Author Introduction
 Yu Haiying joined Qunar Travel in 2014 as a test development engineer, responsible for testing the Qunar flight service backend. Since 2021, he has been responsible for promoting and implementing chaos engineering at Qunar, focusing on quality gap detection and construction based on chaos engineering.
Yu Haiying joined Qunar Travel in 2014 as a test development engineer, responsible for testing the Qunar flight service backend. Since 2021, he has been responsible for promoting and implementing chaos engineering at Qunar, focusing on quality gap detection and construction based on chaos engineering.
1. Introduction
Qunar’s chaos engineering relies on ChaosBlade as a fault injection tool. After more than two years of practical implementation, a relatively mature system has been established. Key highlights include: non-destructive drills, automated loss control, complete end-to-end detection, and visual report output. This article will elaborate on the successful practices of Qunar Travel’s system strength and weakness dependency drills and attack-defense drills based on the above capabilities in a microservices architecture from the following four aspects:
-
First, conduct a value analysis to determine what kind of companies are suitable for implementing chaos engineering and what benefits chaos engineering can bring;
-
Introduce the architecture of Qunar Travel’s chaos engineering platform;
-
How to implement automated closed-loop drills;
- Attack-defense drills, injecting faults online to train technical problem-solving abilities and validate the fault response system.
2. Value Analysis
2.1 Background
2.1.1 Major Historical Outages
First, let’s take a look at several major outages in history:
- Figure 1 shows a Facebook server outage lasting 7 hours, resulting in a loss of over $60 billion in market value.
- Figure 2 shows a failure of the three major telecommunications providers in South Korea, KT, causing widespread internet outages in South Korea, directly affecting people’s livelihoods.
While we may view these issues with a sense of detachment, as technologists, we should also have a sense of crisis awareness, as such problems could happen to us at any time. So, is there a good solution when such issues arise? This article aims to address these problems.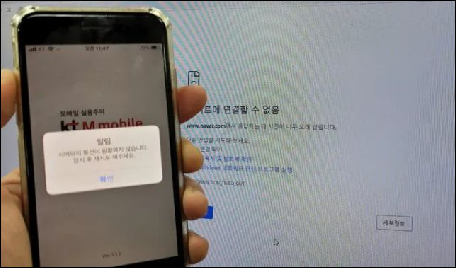 (Figure 1)
(Figure 1)
(Figure 2)2.1.2 Complex ClustersHere are some data from Qunar Travel: there are over 3,000 active applications running online, more than 18,000 Dubbo interfaces, over 3,500 registered domain names on the gateway, and over 13,000 QMQ instances. With a technology stack comprising five languages, it is challenging to ensure complete reliability in a large-scale system ecosystem; any issue in one system could affect the final outcome.2.1.3 Complex InfrastructureIn addition to complex clusters, there is another situation where the scale and complexity of the existing infrastructure layer are increasing, making it difficult to achieve 100% stability. When problems occur, how can we ensure that user-facing services continue to operate effectively? This requires strong technical support.2.1.4 Common Types of FailuresWe categorize failures based on common causes as follows:
