Click the blue text above👆 to follow us!

The ByteDance Doubao large model team has officially open-sourced the first multilingual SWE dataset – Multi-SWE-bench, which can be used to evaluate and enhance the bug-fixing capabilities of large models.
Building on SWE-bench, Multi-SWE-bench covers seven mainstream programming languages beyond Python for the first time, making it a true benchmark for “full-stack engineering”. The data is sourced from GitHub issues and has been constructed over nearly a year to accurately assess and improve the advanced programming intelligence of large models.
This article will introduce the research background, dataset construction, and future plans of Multi-SWE-bench, hoping to promote the maturity of code generation technology in collaboration with the industry.
From ChatGPT to 4o, o1, o3, Claude-3.5/3.7, and Doubao-1.5-pro, DeepSeek-R1, large models are revolutionizing the coding world at an astonishing speed.
Today, AI is no longer limited to writing functions and checking APIs; allowing AI to automatically solve real issues (bugs) submitted on GitHub has also become one of the benchmarks for measuring model intelligence.
However, problems have also emerged: existing mainstream evaluation datasets, such as SWE-bench, are all Python projects. This leads to some large models scoring high on the Python leaderboard but not being proficient in other languages.
To address the issue of insufficient generalization capability, the ByteDance Doubao large model team has officially open-sourced Multi-SWE-bench.

This dataset is the industry’s first benchmark for large models focused on multilingual code problem-solving, covering programming languages such as Java, TypeScript, C, C++, Go, Rust, and JavaScript.
As a standardized, reproducible, multilingual “automated programming” open-source evaluation benchmark, Multi-SWE-bench aims to advance automated programming technology from merely solving single-language (like Python) and low-complexity tasks to supporting multiple languages and possessing real problem-solving capabilities as a general intelligent agent.
With the rise of reinforcement learning, the team has also open-sourced Multi-SWE-RL, providing a standardized, reusable data infrastructure for RL training in real code environments.
Currently, the Multi-SWE-bench paper, code, and dataset have all been made public.
The team believes that this open-source initiative is just a small step in a thousand-mile journey, and that a single team cannot meet the technological development needs alone. They welcome more researchers to participate in the construction of open-source benchmarks and data infrastructure.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Paper link: https://arxiv.org/abs/2504.02605
Leaderboard link: https://multi-swe-bench.github.io
Code link: https://github.com/multi-swe-bench/multi-swe-bench
Data link: https://huggingface.co/datasets/ByteDance-Seed/Multi-SWE-bench
1. Limitations of Mainstream Code Benchmarks: Single Language Coverage, Limited Complexity Tasks
The code generation task places comprehensive demands on the core capabilities of large language models, such as logical reasoning and contextual understanding. Accordingly, benchmarks like SWE-bench have become important indicators for measuring model intelligence levels in recent years.
SWE-bench is currently the most representative code repair evaluation benchmark, emphasizing real tasks and high difficulty. It is based on GitHub issues, requiring models to automatically locate and fix bugs, incorporating challenges such as cross-file modifications, complex semantic reasoning, and contextual understanding. Compared to traditional code generation tasks (e.g., HumanEval, MBPP, LiveCodeBench), SWE-bench is closer to real development scenarios and is a key measure of the advanced “programming intelligence” of large models.
However, with the rapid development of the industry and the continuous improvement of model capabilities, this benchmark struggles to comprehensively cover the multilingual environments and complex tasks encountered in real development, limiting the further evolution of code intelligence in large models.
Specifically, its limitations mainly manifest in the following two aspects:
(1) Single Language Dimension: Current mainstream evaluations are almost entirely focused on Python, lacking coverage of other languages, making it difficult to assess the model’s cross-language generalization capabilities.
(2) Insufficient Task Difficulty: Existing benchmarks mostly consist of short patches and single-file repairs, failing to cover complex development scenarios such as multi-file, multi-step, and long-context tasks. Additionally, the tasks in SWE-bench are not graded by difficulty, making it challenging to systematically measure model performance across different capability levels.
