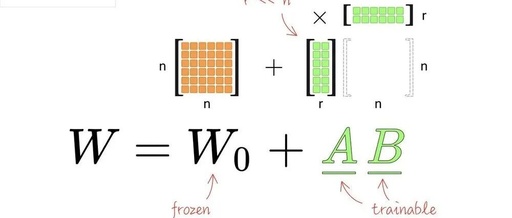Breaking Through the Three Major Challenges of Edge AI: How Large Models Achieve Efficient Inference and Decision-Making on IoT Devices (with Practical Code)

With the explosive growth of IoT devices, traditional pure cloud or pure edge architectures can no longer meet the balance of real-time performance, privacy security, and computational cost. This article proposes an edge-cloud collaborative architecture based on popular open-source large models, achieving millisecond-level environmental perception and autonomous decision-making through model hierarchical deployment, dynamic task offloading, … Read more