1. Data center issues: power outages, network disconnections, network latency
2. Middleware issues: ZK cluster failures, MQ failures, database failures, cache failures
3. Machine issues: high load, full CPU, full disk, full IO
4. Application issues: full GC, service downtime, log slowdowns, full thread pools
5. Dependency issues: downstream Dubbo/HTTP interface delays, exceptions thrown
Based on this series of backgrounds, chaos engineering was born. Next, let’s look at the concept of chaos engineering.2.2 Concept of Chaos EngineeringChaos engineering is a discipline for conducting experiments on distributed systems. It proactively simulates potential issues to observe the system’s response, allowing for preemptive adjustments and the establishment of emergency plans.2.3 Goals of Chaos EngineeringChaos engineering has two main goals: first, to build confidence in our ability to withstand unpredictable issues in production environments through chaos engineering, ensuring that the system is relatively reliable, not relying on chance; second, to transform previously probabilistic issues into deterministic ones, allowing us to understand the reliability of the system based on the extent of chaos engineering implemented.2.4 Benefits of Chaos EngineeringThe benefits of chaos engineering can be viewed from three perspectives:First, from a human perspective, users can enjoy a more stable experience. For example, if the system goes down, users may struggle to purchase or refund tickets, impacting their travel plans and the company’s image. For developers and testers, it allows for early detection and resolution of potential issues, improving emergency response efficiency;Second, from a process perspective, it enhances the fault handling system, shifting from passive to proactive detection of faults and validating the effectiveness of alerts;Third, from a system perspective, it improves system resilience, maximizing reliability.From this perspective, implementing chaos engineering is essential. Qunar Travel began implementing its chaos engineering platform in 2019, progressing through phased implementations. Below, we will specifically introduce the chaos engineering platform at Qunar Travel.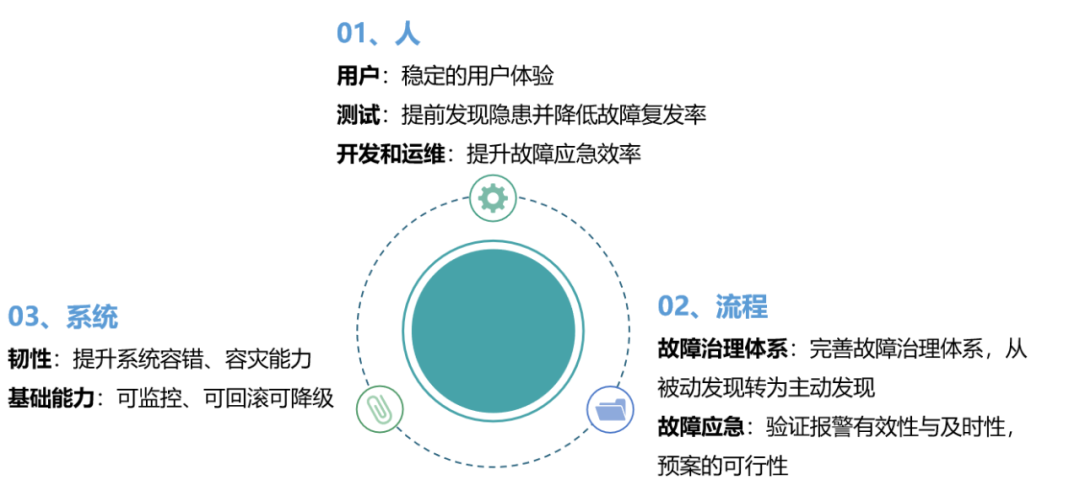 3. Chaos Engineering PlatformFirst, let’s look at our company’s application architecture. From bottom to top, there are the data center layer, middleware, server layer, application, and service dependency layer. There are clear relationships between the layers; the lower you go, the lower the probability of issues, but the greater the impact; the higher you go, the higher the probability of issues, but the individual impact is relatively smaller. This means that when implementing chaos engineering, there is a choice to make: which types do you want to implement first? Our approach was to start from the bottom up. Now, let’s look at the specific implementation path.
