On June 12, Walden Yan from Cognition just published an article titled “Don’t Build Multi-Agents”. The next day, Anthropic released a lengthy 6000-word practical summary titled “How we built our multi-agent research system”.
💥 Cognition’s Stance: Avoid Multi-Agents
The core viewpoint of Cognition co-founder Walden Yan:
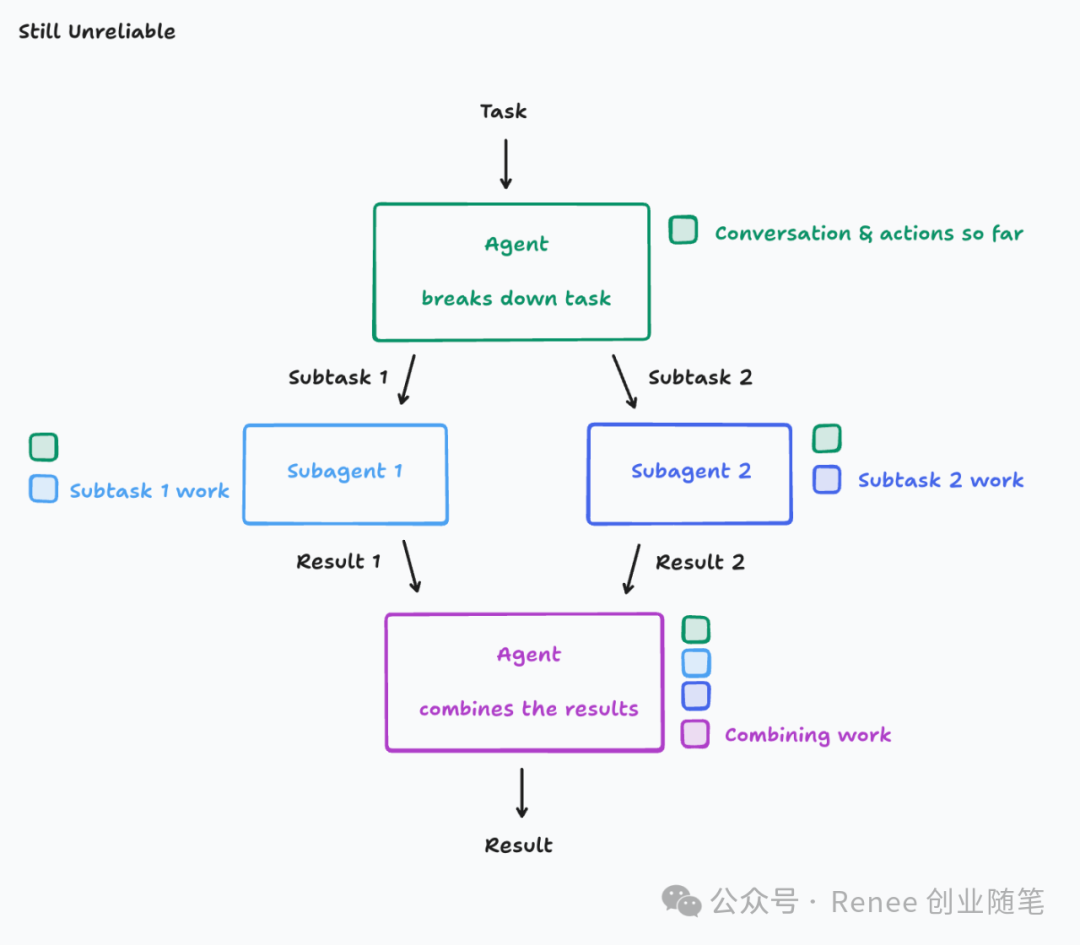
- Context fragmentation is the root cause of agent failure;
- Multiple agents can lead to misunderstanding tasks, inconsistent styles, and conflicting decisions;
The most stable architecture is: Single agent + linear context + precise memory compression;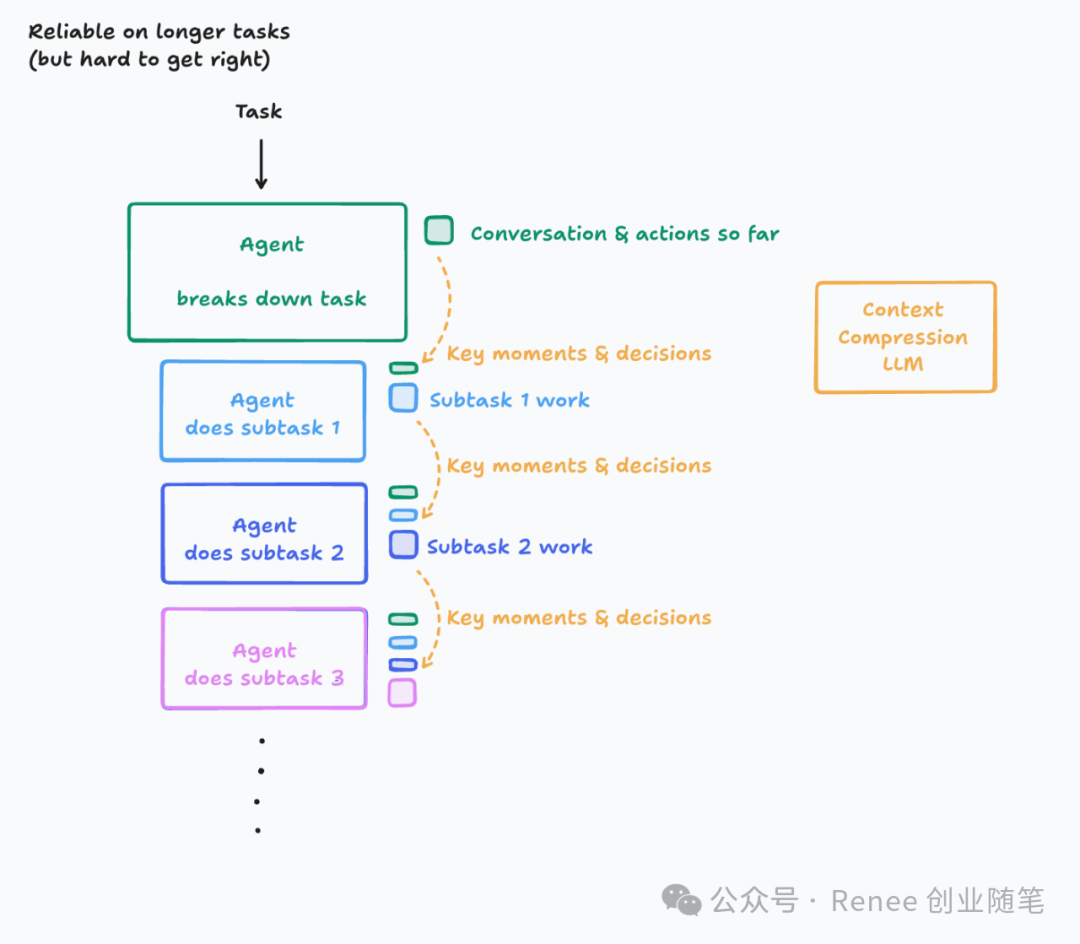
“Even with smart agents, once you break apart the context, everything breaks.” —— Walden Yan
🧪 Anthropic’s Counterattack: We Built Multi-Agents and Did It Well
Anthropic’s Claude Research system is a typical multi-agent parallel architecture:
