

China’s computing chip sector is quietly undergoing transformation.

At the 2025 Huawei All-Connected Conference, Huawei released several heavyweight chip products, including the Ascend 950 series, 960, and 970 AI chips, and announced the product roadmap for Ascend AI chips over the next three years.
Among them, the 950 series features two different suffixes—PR (Prefill & Recommendation) and DT (Decoder & Training).
Traditional AI chips face resource contention issues when processing large model inference, and in internet platform companies, the memory capacity required for their recommendation algorithm inference models is also enormous. Achieving a balance between computing power, memory capacity, and memory bandwidth is key to improving the return on investment.
Huawei’s “P/D separation” design attempts to achieve this goal by configuring different computing power, memory capacity, and bandwidth for different application scenarios.
This design directly addresses the real challenges facing the Chinese AI market: being able to run the full version of DeepSeek has almost become a benchmark for evaluating AI computing systems domestically. However, to support 671 billion parameters, the cost difference alone for using different versions of memory can reach tens of thousands of dollars.
It can be said that the market demand of the Chinese AI industry has forced product innovation in domestic chips.
From a product perspective, the highlight of the conference was a strong industry signal:
1) Represented by DeepSeek, the application and foundational model industry is continuously and deeply driving the development of Chinese AI chips; further, benefiting from China’s vast data center infrastructure scale and future demand, the ecosystem of “Huawei-Haiguang-Others” has basically formed;
2) The era urgently needs a product manager talent pool with a technical background, but also familiar with market applications, and capable of balancing trade-offs;
3) The prosperity and leadership of the AI industry are prerequisites for breakthroughs and innovations in AI chips.

 Capacity is no longer an issue; the next step is the ecosystem.
Capacity is no longer an issue; the next step is the ecosystem.
From the recent signals actively sent by Huawei, and the industry information obtained by the author as a long-time practitioner, Huawei’s capacity constraints have basically been alleviated.
The three pillars of data centers are computing, communication (network interconnection), and storage, which are essential premises for analyzing computing power systems. In AI computing power systems, factors affecting computing performance can also be divided into three parts: design computing power value, high-speed interconnection between computing (computing power) cores, and storage bandwidth.
In “SoftBank Invests $2 Billion, Intel Becomes the Biggest Variable in Global High-End Manufacturing,” the author previously mentioned that the size of computing power is closely related to the process technology, and this high-end process technology is primarily reflected in the high-end capacity of fabs and advanced packaging.
Companies providing Huawei with CoWoS-like packaging have already seen surplus capacity this year and are releasing it externally, indicating that at the 7nm node, Huawei’s demand has basically been met.
Now, let’s look at high-speed interconnection.
During WAIC, ultra-low latency was a highlight of AI infrastructure. Among them, Huawei’s CloudMatrix384 became a standout, characterized by its point-to-point, fully interconnected, ultra-high bandwidth network, connecting all NPUs and CPUs through the UB protocol.