In this context, the industry urgently needs a “multilingual bug repair evaluation set” that covers mainstream programming languages and features high-quality annotated instances with difficulty grading.
2. Multi-SWE-bench Covers 7 Languages and 1,632 Real Repair Tasks
Multi-SWE-bench aims to fill the gaps in language coverage of existing benchmarks, systematically evaluating large models’ “multilingual generalization capabilities” in complex development environments, with the following main features:
- First-time coverage of 7 mainstream programming languages (including Java, Go, Rust, C, C++, TypeScript, JavaScript), constructing code repair tasks in a multilingual development environment to systematically assess the model’s cross-language adaptability and generalization capabilities;
- Introduction of a task difficulty grading mechanism, categorizing problems into easy (Easy), medium (Medium), and hard (Hard) classes, covering development challenges from single-line modifications to multi-file, multi-step, and multi-semantic dependencies;
- All 1,632 instances are sourced from real open-source repositories and have been screened through unified testing standards and professional developer reviews, ensuring each sample has a clear problem description, correct repair patches, and a reproducible runtime testing environment.
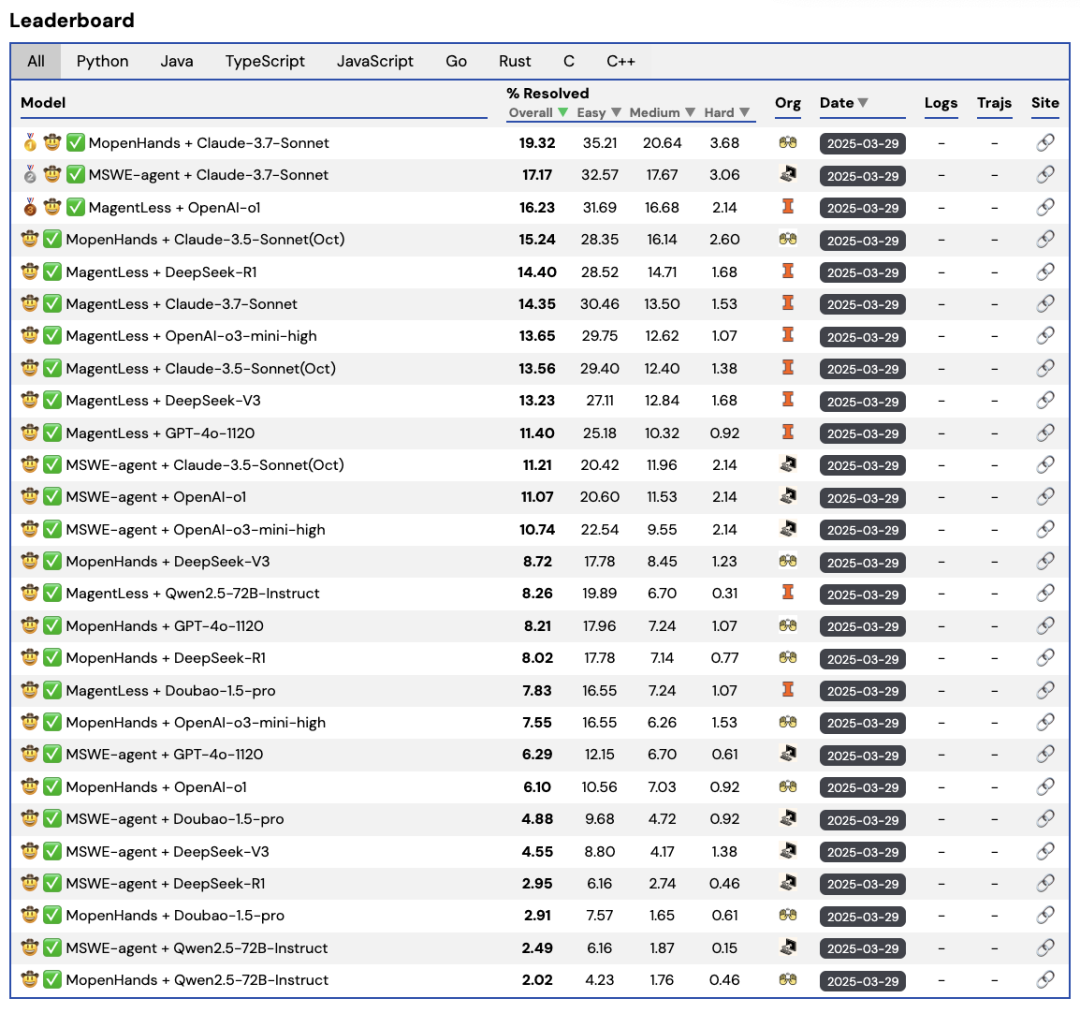 Evaluation scores for different model code capabilities
Evaluation scores for different model code capabilities
The team observed through experiments based on Multi-SWE-bench that although current LLMs perform well in Python repair rates, the average repair rate for other languages is generally below 10%.