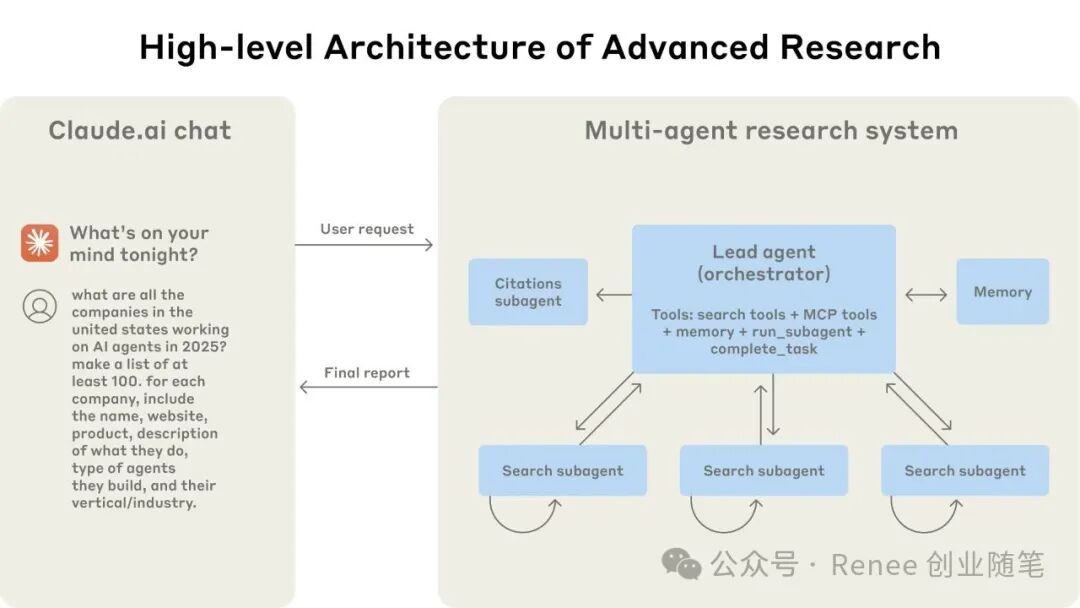
- A Lead Agent is responsible for planning research tasks;
- Simultaneously scheduling multiple Subagents to concurrently call tools for information search;
- Finally, a Citation Agent adds references to generate a complete report.
They found in practical evaluations that:
🎯 The combination of Claude Opus + Sonnet multi-agents is 90.2% more accurate than a single Claude Opus.
Especially suitable for complex open-ended tasks, such as:
- “Identify the board members of all IT companies in the S&P 500”
- “Conduct a horizontal survey of AI agent company development paths”
- “Build an AI medical decision support map”
🔍 Cognition’s Critique vs Anthropic’s Solutions
| Cognition’s Concerns | Anthropic’s Practical Engineering Solutions |
|---|---|
