National Key Laboratory of Cognitive Intelligence & Huawei Noah’s Ark SubmissionQuantum Bit | WeChat Official Account QbitAI
The generative recommendation large model has been successfully deployed on domestically produced Ascend NPU for the first time!
In the era of information explosion, recommendation systems have become an indispensable part of life. Meta was the first to propose the generative recommendation paradigm HSTU, expanding recommendation parameters to the trillion level and achieving significant results.
Recently, USTC and Huawei collaborated to develop a deployment solution for the recommendation large model, applicable in various scenarios.
What experiences and discoveries were made during the exploration? The latest public sharing is here.
Highlights of the report include:
- Summarizing the development history of recommendation paradigms, pointing out that the generative recommendation paradigm with scalability laws is the future trend;
- Reproducing and studying generative recommendation models of different architectures and their scalability laws; through ablation experiments and parameter analysis, analyzing the source of HSTU’s scalability laws and endowing SASRec with scalability;
- Validating HSTU’s performance and scalability in complex scenarios and ranking tasks;
- The team looks forward and summarizes future research directions.
The generative recommendation paradigm with scalability laws is becoming the future trend
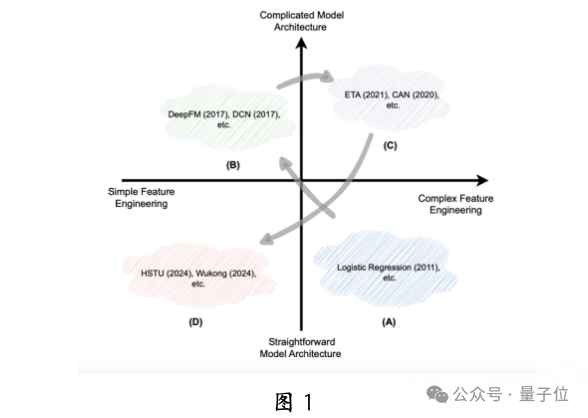
As shown in Figure 1, the development trend of recommendation systems is gradually reducing reliance on manually designed feature engineering and model structures. Before the rise of deep learning, limited by computational resources, people tended to use manually designed features and simple models (Figure 1A).
With the development of deep learning, researchers focused on designing complex models to better fit user preferences and enhance the utilization of GPU parallel computing (Figure 1B).
However, with the bottleneck of deep learning capabilities, feature engineering has once again received attention (Figure 1C).
Today, the success of the scalability laws of large language models has inspired researchers in the recommendation field. Scalability laws describe the power-law relationship between model performance and key metrics (such as parameter scale, dataset scale, and training resources). By increasing model depth and width, combined with large amounts of data, recommendation effectiveness can be improved (Figure 1D), a method known as the recommendation large model.
Recently, generative recommendation frameworks like HSTU have achieved significant results in this direction, validating the scalability laws in the recommendation field and sparking a wave of research on generative recommendation large models.The team believes that generative recommendation large models are becoming the next new paradigm to disrupt current recommendation systems.
In this context, exploring which models truly possess scalability, understanding the reasons for their successful application of scalability laws, and how to leverage these laws to enhance recommendation effectiveness has become a hot topic in the current recommendation system field.
Scalability Analysis of Generative Recommendation Large Models Based on Different Architectures
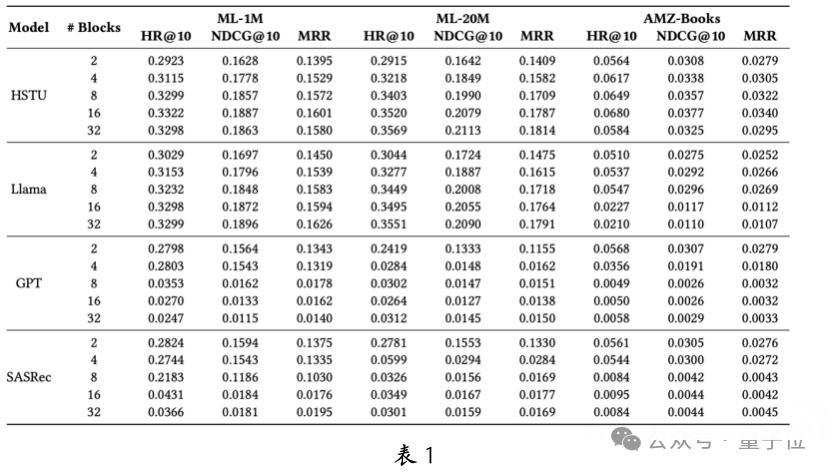
To evaluate the scalability of generative recommendation large models under different architectures, the team compared four Transformer-based architectures: HSTU, Llama, GPT, and SASRec.
