
Changqing Cloud
Overview of Domestic AI Chips:
GPU/NPU Manufacturers Are All Here
GPU
NPU
Introduction
The explosive growth of artificial intelligence computing power is driving the global semiconductor industry landscape to be reshaped. According to IDC’s forecast, by 2025, the scale of China’s AI chip market will exceed 200 billion yuan, with training chips accounting for over 60%. In this arms race for computing power, GPUs (Graphics Processing Units) and NPU (Neural Processing Units) serve as core computing power carriers, and their technological breakthroughs are directly related to the independence process of China’s AI industry.
From the perspective of computing architecture, GPUs adopt a SIMT (Single Instruction Multiple Threads) architecture, achieving parallel computing through thousands of stream processors, with typical representatives like NVIDIA’s Ampere architecture streaming multiprocessors (SM); NPUs, on the other hand, utilize pulsed arrays or data flow architectures, optimized for matrix operations, such as Huawei’s Da Vinci architecture 3D Cube computing units. According to MLPerf benchmark tests, NPUs can achieve 2-3 times the energy efficiency of GPUs in ResNet-50 inference tasks, although they are slightly less flexible in programming.
In the context of increasingly fierce global chip industry competition, domestic chip manufacturers bear the responsibility of breaking through technical bottlenecks and achieving self-control, rapidly rising and demonstrating unique advantages and potential in various technical fields and application scenarios. Let us delve into some representative domestic chip manufacturers and their core technological achievements.
1. Haiguang (DCU K100)
Architecture Principle: Designed based on a General-Purpose Graphics Processing Unit (GPGPU) architecture, capable of handling various precision types of floating-point operations.
Hardware Parameters: Manufactured using a 14nm process, integrating 64GB GDDR6 video memory, providing a PCIe 4.0 x16 high-speed data transmission interface.
Computing Performance: FP64 24.5 TFLOPS, FP32 24.5 TFLOPS, FP16 100 TFLOPS, INT8 200 TOPS.
Energy Consumption: Power consumption is 300W.
Software Support: Compatible with mainstream deep learning frameworks such as PyTorch and TensorFlow.
Applicable Fields: Suitable for data centers and high-performance computing fields, commonly used in cloud computing services, scientific research, and industrial simulation scenarios, capable of executing large-scale parallel computing tasks.
2. Huawei Ascend (910B)
Core Technology: Da Vinci 3D Cube architecture, supporting sparse computing and dynamic partitioning.
Hardware Configuration: Utilizes 7nm technology, equipped with 64GB HBM2e, with a bandwidth of up to 1.6TB/s, interface PCIe 5.0 x16.
Computing Specifications: FP32: 94 TFLOPS, FP16: 376 TFLOPS, INT8: approximately 640 TFLOPS.
Power Characteristics: Power consumption is 400W.
Software Ecosystem: Native support for MindSpore, with a CUDA code conversion tool, compatibility exceeding 85%.
Application Scenarios: Widely used in artificial intelligence computing, data centers, intelligent security, autonomous driving, and other fields.
3. Moore Threads (MTT S4000)
Core Technology: Utilizes the third-generation MUSA architecture, equipped with Tensor cores.
Hardware Configuration: Single card with 48GB GDDR6 video memory, 384 bits width, bandwidth 768GB/s, core frequency 1.5GHz, PCIe 5.0 x16 interface, 4 DisplayPort 1.4a display interfaces.
Computing Specifications: FP32: 25 TFLOPS, TF32: 50 TFLOPS, FP16/BF16: 100 TFLOPS, INT8: 200 TOPS.
Power Characteristics: Power consumption is 450W.
Software Ecosystem: Achieves zero-cost migration of CUDA code to MUSA through the MUSIFY tool.
Application Scenarios: Used for large language model training, inference, graphics rendering, video encoding and decoding, supporting digital twins, cloud gaming, and other scenarios.
4. Muxi MXC500
Core Technology: Based on a dynamically configurable GPU architecture, achieving flexible allocation of hardware resources through modular computing units and multi-level cache systems.
Hardware Configuration: Utilizes 7nm process, featuring next-generation high-speed IO interfaces such as PCIe 5.0, CCIX 2.0, CXL 2.0, etc.
Computing Specifications: FP64: 7.5 TFLOPS, FP32: 15 TFLOPS, FP16: 30 TFLOPS, BF16: 30 TFLOPS, INT8: 60 TOPS.
Power Characteristics: No specific power consumption values available.