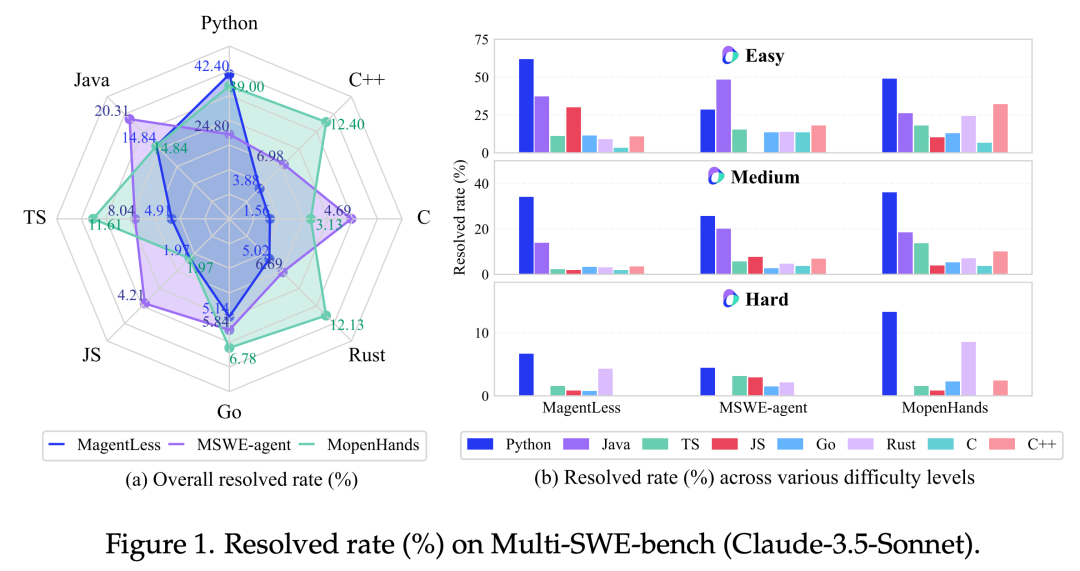 Some mainstream models perform better on Python, but score poorly on other languages. Additionally, as task difficulty increases, the model’s repair rates show a gradual decline.
Some mainstream models perform better on Python, but score poorly on other languages. Additionally, as task difficulty increases, the model’s repair rates show a gradual decline.
This also indicates that multilingual code repair remains a watershed for the intelligence capabilities of large models and is a core direction for advancing AI towards general programming intelligence.
3. Systematic Construction Over Nearly a Year with Strict Manual Verification
During the construction of Multi-SWE-bench, the team designed and executed a systematic data construction process, divided into five stages, covering the entire process from project selection, data collection to data verification, maximizing the authenticity, comprehensiveness, and usability of the data.