On three public datasets, performance was analyzed based on the number of different attention modules (see Table 1). The results show that when model parameters are small, the performance of each architecture is similar, and the optimal architecture varies by dataset.
However, as parameters scale up, the performance of HSTU and Llama significantly improves, while GPT and SASRec show insufficient scalability. Although GPT performs well in other fields, it did not meet expectations in recommendation tasks.The team believes this is because the architectures of GPT and SASRec lack key components specifically designed for recommendation tasks, preventing effective utilization of scalability laws.
Analysis of the Sources of Scalability in Generative Recommendation Models
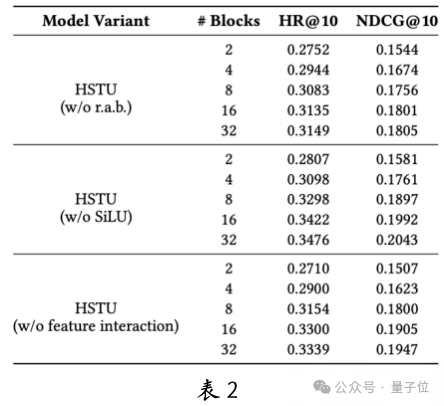
To explore the sources of scalability in generative recommendation models like HSTU, the team conducted ablation experiments, removing key components from HSTU: Relative Attention Bias (RAB), SiLU activation function, and feature crossing mechanism.
The experimental results (see Table 2) show that the absence of a single module did not significantly affect the model’s scalability, but the removal of RAB led to a noticeable decline in performance, indicating its critical role.
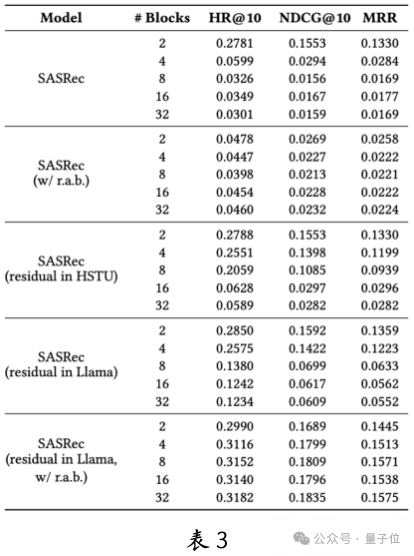
To further analyze the factors that endow the model with scalability laws, the team compared SASRec with the scalability-strong HSTU and Llama, finding that the main differences lie in RAB and the residual connection method within the attention module.
To verify whether these differences are key to scalability, the team introduced HSTU’s RAB to SASRec and adjusted its attention module implementation.
The experimental results (see Table 3) show that adding RAB alone or modifying the residual connection did not significantly improve SASRec’s scalability. However, when both components were modified simultaneously, SASRec exhibited good scalability. This indicates that the combination of the residual connection pattern and RAB endows traditional recommendation models with scalability, providing important insights for future scalability exploration in recommendation systems.
Performance of Generative Recommendation Models in Complex Scenarios and Ranking Tasks
Performance in Complex Scenarios
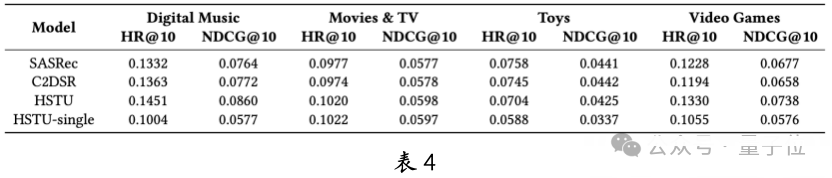
HSTU performs excellently in complex scenarios such as multi-domain, multi-behavior, and auxiliary information. For example, in multi-domain, HSTU consistently outperforms baseline models SASRec and C2DSR across four domains in AMZ-MD (see Table 4).
