This article is based on a lecture from the 2024 NVIDIA GTC:
The NVIDIA Metropolis microservices suite provides a reference application for Jetson that utilizes generative artificial intelligence. This is a set of cloud-native building blocks for developing edge AI applications and solutions. This lecture will inform you about the latest microservices offered by NVIDIA Metropolis for Jetson and a new cloud-native approach to building edge applications. Explore how to build powerful visual AI applications, manage your Jetson applications from the cloud, and customize your applications using your own microservices.

Traditional AI or computer vision, especially Convolutional Neural Networks (CNNs), perform exceptionally well. Of course, it also has its sorting functionalities. However, there are challenges, and there are quite a few. Ah, for these models, I can address them in a general way. They are very rigid and fixed. Rule-based approaches do not understand context. They lack contextual understanding. Therefore, you can only obtain bounding boxes that can detect one thing or another. Then, if you need further analysis, you will have to build a special rule engine, but that does not solve the problem. Many times, the application becomes very complex during the problem-solving process. Therefore, we feel this is where generative AI can play a role, helping you gain final insights from the problems.

Imagine you have deployed cameras and drones, but for 99.9% of the time, nothing interesting is happening; they are just sitting there quietly. Now, the operator needs to see what is happening, and with generative AI, we can actually use natural language to tell it: “Hey, something is happening” or “If you see anything interesting, show me the anomalies.” If it sees an anomaly, you can react and take action based on that. Therefore, you can use natural language to build and pose questions.

Why is generative AI so important? Take the fire application scenario as an example: you first need a model to detect fires. You might also need a model to detect people because you will ask if there are civilians or firefighters present. You might also need some rules and a rule engine to define what a fire is, what a firefighter looks like, and what humans or civilians look like. Then you also need a natural language model, but this only applies to the fire application scenario. However, with generative AI, you can achieve zero-shot learning capabilities because this model is trained on a large amount of data, including a lot of internet-level data. It understands many everyday things, knows what a fire looks like, what a firefighter looks like, and what a fire truck looks like. It can infer based on contextual understanding that these people may be putting out a fire, and a large fire is happening over there. You can interact with it and ask questions, and that is the real value of using generative AI.