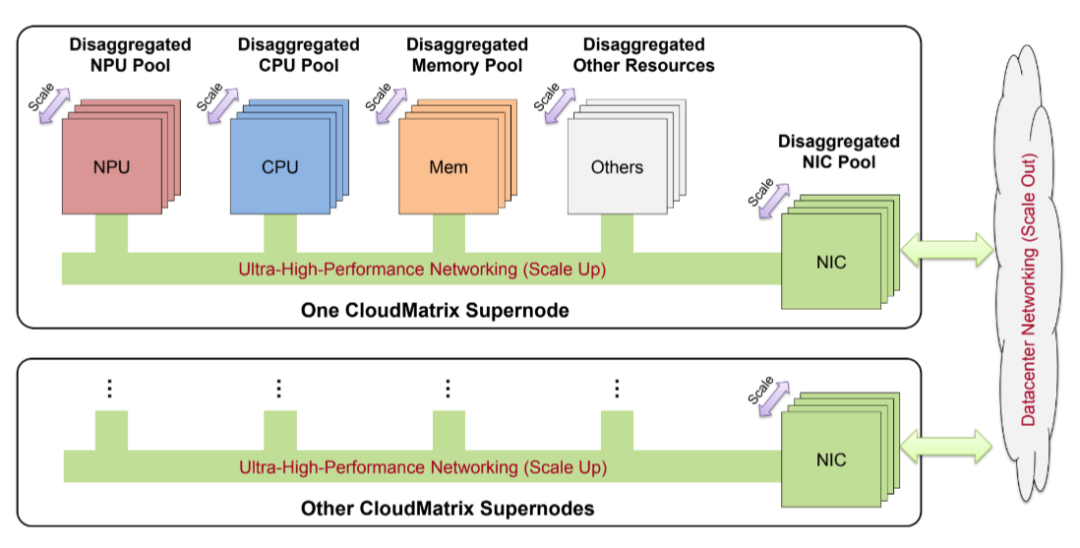
CloudMatrix384 achieves complete point-to-point decoupling and pooling of CPU, NPU, memory, NICs, and other resources through Ultra-High-Performance Networking. Its point-to-point hardware architecture includes an ultra-high bandwidth unified bus (UB) for intra-node expansion, RDMA for inter-node communication, and a virtual private cloud (VPC) for integration with data center networks. This further proves that communication technology is indeed Huawei’s core advantage.
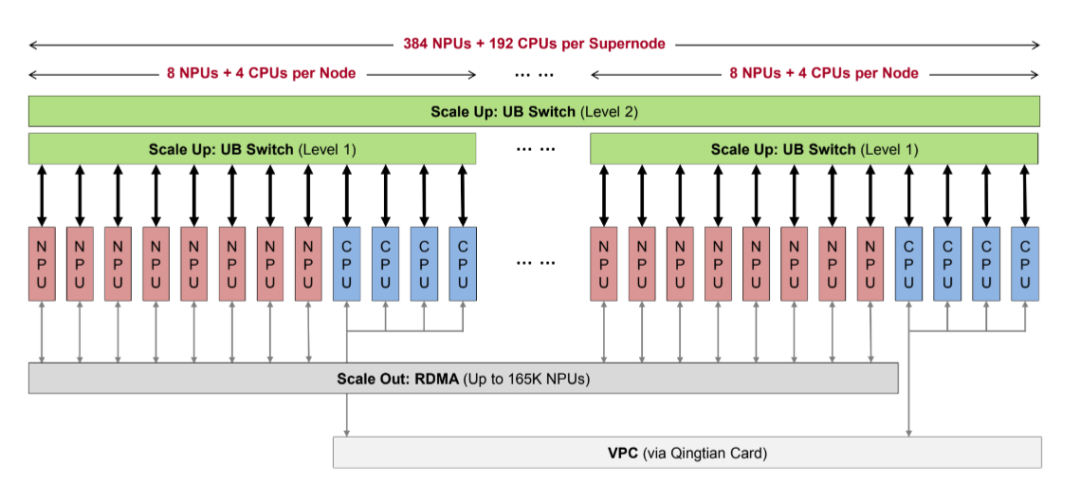
Now, let’s look at memory bandwidth.
Huawei has a deep accumulation in the communication field, and it can be said that high-speed interconnection technology is Huawei’s “old business.”
At this conference, Huawei released the 950, 960, and 970 series products, among which the most eye-catching is the 950 series, which launched two versions. From an application perspective, this marks the decoupling of PD separation at the hardware level, but the results show that memory bandwidth has also kept pace.
Significant breakthroughs have been made in computing, high-speed interconnection, and storage bandwidth hardware, and with capacity issues resolved, Huawei’s next fortress to conquer is the product ecosystem.
In 2022, when the industry began to recognize the significance of the CUDA ecosystem to NVIDIA, building an ecosystem seemed to become a common topic.
The essence of an ecosystem is business.
Intel built the X86 ecosystem, NVIDIA built the CUDA ecosystem, and even Apple, Xiaomi, and Tencent have their own ecosystems. The commonality is that every enterprise, institution, and developer within this ecosystem can find their ecological niche, commercialize, and profit from it.