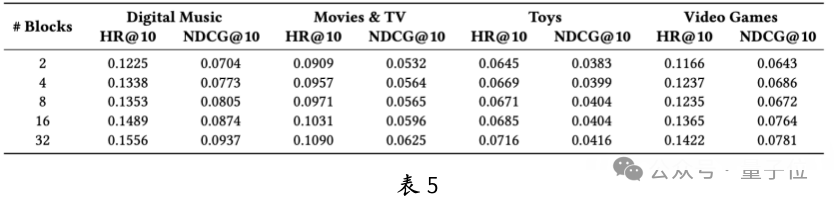
Compared to HSTU-single trained independently in a single domain, the multi-domain jointly trained HSTU performs better, proving the advantages of multi-domain joint modeling. Table 5 shows that HSTU’s scalability on multi-domain behavioral data is significant, especially in smaller scenarios like Digital Music and Video Games. This indicates HSTU’s potential in addressing cold start problems.
Performance in Ranking Tasks
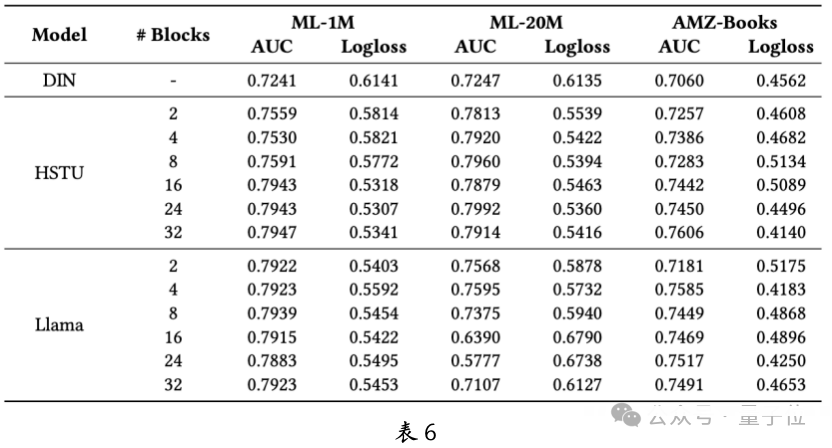
Ranking is a crucial part of recommendation systems, and the team delved into the effectiveness and scalability of generative recommendation models in ranking tasks. As shown in Table 6, generative recommendation large models significantly outperform traditional recommendation models like DIN in performance. Although Llama performs better than HSTU in small-scale models, HSTU has greater advantages in scalability, while Llama shows insufficient scalability.
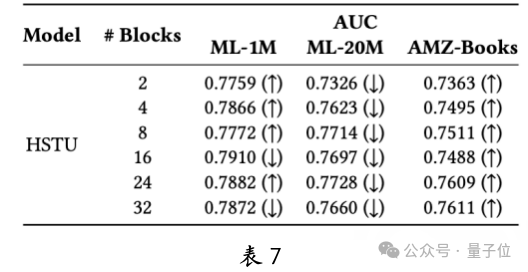
The team also studied the impact of negative sampling rates and scoring network architectures on ranking tasks and conducted a comprehensive analysis. Additionally, they explored the effect of reducing embedding dimensions on performance. Reducing embedding dimensions (Table 7) improved performance on small datasets like ML-1M and AMZ-Books, but decreased performance on larger datasets like ML-20M. This indicates that the scalability laws of recommendation large models are influenced not only by vertical scaling (number of attention modules) but also by horizontal scaling (embedding dimensions).
Future Directions and Summary
In the technical report, the team pointed out potential future research directions for recommendation large models, including data engineering, Tokenizer, and training inference efficiency, which will help address current challenges and broaden application scenarios.
Paper link: https://arxiv.org/abs/2412.00714Homepage link: https://github.com/USTC-StarTeam/Awesome-Large-Recommendation-Models
One-click three connections「Like」「Share」「Heart」
Feel free to leave your thoughts in the comments!
— End —
AcademicSubmissions should be emailed to:
Title should indicate 【Submission】, and tell us:
Who you are, where you are from, and the content of your submission
Include links to your paper/project homepage and contact information
We will (try to) respond to you promptly

🌟 Light up the star mark 🌟
Daily updates on cutting-edge technological advancements