Today, let’s talk about NPU.
While most people are familiar with common computing units like CPU and GPU, they may not fully understand the working principles and specific functions of NPU.

NPU stands for Neural Network Processing Unit, which is a neural network processor. As the name suggests, it is a computing unit specifically designed for AI applications. Therefore, compared to general computing units like CPU and GPU, NPU is theoretically a specialized computing unit that does not require generalization, meaning it is designed solely for AI acceleration.
Although the development and utilization of NPU are still in their infancy, with applications currently limited to a few functions like background blurring and noise reduction in cameras, the inherent architectural design of NPU allows it to achieve faster AI computation acceleration than GPU.
To understand this, we must first grasp how NPU accelerates neural networks at the hardware level.
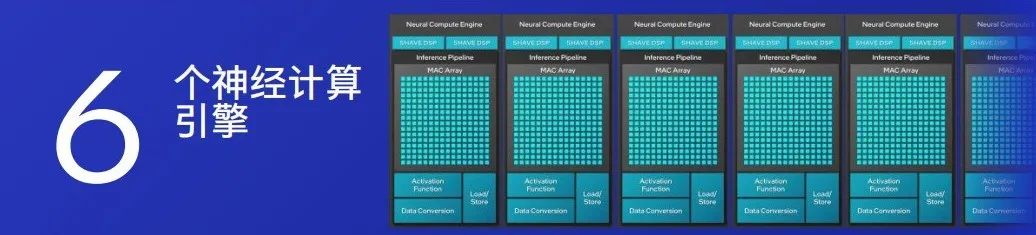
Meteor Lake, the first generation of Core Ultra, is Intel’s first processor to integrate NPU. From the NPU architectural design, we can see that its core consists of two neural computing engines, and the core of the core consists of two sets of MAC arrays (Multiplier and Accumulation).

We all know that AI large model inference computation essentially involves repeatedly performing matrix multiplication and addition, where the computation results first generate predicted data and continuously compute to fit the predicted data to the actual data as closely as possible, thereby minimizing the difference between predicted and actual data, ultimately inferring results and generating what is known as answers on the user side. The MAC arrays are designed for this purpose, so the more MAC arrays there are, the faster the multiplication and addition computations can be performed, leading to faster computation speeds, which in turn accelerates the fitting process, ultimately reflected in the application as an increased generation speed of AI large models.
The latest Lunar Lake, the second generation of Core Ultra processors, has increased the number of neural computing engines in the NPU to 6, and the number of MAC arrays has also expanded to 6 sets, theoretically tripling the computing power. However, since the main load of large model inference is currently on GPUs, the acceleration advantages of NPUs cannot yet be fully realized.
So why is NPU more suitable for AI computation acceleration?
First, let’s look at how GPUs perform matrix calculations.
For a simple 4×4 matrix multiplication, each number in every row and column must undergo 16 multiplications, resulting in a total of 16×4=64 multiplication calculations. Additionally, after each row and column’s numbers are multiplied, an addition must be performed, leading to a total of 16×3=48 addition calculations. Thus, the essence of GPU and NPU acceleration is to find ways to enhance the speed of these 64 multiplications and 48 additions.
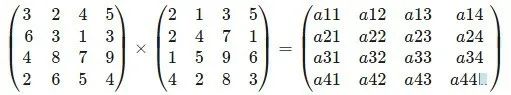
So how do GPUs and NPUs differ in computation?