We cannot expect that when a company raises the banner of the ecosystem, many companies will invest resources without seeking returns. No profit, no early risers, is the norm in the business world.
Having business (potential) is the foundation for establishing an ecosystem.
Therefore, traditional Huawei may face (and is undergoing) a transformation from closed to open, from keeping the water for oneself to sharing benefits. The path taken by Intel and NVIDIA as leaders must also be traversed by Huawei.
Huawei is not alone on this road, as there is also Haiguang.
Geopolitical risks have given rise to opportunities for self-control. As a successful example of technology localization, Haiguang, with the advantages of the X86 architecture, has been unstoppable in the domestic market and the Xinchuang field. With the accumulation of capital becoming increasingly abundant, its technical strength and product involvement are also growing day by day. In addition to CPUs, AI computing power chips, RAID controllers, and high-speed network chips are also maturing, and Haiguang is gradually making inroads into important chips in data centers.
In late May 2025, Haiguang announced it would merge with Shuguang. Earlier, these two brother companies had already begun to collaborate at the ecosystem level, repositioning their respective enterprises and achieving cooperation with domestic server manufacturers and other industry chain companies through market-sharing measures to build a system-level ecosystem.
It can be said that the pattern of “Huawei-Haiguang-Others” has basically formed.
Based on this observation, further deductions can be made:
-
Huawei will soon make a choice between IDM and Fabless models. Of course, regardless of the choice, it should still maintain strong control over capacity;
-
The next step for the merged Haiguang is to invest in high-end capacity, which in today’s China likely means that the fab will probably be SMIC or Huahong. From a commercial operational perspective, Huahong is more likely. As for OSAT, Tongfu Microelectronics already has intricate ties with Haiguang.
 The Era of Product Managers in China’s Chip Industry Has Arrived
The Era of Product Managers in China’s Chip Industry Has Arrived
As mentioned above, the reason the 950 series released this time has attracted attention is due to its two different models, PR and DT, which represent the long-explored “P/D separation” in the industry.
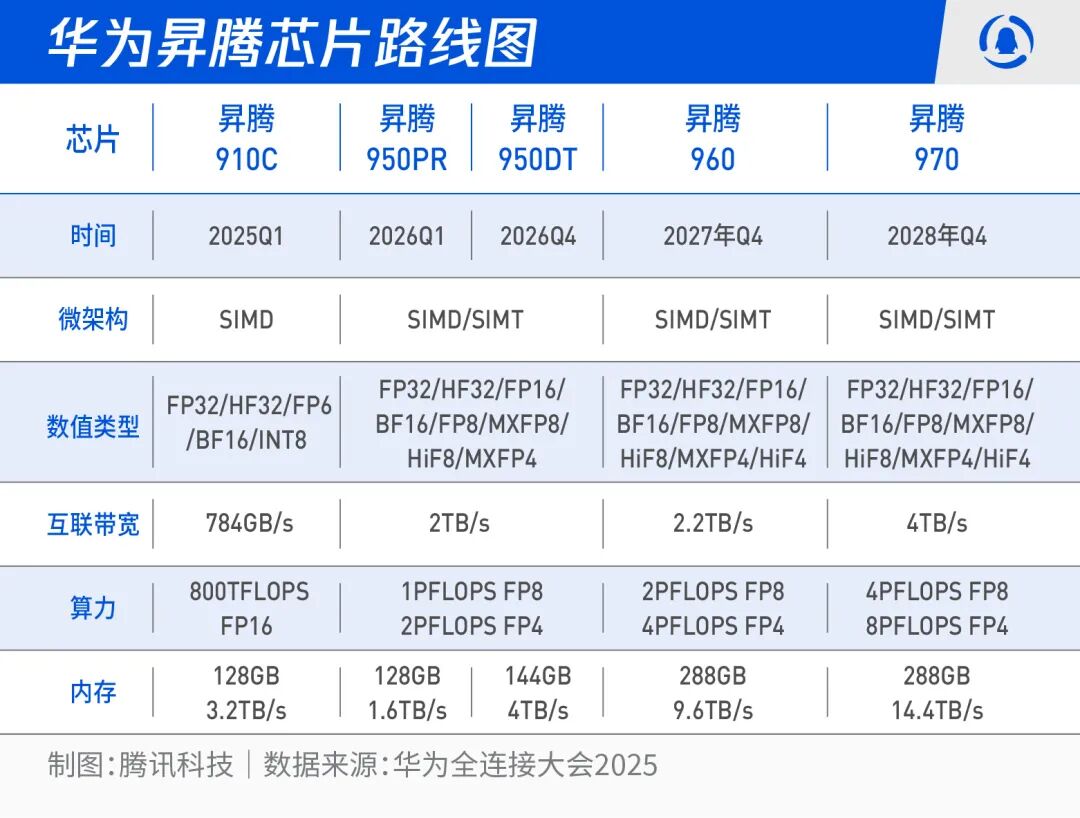
This is similar to the decoding game when DeepSeek was released.