3. Chaos Engineering PlatformFirst, let’s look at our company’s application architecture. From bottom to top, there are the data center layer, middleware, server layer, application, and service dependency layer. There are clear relationships between the layers; the lower you go, the lower the probability of issues, but the greater the impact; the higher you go, the higher the probability of issues, but the individual impact is relatively smaller. This means that when implementing chaos engineering, there is a choice to make: which types do you want to implement first? Our approach was to start from the bottom up. Now, let’s look at the specific implementation path. 1. Shutdown Drills: Data Center, Middleware, Physical Machines, Virtual MachinesFirst, we conducted shutdown drills, which involve shutting down machines or data centers. This encompasses various aspects. For example, in the scenario of shutting down data center A, without prior chaos engineering drills, we cannot guarantee that shutting down data center A will not impact online services. Many developers do not consciously consider system availability when designing applications. For instance, if an application is deployed with two instances in two data centers or even in one data center, if that data center fails, there are two scenarios: the first is that both instances are deployed in the same data center, meaning both will go down, and the service provided by this capability will be unavailable; the second scenario is that two instances are deployed in two data centers, and if one data center goes down, half of the instances will be lost. Without proper capacity planning and assessment, the incoming traffic could overwhelm the remaining instances. Therefore, we prioritize shutdown drills for various reasons.2. Application Drills: Service Dependency FailuresThe second phase involves conducting strong and weak dependency drills for applications. We often face situations online where, for example, service A calls downstream service B, and unreasonable timeout settings lead to issues. When setting timeout values, we try to ensure that requests can return, leaving a buffer at the longest time threshold. When a large number of response times exceed the threshold, the system may become unresponsive, as machine resources are tied up waiting for downstream responses, preventing new requests from being serviced. If not handled properly, this could lead to issues with other services that may not be affected, but you could be overwhelmed.3. Attack-Defense Drills: Normalized Attack-Defense Chaos CultureThe third phase involves attack-defense drills, which enhance everyone’s awareness of faults and their ability to handle them. Below, we will introduce the capabilities and key points of each drill.3.1 Shutdown Drills
1. Shutdown Drills: Data Center, Middleware, Physical Machines, Virtual MachinesFirst, we conducted shutdown drills, which involve shutting down machines or data centers. This encompasses various aspects. For example, in the scenario of shutting down data center A, without prior chaos engineering drills, we cannot guarantee that shutting down data center A will not impact online services. Many developers do not consciously consider system availability when designing applications. For instance, if an application is deployed with two instances in two data centers or even in one data center, if that data center fails, there are two scenarios: the first is that both instances are deployed in the same data center, meaning both will go down, and the service provided by this capability will be unavailable; the second scenario is that two instances are deployed in two data centers, and if one data center goes down, half of the instances will be lost. Without proper capacity planning and assessment, the incoming traffic could overwhelm the remaining instances. Therefore, we prioritize shutdown drills for various reasons.2. Application Drills: Service Dependency FailuresThe second phase involves conducting strong and weak dependency drills for applications. We often face situations online where, for example, service A calls downstream service B, and unreasonable timeout settings lead to issues. When setting timeout values, we try to ensure that requests can return, leaving a buffer at the longest time threshold. When a large number of response times exceed the threshold, the system may become unresponsive, as machine resources are tied up waiting for downstream responses, preventing new requests from being serviced. If not handled properly, this could lead to issues with other services that may not be affected, but you could be overwhelmed.3. Attack-Defense Drills: Normalized Attack-Defense Chaos CultureThe third phase involves attack-defense drills, which enhance everyone’s awareness of faults and their ability to handle them. Below, we will introduce the capabilities and key points of each drill.3.1 Shutdown Drills
3.1.1 Objectives
Shut down all service nodes of a specific business line in the same data center, with a drill scale exceeding 1,000 machines at a time.
3.1.2 Key Points
-
Have a comprehensive application profiling platform that aggregates application and data center information for easy querying and application transformation;
-
Notification mechanism to promptly inform of progress and issues;
-
Real shutdown;
-
Integrate alerts; core metrics must automatically trigger circuit breakers if issues arise;
- After rebooting, services should automatically restart.
3.1.3 Process
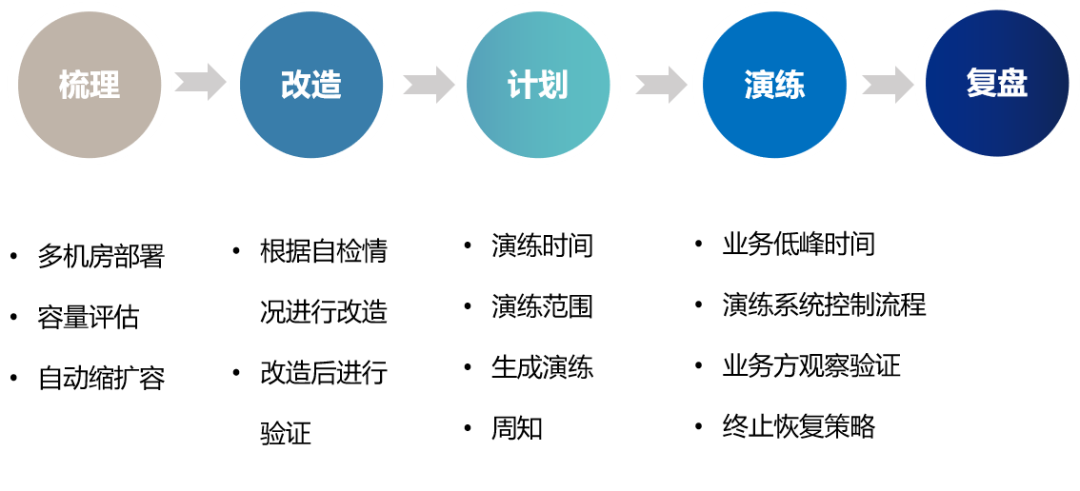
3.1.4 Effects
- Data center drills: 49 times, over 4,000 machines, over 500 applications, discovering more than 10 issues per drill.