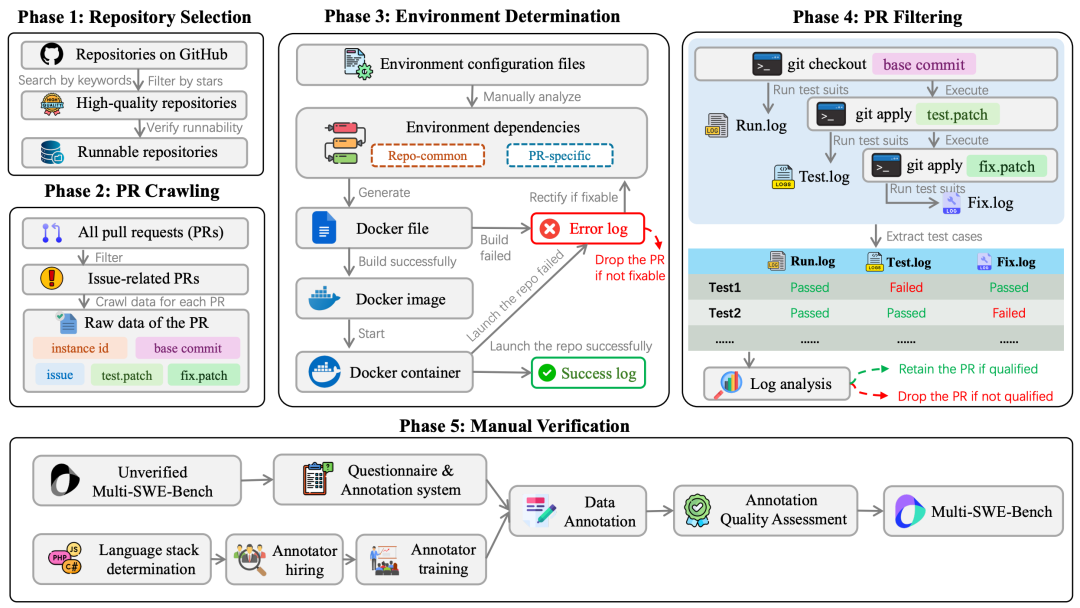 Multi-SWE-bench Construction Process
Multi-SWE-bench Construction Process
Step 1: Open-source Repository Screening
The team screened high-quality project repositories from publicly available GitHub repositories based on multiple dimensions, ensuring coverage of the seven mainstream languages (Java, TypeScript, JavaScript, Go, Rust, C, and C++). Selection criteria include:
- Over 500 GitHub Stars, indicating a certain level of community activity;
- Maintained continuously for at least six months;
- CI/CD support, allowing for automated builds and tests through tools like GitHub Actions;
- Reproducible build processes to ensure subsequent environment setup is unobstructed.
Step 2: Pull Request (PR) Crawling
After the initial screening of repositories, the team collected all PRs from the projects using automated crawlers and applied the following filtering rules:
- PRs must be associated with at least one GitHub issue;
- Must include modifications to test files to ensure the repair behavior is verifiable;
- Must have been merged into the main branch, with code quality and maintainer approval.
Each PR record extracts key information, including: original issue description, repair patch, test patch, commit information, etc.
Step 3: Building Executable Docker Environments
To ensure that each task in the dataset is fully runnable, the team built corresponding Docker containers based on each PR, replicating its runtime environment.
Relying on CI/CD configurations, README, and other metadata, dependencies were extracted and Dockerfiles were automatically generated. For failed builds, the team manually troubleshooted errors and attempted to fix them to ensure the integrity and reproducibility of the environment.
Step 4: PR Filtering and Dataset Creation
Each PR underwent three testing processes in the constructed environment:
- Original state (no patches applied);
- Only test patch applied (test.patch);
- Both test and repair patches applied (test.patch + fix.patch);
The team analyzed the logs from the three-stage tests to identify whether effective repair behavior existed (e.g., FAILED→PASSED) and excluded samples that posed regression risks or exhibited abnormal testing behavior. After this stage, the team retained 2,456 candidate data points.