Software Ecosystem: Equipped with the MXMACA 2.0 computing platform, compatible with CUDA, TensorRT, CUDNN, NCCL, PyTorch, TensorFlow, etc.
Application Scenarios: Used in AI training, big data analysis, cloud computing, cloud gaming, digital twins, and the metaverse.
5. Kunlun Core (R200)
Core Technology: Kunlun Core’s self-developed second-generation XPU architecture, supporting heterogeneous computing units and physical-level isolation of memory units.
Hardware Configuration: R200 is equipped with 32GB GDDR6, interface PCIe 4.0 x16.
Computing Specifications: FP32: 32 TFLOPS, FP16: 128 TFLOPS, INT8: 256 TOPS.
Power Characteristics: Power consumption is 150W.
Software Ecosystem: Deeply optimized for TensorFlow Lite, supporting quantization-aware training.
Application Scenarios: Suitable for cloud computing, big data processing, AI inference, etc., providing stable and efficient computing power for data centers and intelligent applications.
6. Jingjia Micro (JM11)
Core Technology: MUSA graphics rendering architecture.
Hardware Configuration: The JM11 series is equipped with 64GB DDR4, interface PCIe 4.0.
Computing Specifications: FP32: 6 TFLOPS, FP16: 12 TFLOPS.
Power Characteristics: Power consumption is approximately 150W.
Software Ecosystem: Supports OpenGL 4.6/OpenCL 3.0/Vulkan 1.3/DirectX 11 and other API interfaces.
Application Scenarios: Meets cloud desktop, cloud gaming, cloud rendering, cloud computing, and other cloud application scenarios, as well as geographic information systems, multimedia processing, CAD-assisted design, and other high-performance rendering application scenarios.
7. Cambricon (MLU290-M5)
Core Technology: Utilizes MLUv02 extended architecture, supporting MLU-Link multi-chip interconnection technology for high-speed interconnection between multiple chips.
Hardware Configuration: Manufactured using a 7nm process, equipped with 32GB HBM2, memory bandwidth of 1.23TB/s.
Computing Specifications: 64 TOPS (FP32), 256 TOPS (INT16), 512 TOPS (INT8), 1024 TOPS (INT4).
Power Characteristics: Power consumption is 350W.
Software Ecosystem: Supports mainstream deep learning frameworks such as TensorFlow and PyTorch.
Application Scenarios: Widely used in complex AI application scenarios in the fields of internet, finance, transportation, energy, power, and manufacturing.
8. Birun (BR100P)
Core Technology: Self-developed BLink interconnection technology, heterogeneous GPU collaborative training scheme (HGCT).
Hardware Configuration: Manufactured using a 7nm process, equipped with 64GB HBM2e, bandwidth of 1.64TB/s, using OAM packaging.
Computing Specifications:FP32: 128 TFLOPS, TF32+: 256 TFLOPS, BF16: 512 TFLOPS, INT8: 1024 TOPS.
Power Characteristics: Power consumption is 450-550W.
Software Ecosystem: Has the BIRENSUPA software development platform, supporting mainstream deep learning frameworks and self-developed inference acceleration engines.
Application Scenarios: Applicable in smart cities, data centers, big data analysis, autonomous driving, medical health, life sciences, and other fields.
9. Suiyuan (Yunsui T21)
Core Technology: Based on the Suisi 2.0 chip’s GCU-CARA architecture, supporting multi-precision computing.
Hardware Configuration: Yunsui T21 is equipped with 32GB HBM2e, bandwidth of 1.6TB/s, using OAM packaging.
Computing Specifications: FP32 32TFLOPS, FP16 128TFLOPS, INT8 256TOPS.
Power Characteristics: Power consumption is 300W.
Software Ecosystem: Has the TopsRider compiler, which can automatically optimize operators.
Application Scenarios: Compatible with open computing standards, serving AI model training and inference tasks in industries such as internet, finance, and healthcare.
10. Taichu (Yuanqi T110)
Core Technology: Shenwei heterogeneous many-core architecture.
Hardware Configuration: T110 is equipped with 64GB HBM2e, bandwidth of 1.2TB/s.
Computing Specifications: FP32 10 TFLOPS, FP16 240 TFLOPS, INT16 240 TOPS, INT8 480 TOPS.
Power Characteristics: Power consumption is 550W.
Software Ecosystem: Has the SDAA toolkit, integrating over 20 development tools.