- Shutdown drills: 71 times, over 3,000 machines, over 250 applications.
3.2 Application Strong-Weak Dependency Drills
3.2.1 Technical Selection
Application-level drills involve technical selection issues, as they require a wide variety of scenarios, such as full GC, slow log writing, dependency timeouts, or throwing specific exceptions, necessitating robust technical support. At the time, three types were well-maintained and widely used: the first is an official tool that supports virtual machines, with a rich set of scenarios but is not open-source; the second is ChaosBlade, an Alibaba-developed drill tool that supports both containers and KVM, with a relatively rich set of scenarios and is open-source; the third is ChaosMesh, also open-source but only supports K8s mode. After comprehensive consideration, we ultimately chose ChaosBlade.
| Component | Supported Platforms | Supported Scenarios | Open Source | Overall Quality | Invasive | Features |
|---|---|---|---|---|---|---|
| ChAP | VM | Rich | No | Good | High | Experimental reference comparison |
| ChaosBlade | VM/K8S | Rich | Yes | Poor (only had agent at the time) | Low | Simple to use, good scalability, active community |
| Chaos Mesh | K8s | Rich | Yes | Good | No | Cloud-native, active community |
ChaosBlade supports multi-layer fault drills, including basic resource layer and application service layer. It also supports K8s and has a rich set of scenarios covering various needs, although some scenarios are still missing. The main missing scenarios include:
-
HTTP timeouts
-
Full GC
-
Log congestion
-
Call point differentiation
- Link matching
For these unsupported scenarios, we supported these forms during implementation and submitted these changes to the community, participating in open-source co-construction.
3.2.2 Objectives
Weak dependencies should fail without affecting the main process.
3.2.3 Key Points
1. Dependency Relationship CollectionThe main sources for collecting dependency relationships are twofold: one is the application’s access.log; the other is the service registration information on ZK. We aggregate this information into an analysis and aggregation service that updates data from the past seven days daily, storing the aggregated dependency relationships in a database. Strong and weak dependency information needs to be marked by users, and the drill platform provides marking and querying services for dependency relationships.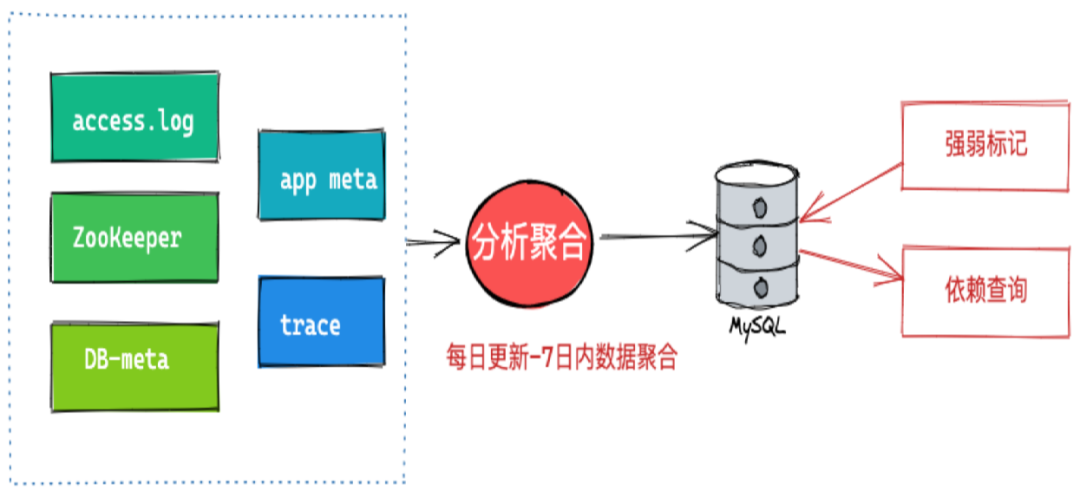 2. Fault Injection OrchestrationA drill typically requires injecting multiple faults, necessitating a certain orchestration strategy. There are three main orchestration strategies:
2. Fault Injection OrchestrationA drill typically requires injecting multiple faults, necessitating a certain orchestration strategy. There are three main orchestration strategies:
-
Parallel: Inject all faults into the service at once. The advantage is speed; the downside is that if issues arise, it is difficult to troubleshoot, as multiple faults may interfere with each other.