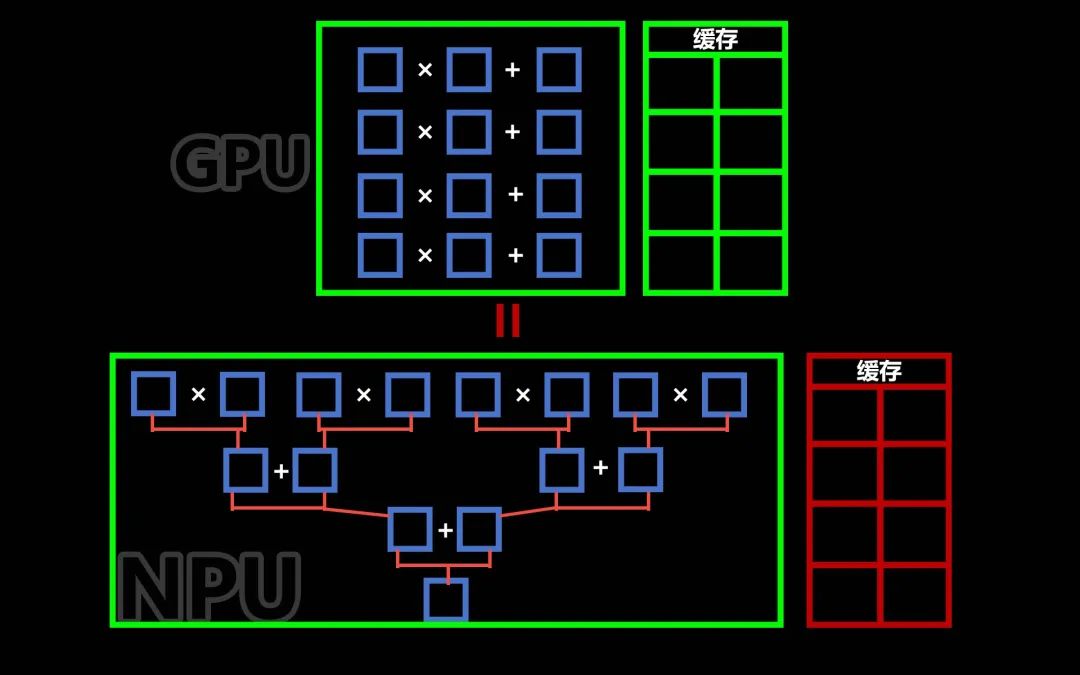
First, GPUs excel at parallel computation. They have multiple units that can perform multiplication and addition simultaneously. While parallel computation is very fast and can complete multiple tasks at once, before each computation, data must first be loaded into the cache, and then the GPU controller fetches the data from the cache to the multiplier to compute the results, after which the results are returned to the cache, and then the controller puts the computation results into the adder for summation, followed by returning the results to the cache, and finally summing the previously computed results in the adder to get the final result of a single multiply-add operation.

For example, to compute a11=3×2+2×2+4×1+5×4, the numbers must first be read into the cache as shown in the image above, then loaded into the multiplier to compute the results of 3×2, 2×2, 4×1, and 5×4, and the results 6, 4, 4, and 20 are returned to the cache. This process is referred to as [Instruction 1: Multiplication].
Next, the numbers 6, 4, 4, and 20 are placed into the adder to compute the sums of 6+4 and 4+20, returning 10 and 24 to the cache. This process is referred to as [Instruction 2: Addition].
Finally, the numbers 10 and 24 are placed into the adder to compute the sum of 10+24, resulting in 34. This process is referred to as [Instruction 3: Addition].
Thus, to complete a 4×4 matrix calculation, the above process needs to be “copied” 15 more times to finish the matrix calculation task. In other words, using a GPU to compute a 4×4 matrix requires only 3 instructions, which is already quite fast.
However, as described, performing a simple 4×4 multiplication and addition matrix calculation requires going through a series of steps: cache – multiplier – cache – adder – cache – adder. For larger matrix calculations, the speed inevitably slows down. For instance, the full-scale DeepSeek-R1 has a parameter count of 671B, which means that performing matrix multiplication and addition on such a massive dataset puts significant pressure on hardware performance.
Is there a faster method than “3 instructions”?
Indeed, clever readers may have noticed that the GPU has to move data back and forth between the calculator and the cache for each computation, so simplifying this step would speed things up.
Exactly, the architectural design of NPU simplifies the need to access the cache for each computation.
