
Deep learning dominates various fields and fundamentally changes human society. Efficiency is a key factor in democratizing deep learning and expanding its application scope. This has become increasingly important as Moore’s Law slows down and the pace of model size expansion accelerates. We need efficient algorithms and systems to help bridge this gap.
In this paper, we will discuss technologies to enhance deep learning efficiency by eliminating redundancy. We explore efficient deep learning computation at the two extremes of scaling—Tiny Machine Learning (TinyML) and Large Language Models (LLMs).TinyML aims to run deep learning models on low-power IoT devices with tight memory constraints. We explore a system-algorithm co-design approach to eliminate redundant memory usage and implement practical applications on commercial microcontrollers, achieving the ImageNet 70% accuracy milestone for the first time. We further extend the solution from inference to training, enabling on-device learning with only 256KB of memory. Similar to TinyML, the enormous model size of LLMs also exceeds the hardware capabilities of even the most advanced GPUs. We developed post-training quantization schemes for different service workloads to reduce redundant bits in weights and activations, achieving W8A8 quantization (SmoothQuant) for compute-constrained inference and W4A16 quantization (AWQ) for memory-constrained scenarios. We further developed TinyChat, an efficient service system that natively supports Python, to achieve acceleration from quantization. Finally, we will discuss optimization opportunities in specific domains, including efficient video recognition using Time Shift Modules (TSM) and image generation using Anycost GANs, where we reduce redundancy in specific applications through dedicated model design.
Deep learning has achieved great success in various fields, including computer vision [150, 113, 71], natural language processing [277, 35, 68], image generation [98, 120, 137], and speech recognition [16, 222]. Over the years, the performance of various deep learning methods has rapidly increased due to the continuous emergence of new algorithms and the ongoing expansion of model and data sizes. In 2012, AlexNet [150], which ignited the deep learning era, had a model size of 60 million parameters (considered ‘large’ at that time), while the GPT-3 model [35] developed in 2020 has 175 billion parameters. We observe that in less than 8 years, model size has increased by 3⇥106 times. Even more impressively, the scaling trend has not slowed down even at this enormous scale [257, 208].
The continuous expansion of deep learning unlocks various emerging attributes. However, this expansion comes with increasing concerns about computational efficiency and energy consumption, affecting both training and inference processes. When it comes to inference or model deployment, even high-capacity GPUs like the NVIDIA H200, with 141GB of memory, cannot accommodate models as large as GPT-3, let alone the larger GPT-4. Efforts are being made to extend the services of these LLMs to a broader user base. Moreover, deploying deep learning at the edge can provide better privacy protection and faster response times, but it is also constrained by stricter hardware limitations. Energy consumption can easily drain the batteries of smartphones and even self-driving cars. On the other hand, training deep learning models requires more computation. The rising costs limit the scalability of training and can lead to a significant carbon footprint [261]. Therefore, if we want to democratize deep learning and bring greater benefits, especially in the post-Moore’s Law era, efficiency becomes a key factor.