-
Serial: Only one fault will occur on each service at a time, making it easier to troubleshoot if issues arise.
- Manual Control: Allows for flexible selection based on needs.
3.2.4 Process
1. Overall ProcessThe overall process of strong-weak dependency drills is divided into four stages:
First stage: Collect dependency relationships.
Second stage: Users manually mark strong-weak dependency relationships on the drill platform.
Third stage: Conduct real drills.
Fourth stage: Post-drill issue resolution, followed by re-marking and drilling to form a closed loop. 2. Detailed Process
2. Detailed Process
Through this process, we ensure that drills proceed smoothly and form a closed loop.
3.2.5 Effects
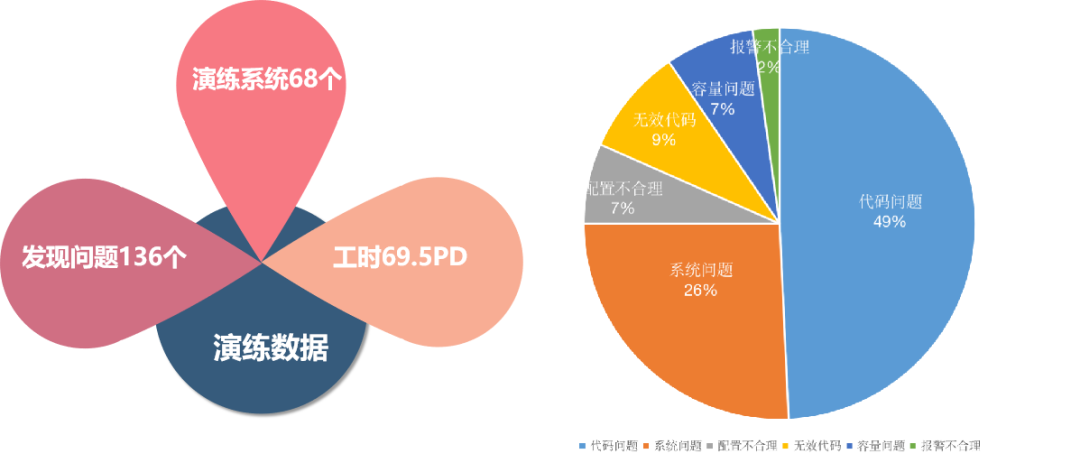
68 drill systems were conducted, with 69.5 PD of work hours, discovering 136 issues.
Through the drills, we discovered numerous system issues. After building this capability, we aim to expand its effectiveness and achieve greater benefits. How can we broaden the impact? The challenge is that manually sorting and marking drills is time-consuming, taking about 1 PD per application. Therefore, we are considering automated execution solutions, which will be detailed in the next section on automated closed-loop drills.3.3 Automated Closed-Loop Drills3.3.1 ObjectivesTo keep the drills fresh and avoid a mechanical approach to reliability assurance, minimizing labor costs while maximizing coverage.3.3.2 Challenges1. Comprehensive Application MetadataFirst, let’s look at application metadata collection. To conduct automated drills, we need to know all application dependency information beforehand. Only by understanding all information can we pre-arrange drill scenarios. We have a comprehensive application metadata analysis platform that analyzes all underlying resources, including HTTP, Dubbo, DB, and various interfaces exposed by the application, including interface and data types, as well as QTrace and topological relationships. With this information aggregated, we can analyze the details of dependencies, allowing us to automatically create drill scenarios for fault injection.