To clarify this concept, we need to look at the evolution of large models and the practical challenges facing China’s AI computing power.
The parameter count of large models starts from the billion level, with tens of billions and hundreds of billions being the norm, up to trillions in scale. These parameters require a very large storage space, and since high-speed access to these memories is needed during computation, extremely high bandwidth is required. This has led to the emergence of HBM, a new type of memory that offers both large capacity and high bandwidth.
When performing computations, the size of computing power also determines the efficiency of the computation, so the design goal of an AI chip will also aim to maximize computing power.
However, very few product managers deeply consider the optimal ratio between computing power and storage bandwidth in their designs. After all, aside from the AI chips customized for large platforms by NVIDIA and Broadcom, being usable is already a remarkable existence.
However, a practical issue is that HBM is extremely expensive, with the cost per GB of HBM being nearly ten times that of DDR, or even higher. For Chinese AI chip companies, not only is there significant cost pressure, but obtaining sufficient capacity and stable supply is also a challenge.
An excellent product manager or architect is considered qualified and outstanding because they know how to optimize and make trade-offs. The premise of good optimization and trade-offs is a deep understanding and insight into application scenarios.
In the application scenarios of AI, the highest resource demand is not only during the model training process but also for the well-known large language models and the primary profit source for every internet company—recommendation algorithms.
In large model inference, the following two metrics are commonly used to evaluate performance:
-
TTFT (Time-To-First-Token): the time taken to generate the first token, which is the time from when the user finishes inputting to when the large model replies with the first word. This mainly measures the performance of the Prefill stage, which is a compute-intensive task with high parallelism requirements but relatively lower memory bandwidth requirements;
-
TPOT (Time-Per-Output-Token): the time taken to generate each token, which is the response speed directly felt by the user. This mainly measures the performance of the Decode stage, which has higher requirements for memory capacity and memory bandwidth.
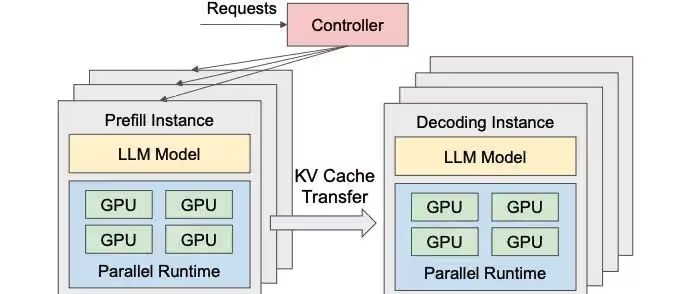
When Prefill and Decode run on the same AI chip, the differences in computational characteristics between the two stages can lead to resource contention between TTFT and TPOT. If the Prefill stage is prioritized to reduce TTFT, the performance of the Decode stage (TPOT) may decline. Conversely, if TPOT is enhanced, the waiting time for Prefill requests will increase, leading to a rise in TTFT.