As shown in the diagram below, the NPU’s computing array utilizes newly established pipelines (indicated in orange) to directly connect the multipliers and adders, allowing intermediate results from the multipliers to flow directly into the adders for addition, thus requiring only one instruction to automatically complete the entire process from multiplication to addition.
This is the fundamental reason why NPU, as a dedicated AI computing unit, is actually more suitable for AI accelerated computing than GPU. Moreover, because it is a specialized computing unit, its upgrade direction can be entirely focused on improving computational efficiency.
Of course, there is no strict superiority or inferiority in the architectural designs of GPUs and NPUs.
GPU is a general-purpose computing unit, and its calculator design can satisfy the free construction of computational formulas.
On the other hand, NPU is a specialized computing unit, which does not require such high flexibility, allowing for the addition of pipelines to perform specific formula calculations.
For example, GPUs can compute formulas like a×b+c×d×e×f or a×b+c×d×e+f, while NPUs can mostly only compute formulas like a×b+c×d+e×f.
Of course, the NPUs designed by Intel, AMD, and Apple may have different calculator architectures, such as multiply-add-multiply or multiply-add-multiply-add, etc., with different arrangements determining the internal data flow. Additionally, different architectural designs and matrix scales will determine which data types they excel at computing. For instance, the commonly mentioned FP16, INT8, INT4, etc., have computation speeds directly related to the design of the multiply-add calculator architecture and matrix scale.
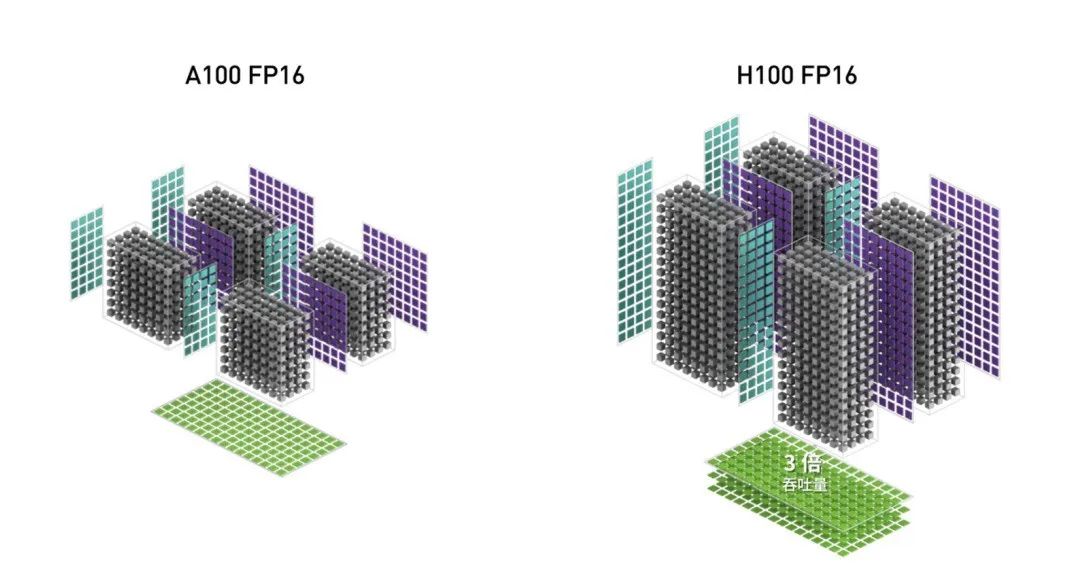
As shown in the diagram below, for the same FP16 precision computation, the A100 matrix scale is much smaller than that of the H100, so the latter’s computation speed is naturally faster.
Furthermore, in the AI era, computing units like GPUs and NPUs have already diverged from traditional definitions. For instance, the TensorCore in NVIDIA cards is specifically designed for AI computation matrix units. Some NPU computing units, in addition to containing matrix arrays dedicated to AI computation, also integrate vector, scalar computing units, and even CPU cores to better meet the diverse operator requirements during AI computation.