2. Automated Execution Traffic and AssertionsAfter fault injection, how do we obtain traffic? During manual drills, we directly used real user traffic online. Using real online traffic can make it difficult to control the impact range and may affect users, so we generally conduct drills during low business peaks, late at night. For automated drills, if we still use online traffic, the risks would be significant. At this point, we need other traffic to help trigger these processes and ensure results. Fortunately, we have a comprehensive interface automation platform and load testing platform that can execute traffic to the target machines and obtain automated assertion results. The following diagram illustrates the detailed process of automated closed-loop drills. First, the chaos platform obtains dependency information through the application information platform to arrange fault scenarios. Next, through the load testing and automation platform, traffic is executed to the target machines, while the chaos control platform injects faults into the drill environment. The load testing platform initiates requests from the application’s entry point, compares the responses from the baseline environment and the test environment using the diff platform, and returns the comparison results to the chaos control platform, which makes the final strong-weak dependency result judgment and produces a visual drill report. After introducing the process, let’s look at several key points in the implementation of automated closed-loop drills.
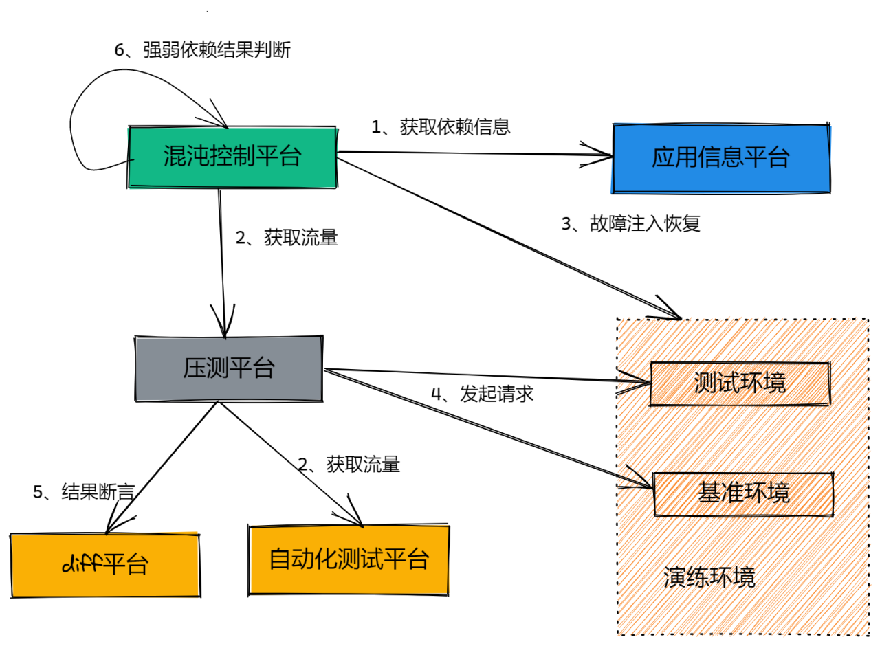
3.3.3 Key Points1. Case Selection Strategy to Ensure Dependency Hit RateFirst, let’s explain the concept of dependency hit rate. During fault injection, traffic hitting the current dependency counts as a hit. The following diagram shows the topology of a specific entry dependency. Our drill scope must cover every interface in the entire link. To ensure a hit rate, the case selection logic is crucial. We aim for a hit rate of over 90% after filtering cases, ensuring the drill is effective. There are two case selection strategies: the first is to randomly