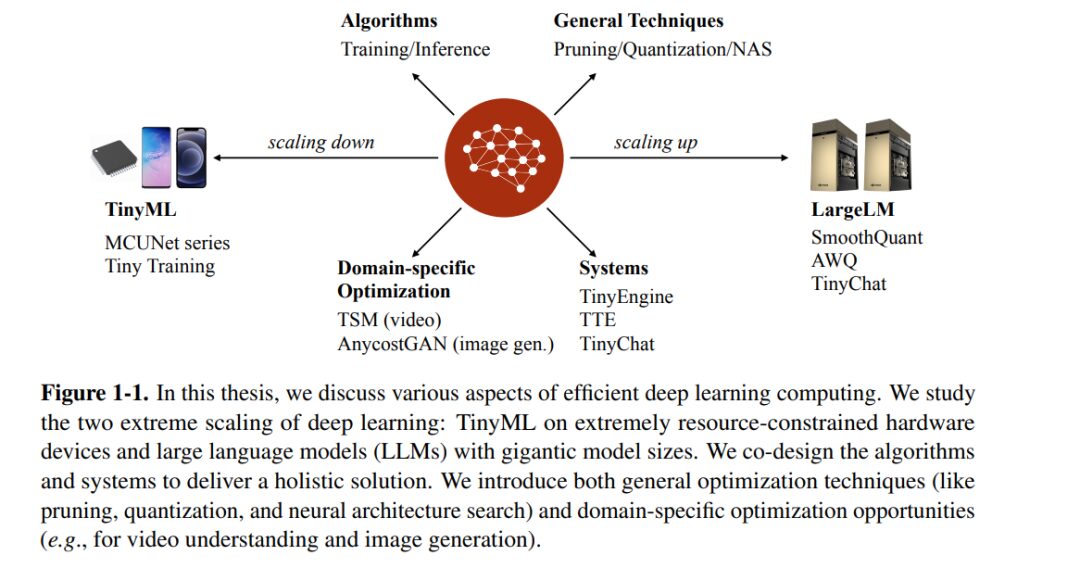
In this paper, we aim to address the efficiency bottleneck of deep learning by eliminating redundancy. We investigate the two extremes of scaling: Tiny Machine Learning (TinyML) and Large Language Models (LLMs)(Figure 1-1). TinyML aims to run deep learning models on low-power IoT devices with tight memory constraints (e.g., 256KB), while LLMs, with over 100 billion parameters, exceed the capacity of the most powerful GPUs. Despite the gap between them exceeding six orders of magnitude, we find that they actually face the same fundamental bottleneck: deep learning models exceed hardware capacity. We develop efficient deep learning algorithms and systems to help bridge this gap.
Specifically, for TinyML, we adopt a system-algorithm co-design to reduce redundant memory usage and build the MCUNet series [168, 167], which enables practical applications on commercial microcontrollers and achieves the ImageNet 70% accuracy milestone for the first time. Our MCUNet models are optimized through TinyNAS with feedback from TinyEngine, essentially integrating system and algorithm feedback in the same optimization loop. This joint optimization reveals unique optimization opportunities, such as patch-based high-resolution input inference [167], which would not be possible if optimized separately. We further extend the solution from inference to training, enabling on-device learning with only 256KB of memory [174].
For efficient LLMs, we eliminate redundant bits in weights and activations to reduce the cost of LLM inference. Quantization of LLMs allows us to reduce memory bandwidth and leverage low-bit instructions, which have higher throughput. Our work implements W8A8 quantization (SmoothQuant) [304] for cloud batch services, which are compute-constrained; and W4A16 quantization (AWQ) [172] for single-query services at the edge, which are typically memory-constrained. Different quantization schemes address different hardware bottlenecks based on unique workload characteristics. We further co-design TinyChat [172], an efficient service system that natively supports Python, which translates theoretical savings into practical acceleration, achieving >3x speedup across various devices.
In addition to the general optimization techniques discussed above for visual and language backbones (CNNs and transformers) such as pruning, quantization, and neural architecture search, we should also explore optimization opportunities in specific domains to further reduce redundancy and improve efficiency. A good example is video understanding: videos can be viewed as a series of consecutive images, which exhibit high mutual information and redundancy due to temporal continuity. Using 3D CNNs for spatiotemporal modeling leads to enormous computational costs. The Time Shift Module (TSM) [170] we propose explores temporal redundancy and achieves 3D CNN performance at 2D cost. Another example is using Generative Adversarial Networks (GANs) for image editing, which often requires seconds for inference, hindering interactive experiences. We drew inspiration from the rendering pipeline and trained Anycost GANs [173], providing quick previews by reducing redundant high-resolution details and model capacity during the editing process. Both optimizations are tailored to the specific attributes of applications and cannot be covered by general model optimization techniques.



Convenient Access to Specialized Knowledge
Convenient Download, please followSpecialized Knowledge public account (click the blue above to follow)
Reply or send a message “LM194” to obtain the download link for “Efficient Deep Learning Computation: From TinyML to LargeLM194-page PDF

Click “Read Original” to learn how to useSpecialized Knowledge, view100000+ AI-themed knowledge materials