| ❌ Subagents easily misunderstand tasks | ✅ Orchestrator ensures precise division of labor and clear instruction formats |
| ❌ Conflicting decisions lead to merged errors | ✅ No shared context; the main agent is responsible for integration |
| ❌ Huge token consumption | ✅ Achieving 90% accuracy for high-value tasks is reasonable |
| ❌ Prompts are unstable and debugging is difficult | ✅ Claude self-optimizes prompts and iterates tool descriptions |
| ❌ Difficult to debug and deploy | ✅ Full-link tracing + rainbow deployment + checkpoint recovery |
🧩 The Key to Anthropic’s Successful Architecture
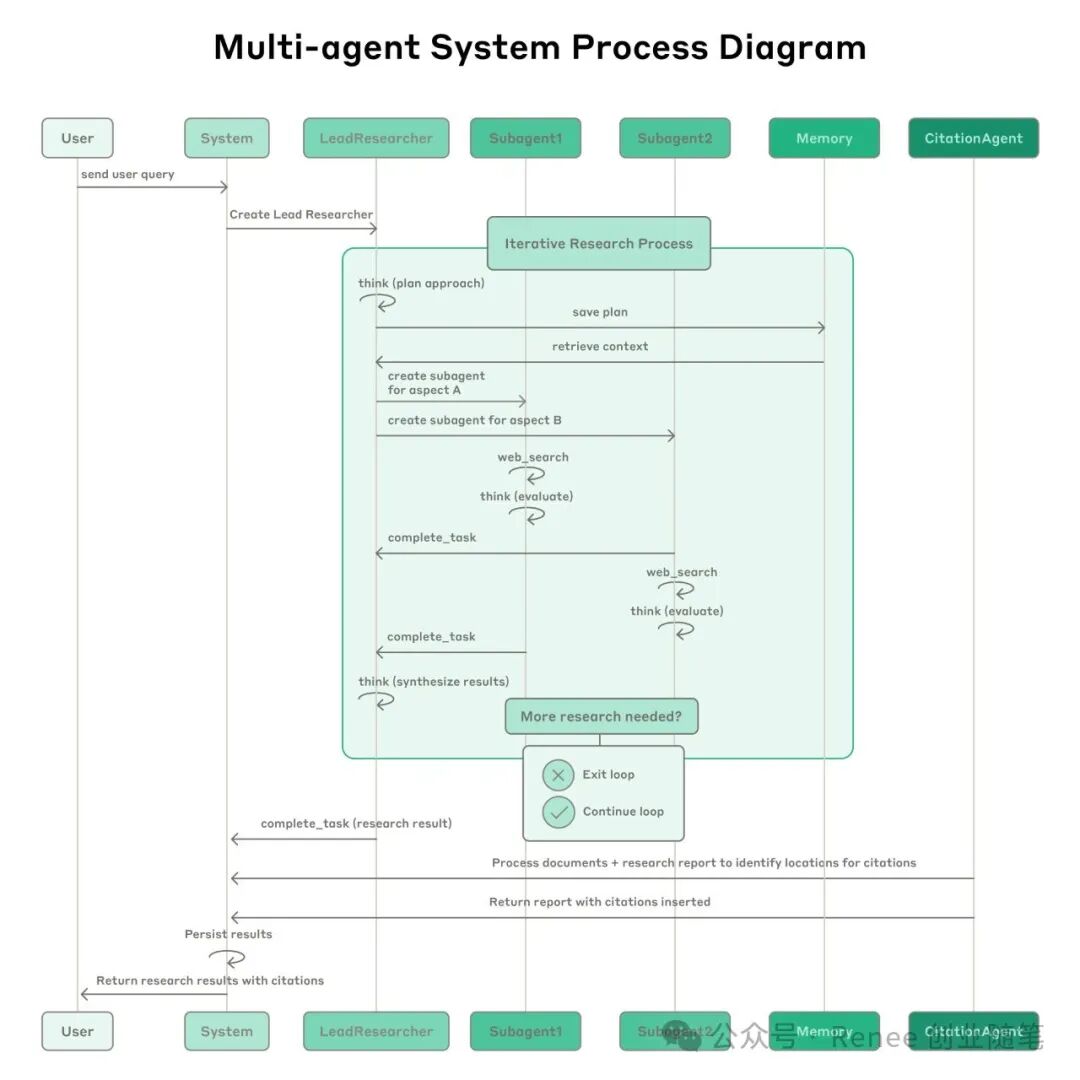
- 🧠 Lead Agent plans tasks → Subagents search concurrently → Citation Agent adds references
- 📦 Prompt engineering experience: Must include task objectives, output formats, tools used, and task boundaries
- 📚 Built-in “heuristics” in prompts: Broad to narrow, search then compress, avoid repetition and excessive searching
- 🔧 Claude can act as its own prompt engineer: Can rewrite prompts, optimize failure paths, and reduce tool usage errors
- 🚀 Concurrently calling 3-5 Subagents + each calling 3 tools → 90% speedup
📊 Which Architecture is Right for You?
| Type | Cognition Approach | Anthropic Approach |
|---|---|---|
| Programming Tasks | ✅ Stable, traceable | ❌ Subtask parallelism is not obvious |
| Forms, RPA Workflows | ✅ A single agent with tools is sufficient | ❌ Multiple agents are unnecessary |
| Research Tasks | ❌ Linear agent pressure is high | ✅ Multi-agent + concurrency is optimal |
| Enterprise Knowledge Search | ❌ Single-threaded is slow | ✅ Scalable, handles more context |
| User Interaction Agents | ✅ Coherent context | ❌ Multiple agents struggle to unify dialogue style |