select several cases from the entry application, which is a straightforward approach but may struggle with coverage. For example, if a user buys a ticket on our platform, they can choose a one-way trip from Beijing to Shanghai or a round trip. The pricing for one-way and round trips is provided by different systems on the server side. If our random selection only includes one-way requests, we will only hit the one-way link, and all dependencies on the round trip link will be missed. The second strategy is precise matching, where we accurately find the trace of system D calling the interface F provided by system E, associating it with the entry point to initiate requests, ensuring that dependencies are covered.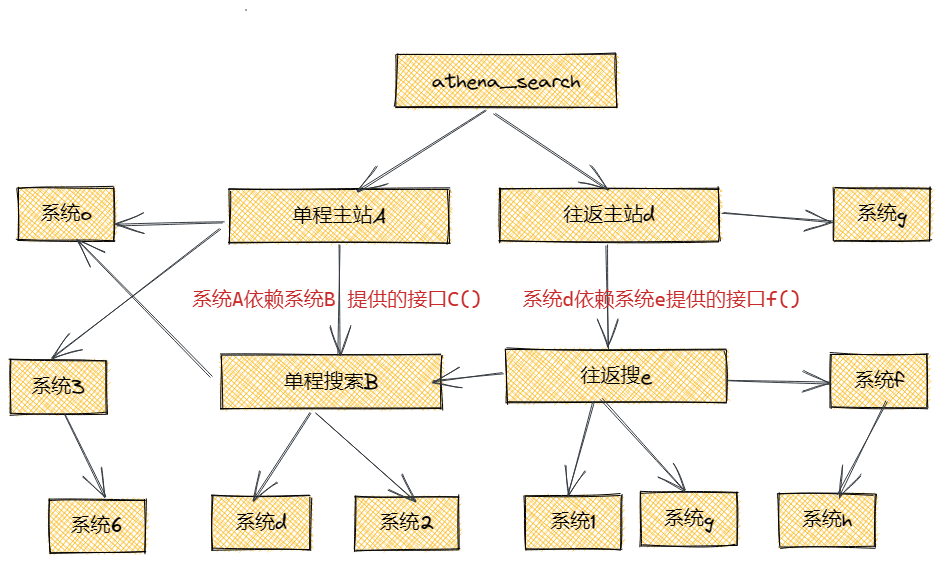 2. Circuit Breaker Recovery StrategyCircuit breaking is primarily achieved through monitoring and alerts. There are two logics involved: the first is the storage logic for marking metrics. Before the drill, we manually mark the core panels of the business line and the core monitoring of applications, storing these core metrics as circuit breaker indicators. The second is the anomaly matching logic during the drill. We check the circuit breaker indicators for alerts during the drill; if any alerts occur, the drill is terminated, while non-circuit breaker indicators are recorded and communicated on the drill interface.
2. Circuit Breaker Recovery StrategyCircuit breaking is primarily achieved through monitoring and alerts. There are two logics involved: the first is the storage logic for marking metrics. Before the drill, we manually mark the core panels of the business line and the core monitoring of applications, storing these core metrics as circuit breaker indicators. The second is the anomaly matching logic during the drill. We check the circuit breaker indicators for alerts during the drill; if any alerts occur, the drill is terminated, while non-circuit breaker indicators are recorded and communicated on the drill interface.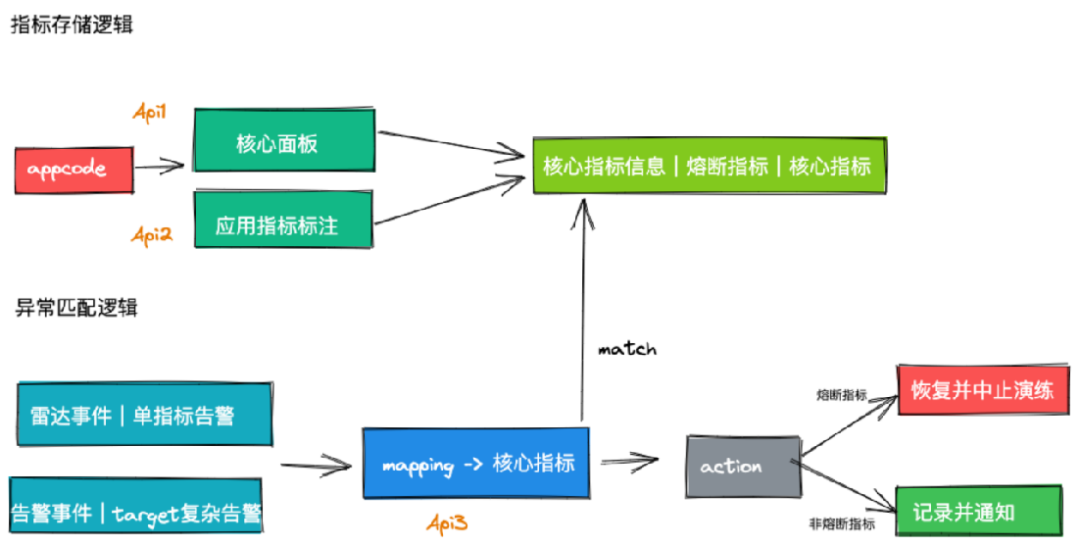 3.3.4 EffectsWe have completed automated closed-loop drills for 10 entry points and 3,820 dependencies.