Application Scenarios: Widely applicable in artificial intelligence computing, high-performance computing, and other fields.
11. Xim STCP Series
Core Technology: Based on RISC-V instruction set extensions, with self-developed NeuralScale computing core and integrated instruction set.
Hardware Configuration: STCP920 uses a 12nm process, equipped with 16GB LPDDR4X.
Computing Specifications: FP16 has 128 TFLOPS, INT8 is 256 TOPS.
Power Characteristics: Power consumption is 160W.
Software Ecosystem: Has ONNX Runtime acceleration solutions.
Application Scenarios: Applicable in smart governance, internet, operators, finance, and other fields for CV, NLP, search recommendation, and other scenarios.
12. Suan Neng (SC7 HP75)
Core Technology: Utilizes self-developed BM1684X chip architecture.
Hardware Configuration: Equipped with 48GB LPDDR4x, bandwidth of 205GB/s.
Computing Specifications: Supports FP32/BF16/FP16/INT8, performance unspecified.
Power Characteristics: 75W.
Software Ecosystem: Has an open and mature algorithm ecosystem, providing one-stop development support.
Application Scenarios: Frequently applied in AI inference, edge computing, etc., providing computing power support for intelligent security, intelligent transportation, and other scenarios.
13. Tian Shu Zhi Xin (Tian Fei 100)
Core Technology: Based on a general-purpose GPU architecture design, self-developed instruction set supports scalar, vector, and tensor operations.
Hardware Configuration: Tian Fei 100 is equipped with 32GB HBM2, interface PCIe 4.0.
Computing Specifications: FP32 37 TFLOPS, FP16 147 TFLOPS, INT8 295 TOPS.
Power Characteristics: 250W.
Software Ecosystem: Supports mainstream domestic and foreign software and hardware ecosystems, various deep learning frameworks, algorithm models, and acceleration libraries.
Application Scenarios: Suitable for high-performance computing, artificial intelligence training, and other scenarios.
On the competitive stage of chip technology, key parameters are like the strength indicators of athletes, clearly showcasing the performance differences and unique advantages of different domestic chips. Through detailed comparisons of these parameters, we can more intuitively understand the adaptability of each brand’s chips in different application scenarios, providing strong references for industrial development and technology selection. Now, let us delve into the key parameter comparison of domestic chips.
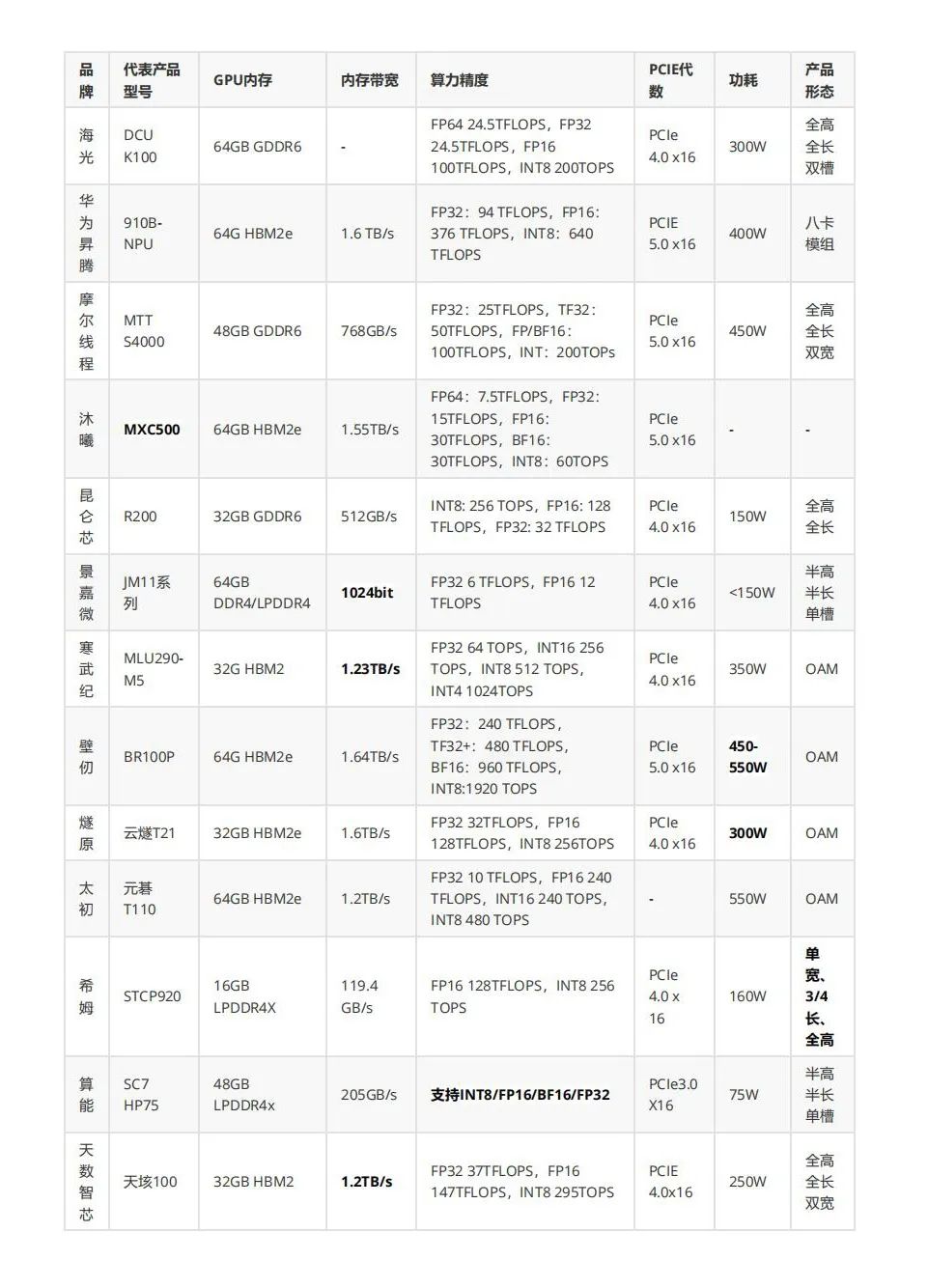 Parameter Explanation1. Computing Precision: FP32 (single precision floating point) is suitable for scientific computing, INT8 (8-bit integer) is commonly used for inference acceleration.2. Memory Bandwidth: Determines data throughput efficiency, directly affecting the speed of large-scale model training.3. Power Consumption: High computing power is often accompanied by high power consumption, requiring a balance between performance and energy efficiency.(Data compiled from manufacturer websites, with missing data sourced from third parties, which may deviate from actual conditions and is for reference only.)