Step 5: Strict Manual Verification Mechanism
To further enhance data reliability, the team introduced a dual-annotation process. A total of 68 professional annotators participated in the review, all of whom have relevant development experience in the corresponding languages.
Each sample was annotated by two independent annotators and underwent cross-review, with all annotation results subject to random checks by the internal QA team to ensure consistency and accuracy.
Through this stage, we ultimately retained 1,632 high-quality instances and made all annotation questionnaires and scoring data public to ensure data transparency.
Through a systematic data construction process, the team hopes to lay a solid foundation for the evaluation and training of future automated programming agents, driving related research towards scaling and engineering.
4. Multi-SWE-RL Open Source & Community Recruitment
With the rise of new-generation models like GPT-4o, o1, o3, the potential of reinforcement learning methods in automated programming is receiving widespread attention. Based on the judgment that RL will play an important role in advancing code intelligence, the Doubao large model team further developed Multi-SWE-RL, providing a unified, standard data foundation for RL training in code environments. This allows models not only to have a “textbook” for learning but also an “environment” for learning.
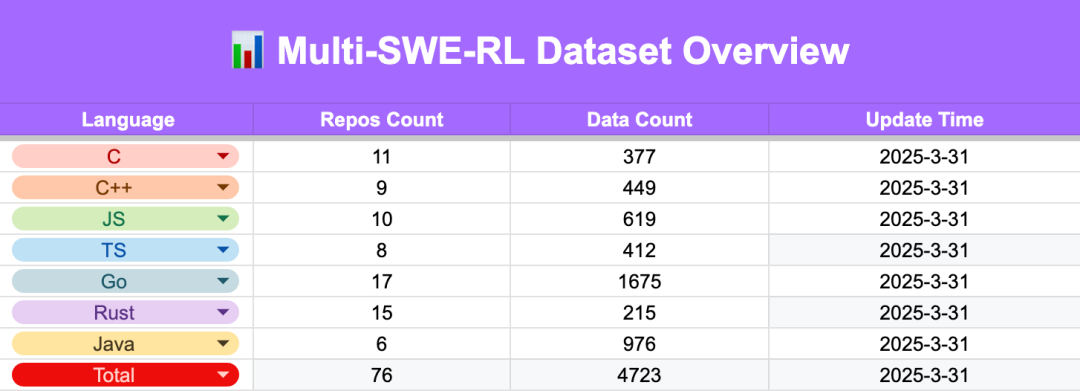
As one of the first contributors, the team has initially contributed 4,723 instances, each equipped with a reproducible Docker environment, supporting one-click startup, automatic evaluation, and quick integration into RL training frameworks. Additionally, the team has fully open-sourced the data construction process and toolchain.
Currently, the team has also launched an open-source community plan, encouraging developers to participate in dataset expansion, RL data contributions, and new method evaluations. The Multi-SWE-RL project provides detailed contribution tutorials, incentive mechanisms, and a real-time updated task board to ensure efficient and transparent community collaboration. All new data and evaluation results will be regularly incorporated into subsequent public versions, with all valid contributors or authors credited.
The Doubao large model team looks forward to collaborating with more developers and researchers to advance the RL for Code ecosystem, laying the foundation for building general software agents.
Dataset link: https://huggingface.co/datasets/ByteDance-Seed/Multi-SWE-RL
5. Final Thoughts
The Doubao large model team hopes that Multi-SWE-bench can serve as a systematic evaluation benchmark for large models in various mainstream programming languages and real code environments, promoting the development of automated programming capabilities towards more practical and engineering-oriented directions.
Compared to previous single-language tasks focused on Python, Multi-SWE-bench is closer to real-world multilingual development scenarios and better reflects the current models’ actual capability boundaries in the direction of “automated software engineering”.
In the future, the team will continue to expand the coverage of the Multi-SWE series – including adding new languages, expanding more software engineering tasks, and encouraging more researchers and developers to participate in benchmark construction and RL training data contributions through community co-construction mechanisms.
Click 【Read the original text】 for more information!