3.3.4 EffectsWe have completed automated closed-loop drills for 10 entry points and 3,820 dependencies.
3.4 Attack-Defense Drills
3.4.1 Background
The previously introduced shutdown drills, strong-weak dependency drills, and automated closed-loop drills aim to proactively identify system issues and reduce the likelihood of faults. However, we cannot guarantee that faults will not occur online 100% of the time. When faults do occur, are there methods to help us quickly locate the cause and restore functionality? Attack-defense drills are designed to address this issue.
3.4.2 Objectives
To enhance the fault handling capabilities of technical staff and improve the fault emergency response system.
3.4.3 Plan
The attacking party injects attack points, and the defending party identifies anomalies and reports them to the attacking party. The attacking party confirms whether the attack point is correct; if so, they score points.The system architecture for attack-defense drills essentially reuses the automated closed-loop drill setup, using marked traffic from load testing to inject faults and recover in the online environment.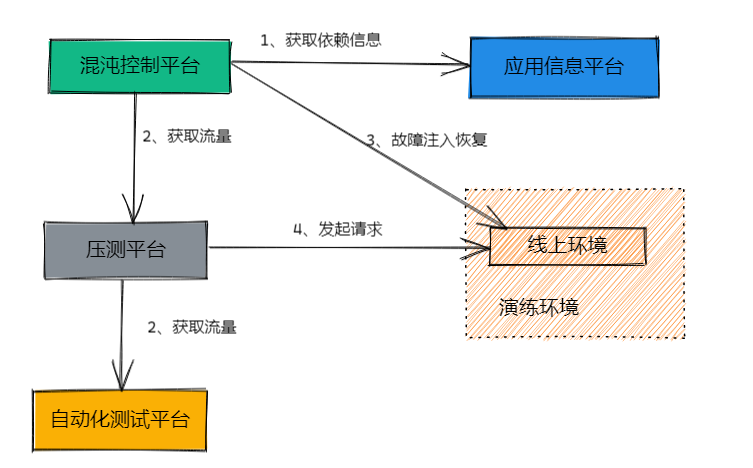 3.4.4 Process1. Attack point orchestration: Select historical high-frequency faults for scenario design.2. Attack point reporting: The defending party locates and reports to the attacking party, who confirms the accuracy for scoring.3. Attack termination: The defending party successfully locates the issue or times out, automatically terminating the drill.4. Scoring: Points are awarded based on the time taken to locate the issue and the difficulty of the fault, with rankings published.5. Review: Issues discovered during the process are resolved.
3.4.4 Process1. Attack point orchestration: Select historical high-frequency faults for scenario design.2. Attack point reporting: The defending party locates and reports to the attacking party, who confirms the accuracy for scoring.3. Attack termination: The defending party successfully locates the issue or times out, automatically terminating the drill.4. Scoring: Points are awarded based on the time taken to locate the issue and the difficulty of the fault, with rankings published.5. Review: Issues discovered during the process are resolved.
3.4.5 Future Plans
We plan to expand the scope of attack-defense drills, normalizing them to cultivate risk awareness among staff, while also conducting large-scale attack-defense drills at the business line or company level, establishing fixed attack-defense days and fostering a culture of chaos.