Huawei’s two models, which adopt different memory capacities and memory bandwidths, should be taking the PD separation approach to break this contradiction.
Being able to run the full version of DeepSeek has almost become a benchmark for evaluating an AI computing system domestically.
However, to accommodate 671 billion parameters, the cost difference alone for using different versions of HBM can reach tens of thousands of dollars. In internet platform companies, the memory capacity required for their recommendation algorithm inference models is also quite large. If optimization, trade-offs, and balance can be achieved between computing power, memory capacity, and memory bandwidth, the return on investment (ROI) will improve.
The era calls for professional AI chip product managers.
In fact, among domestic chip companies, truly qualified product managers with managerial capabilities are very scarce. In the past, when chips were mainly monopolized by foreign companies, a chip company’s Product Marketing or Product Line Manager was a core management position, typically held by a very small number of people at headquarters. With the demand of the Chinese market and the emergence of certain differences with the United States, Chinese mainland individuals have gradually begun to enter this position.
In the Chinese context, “market manager” is often understood as a role responsible for market communication (Marcom) or business development. Today, in domestic AI chip companies, R&D positions still define products.
From the requirements proposed by the full version of DeepSeek to the localization demand for FP8 data precision, and up to this P/D separation, one can subtly see the trend of model applications driving product definitions has already occurred in China. Therefore, it is only natural that a product manager with a technical background, but also familiar with market applications, and capable of balancing trade-offs, will become the leading force in defining and promoting the development of computing power chips and systems in the next stage.
This trend marks the beginning of specialization and refinement in AI chips and AI systems, and is a sign of a new level in product operations.
This trend is a re-illustration of the economic law of “demand determines supply” in the Chinese AI market.
 The AI Industry is a Strategic High Ground, and AI Chips and the AI Industry Can Promote Each Other
The AI Industry is a Strategic High Ground, and AI Chips and the AI Industry Can Promote Each Other
Therefore, we must clearly state: we cannot slow down the development of the AI industry for the sake of developing AI chips.
The prosperity and leadership of the AI industry are prerequisites for breakthroughs and innovations in AI chips.
AGI and controllable nuclear fusion are the two peaks of productivity that human civilization currently faces. In the current geopolitical landscape, the competition among major powers revolves around these two peaks. The competition among enterprises is also striving to ensure that they can always stay at the table and not be left behind by the times.
Just like in war, we cannot rely solely on passion and slogans, but use outdated weapons and equipment to seize strategic high ground. We should utilize all available advantageous resources to ensure victory in the war.
In the communications industry, in the power industry, and in the major infrastructure industry, it is precisely because of our large market scale and prosperous terminal industries that we have gradually forced upstream technological breakthroughs and product innovations, ultimately achieving breakthroughs in all links of the entire industry chain.
In the competition of the AI industry, we must first ensure that we stay at the table in competition, and even become the leading players among them. As these cases illustrate, and as economic laws reveal, as long as we maintain a world-leading level in the AI industry, the trends it leads, the rich scenarios and clear demands it provides, as well as the most important capital, talent, and industry know-how accumulation, will ultimately drive breakthroughs in our AI chips and computing power systems; it is just a matter of time.
However, there is a widely circulated saying online: adults do not make choices; I want them all.
As a super-large-scale economy, China currently possesses the strength to have it all in terms of industry richness, industrial synergy, and capital accumulation. In other words, under market-oriented operations, there is both the foundation and necessity to use world-class computing facilities to reach the top, as well as the resources and willingness needed to support domestic AI computing power.
The purpose of striving is to gain more choices, for individuals and for the country, it is the same.
After years of unremitting efforts and multi-faceted accumulation by compatriots in various fields, we are in an era of industrial transformation and rapid development, which is a blessing for rationalists, an opportunity for those with courage, and a possible path for every ordinary struggler to make a comeback.
*Note: This article is the original work of the author. The content reflects their personal views, and our reposting is solely for sharing and discussion, not representing our endorsement or agreement. If there are any objections, please contact us.