
Intelligent Innovations for the Future


While language models have excelled in the text domain, robots still face the bottleneck of being “invisible and incomprehensible” in the physical world. Spatial Intelligence is thus seen as the next critical leap—it not only endows robots with three-dimensional perception but also requires them to establish a world model that is geometrically, semantically, and physically consistent, thereby truly “understanding” their environment. This article organizes the conceptual context, core technologies, and practical challenges of spatial intelligence based on public research and industry practices for peer reference.
 When robots perceive their environment using LiDAR or depth cameras, they only obtain discrete point cloud data. This leads to the robot being aware that“there is an obstacle ahead”, but unable to distinguish whether“the obstacle is a movable chair or a load-bearing wall”. Meanwhile, the visual differences between simulation and real scenes also cause significant performance degradation during the Sim2Real transfer process, often requiring repeated fine-tuning of strategies to adapt to real environments.
When robots perceive their environment using LiDAR or depth cameras, they only obtain discrete point cloud data. This leads to the robot being aware that“there is an obstacle ahead”, but unable to distinguish whether“the obstacle is a movable chair or a load-bearing wall”. Meanwhile, the visual differences between simulation and real scenes also cause significant performance degradation during the Sim2Real transfer process, often requiring repeated fine-tuning of strategies to adapt to real environments.
According to Professor Fei-Fei Li from Stanford University, spatial intelligence can be defined as“the ability of AI to jointly model and reason about objects, relationships, and dynamic changes in three-dimensional space”. Its goals are divided into three layers from shallow to deep:① Geometric Layer— Achieving high-precision three-dimensional reconstruction;② Semantic Layer— Understanding the categories, attributes, and permissible actions of objects;③ Physical Layer— Predicting the physical compliance of objects in terms of force, mass, and motion constraints.
3D Gaussian Splatter (3DGS) lays a solid “graphical foundation” for spatial intelligence with its explicit scene representation, differentiable rendering process, and real-time updating capabilities. Recently, three cutting-edge studies have empirically validated the immense potential of this technology in the field of robotics.
UC Berkeley · GaussGym:

- Rendering each scene as a set of three-dimensional Gaussian distributions, which can be rapidly rasterized onGPU, preserving realistic textures and lighting
- Automatically extracting camera poses, point clouds, and normals from any video or scan, achieving“video→ trainable3Dworld” conversion
- Embedding the rasterization renderer into a reinforcement learning engine to achieve synchronized updates of physical simulation and visual rendering
Tsinghua University · IGL-Nav:
-
Incremental3D Gaussian mapping, continuously correcting scene representation as the robot moves
- Using target images captured by mobile phones to guide robot navigation, results show that IGL-Nav can effectively guide the robot to the target location, demonstrating its strong generalization ability and transfer performance from simulation to real environments
Zhejiang University SAGE-3D: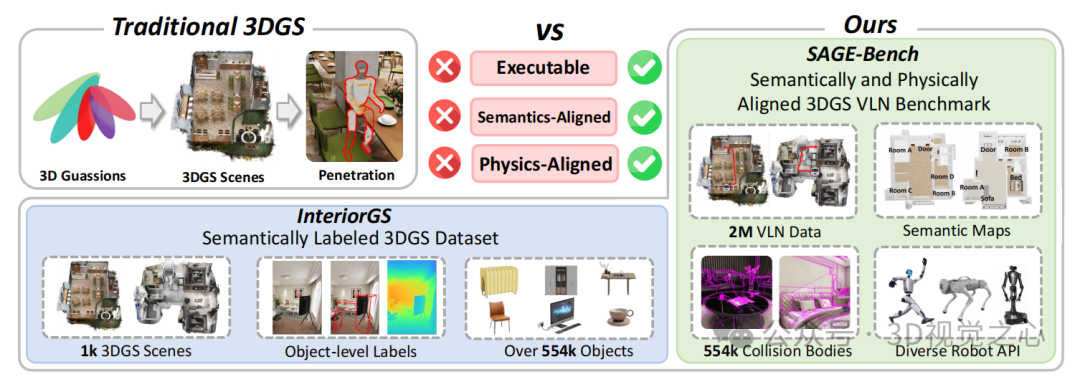
- Upgrading3DGS from “pure perceptual representation” to “executable, semantic-physical aligned” embodied navigation environment base
- Experiments reveal that 3DGS data rendering is fast but convergence is difficult, and it possesses strong generalization capabilities
The above studies indicate that when 3DGS is coupled with semantic and physical labels, the Sim2Real transfer loss of robot strategies significantly decreases, validating the effectiveness of the “world model” approach.
Since 2018, Cloud Vision Technology, a major shareholder of Alrite Robotics, has focused on ultra-high-definition3D visual processing, building a proprietary algorithm pool around multi-sensor fusion, real-time three-dimensional reconstruction, and scene semantic understanding, capable of supporting real-time processing of4K and above video streams.In 2022, Cloud Vision Technology collaborated with Shanghai Jiao Tong University on the ultra-high-definition project of the Central Radio and Television General Station, providing key algorithms and jointly formulating industry technical standards, winning the first prize in Shanghai Science and Technology.
Based on the above accumulation, Alrite Robotics is transitioning spatial intelligence from “laboratory metrics” to “scene-level products”. In the future, through3DGS high-fidelity reconstruction, robots will be able to complete a digital twin of a1000m² environment within 30 minutes, providing continuous rolling training for AI models; combined with semantic and physical annotations, navigation and interaction strategies can be preliminarily validated without the need for depth sensors.
The current development of spatial intelligence still faces multiple challenges. At the algorithmic level, the integration of NeRF and 3DGS, interpretable geometric latent spaces, and real-time updates of dynamic scenes remain research hotspots; at the hardware level, Gaussian dedicated acceleration chips are still in the exploratory stage, needing to balance power consumption, bandwidth, and accuracy; at the data level, the lack of large-scale “geometric-semantic-physical” parallel annotated datasets limits the generalization ability of world models; at the standard level, spatial intelligence interfaces and evaluation systems have yet to be unified, and the industry needs to co-build open protocols.
Spatial intelligence is not a single algorithm but a systematic upgrade from perception, modeling to decision-making. With the cross-iteration of 3DGS, generative simulation, and online learning technologies, robots are expected to achieve “zero-debug” deployment in structured scenes first, gradually moving towards an open world. Cloud Vision Technology and Alrite Robotics will continue to invest, working with academia and industry partners to advance the maturity of spatial intelligence, enabling robots to truly “understand” the world and work safely alongside humans.


Intelligent Innovations for the Future
Please scan the code to follow