Parameter Explanation1. Computing Precision: FP32 (single precision floating point) is suitable for scientific computing, INT8 (8-bit integer) is commonly used for inference acceleration.2. Memory Bandwidth: Determines data throughput efficiency, directly affecting the speed of large-scale model training.3. Power Consumption: High computing power is often accompanied by high power consumption, requiring a balance between performance and energy efficiency.(Data compiled from manufacturer websites, with missing data sourced from third parties, which may deviate from actual conditions and is for reference only.)
Changqing Cloud AI Hyper-Converged Integrated Machine integrates domestic GPU/NPU technology ecosystems deeply, constructing a full-stack autonomous AI computing power system covering chip architecture, computing frameworks, and operational management, providing safe and efficient computing power support for large models like DeepSeek, achieving a complete technical closed loop from underlying hardware to upper-layer applications.
Double Helix Evolution:
The Ecological Co-Progress of Domestic GPUs and Changqing Cloud
In the wave of breakthroughs in domestic GPU/NPU technology and industrial upgrades, Changqing Cloud has always advanced hand in hand with domestic chip manufacturers. Through architectural-level collaborative innovation and ecological co-construction, both parties continue to break boundaries in computing power efficiency optimization, framework deep adaptation, and industry scenario implementation.This “double helix” evolution of hard technology and industrial applications not only accelerates the maturity of the domestic computing power base but also inscribes the coordinates of independent innovation in China during the intelligent era. In the future, Changqing Cloud will continue to anchor technology, working with domestic GPU ecosystem partners to paint the starry sea of intelligent computing. Written by: Xiao Chiwen Edited by: Zhou Yiqi Chief Editor: Zhang Shi Reviewed by: Zeng Yuanyuan
About Changqing Cloud
Changqing Cloud is committed to becoming the leading brand of the next generation AI hyper-converged cloud platform, providing customers with high-performance, cost-effective cloud computing solutions. The core product KuberCloud integrates general computing power and intelligent computing power, featuring high performance, high security, and high reliability, achieving double the performance at half the construction cost of first-tier foreign products, helping enterprises lower the threshold for cloud usage, facilitating digital transformation, and embracing the AI era.