Single-GPU Operation for Thousands of Large Models: UC Berkeley’s S-LoRA Method
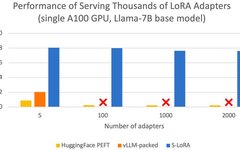
Originally from PaperWeekly Author: Dan Jiang Affiliation: National University of Singapore Generally speaking, the deployment of large language models follows the “pre-training – then fine-tuning” model. However, when fine-tuning a base model for numerous tasks (such as personalized assistants), the training and service costs can become very high. Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning … Read more