This is a model called VILa, also known as a visual language model. We have optimized this model for Jetson Orin, running on a model with 13 billion parameters, but the core idea is similar to that of large language models (LLM). This model takes video, images, or frames as input, while also accepting text as input, which is your questions and prompts. In this case, the output is text, and this model can run on Jetson Orin, which we have quantized to 8 bits, using MLC runtime calls for quantization, which indeed provides you with real-time performance. We can achieve a rate of about 20 tokens per second. Tokens are essentially the outputs it generates. Therefore, depending on the questions you ask, if you ask a question like describing a scene, it might generate 60 tokens based on that question. The time required depends on the number of tokens. So, using a model with 13 billion parameters, we can achieve about 20 tokens per second. Moreover, generating the first token takes about a second, so there is some latency. Again, this is a quite large model for Orin. Nevertheless, we can still run it within the memory and computational capacity of Orin.
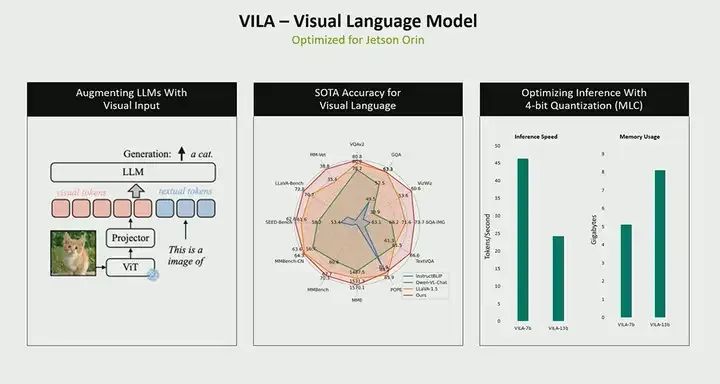
Moreover, in terms of generative AI, we actually have many different models that you can try. These can all be used as part of our Jetson AI Playground. If you haven’t checked it out yet, I highly recommend you take a look at our Jetson AI Playground.
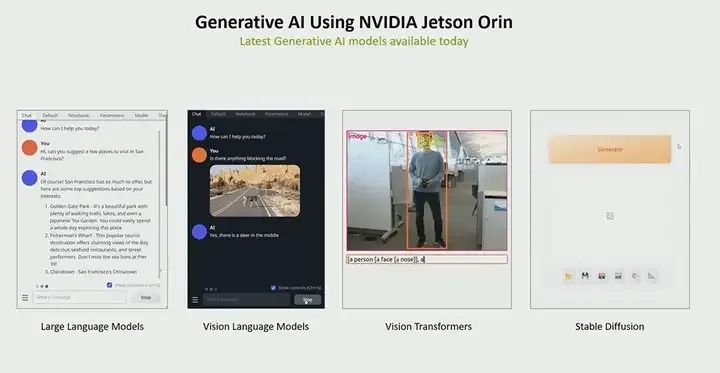
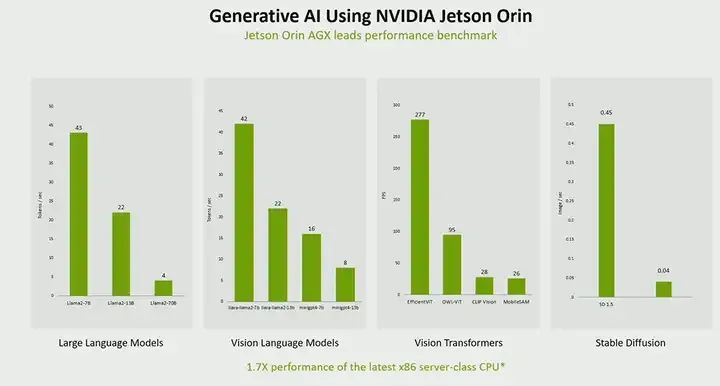
Again, why is generative AI on Jetson Orin so important? One of the main reasons is performance. As you can see, while there are many such models, we can run almost all of these models in real-time on Orin, even faster than real-time. Therefore, performance is very high, and throughput is also very large.
Jetson Services
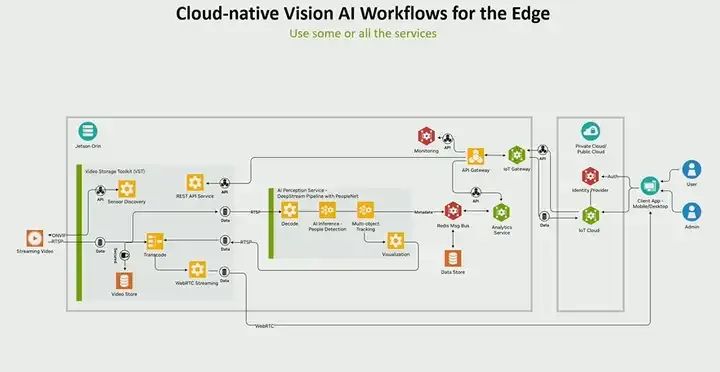
Now let’s talk about how to build it. We have released something called jetson services or metropolis microservices, which you may have heard of under another name. Our idea is to simplify application building by providing these microservices. The problem we are trying to solve is the difficulties our developers and customers face when building deployable applications. While you can do some work on a PC, when you are ready to build an application, from building models, constructing pipelines, optimizing them, to integrating everything together, it takes quite a long time. If it is a production application, you also need to consider issues like security management. Through a series of jetson services, we are trying to simplify this process. We aim to accelerate your time to market, allowing you not to have to build all these components. You can leverage some components that I will tell you about next, but you can also use your own components and customize them.
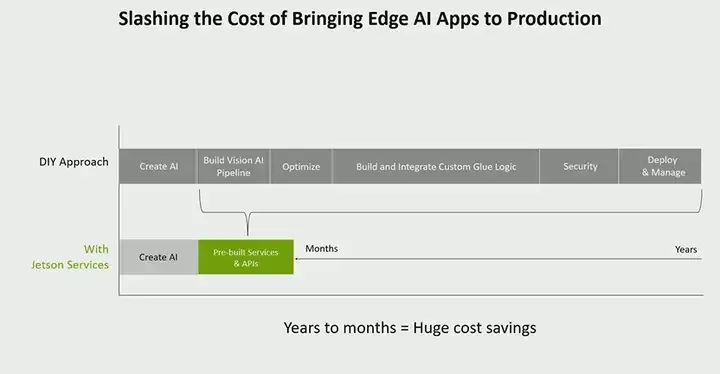
The core of the microservices we offer is a collection of cloud-native microservices. Our idea is to bring the experience built in the cloud to the edge, where everything is decoupled and API-driven microservices. This means you will find APIs that make your microservices more convenient. You can also build your own services, provide APIs, and connect with our API gateway. These services are all containerized, customizable, and allow you to bring in your own custom services. Moreover, we also provide a set of pre-built services for things like video storage and management, such as VST. We have perception services, so generative AI applications will use one of these perception services to build generative AI and VM. We also have some other perception services, as well as many core platform-level services. For example, monitoring functionality that almost everyone needs, you want to be able to monitor application performance and get alerts and more information.

Let’s illustrate what a microservices-level application might look like through a use case. Suppose your video is coming in via RTSP, for example, your live video stream or RTSP goes into VST, which is our microservice for video storage. This is a feature-rich service where you can perform sensor discovery, camera management, storage, etc., all via APIs. We provide REST APIs to perform all operations. The output of this service will go into some kind of perception service. In this example, you want to perform inference; suppose you are building an AI and VR application, you might have an inference model and tracker for people detection. We have a microservice that can handle all these operations. The entire application is built using NVIDIA’s DeepStream SDK for building high-performance streaming video analysis applications.
One part will generate some metadata; all microservices architectures require some kind of message bus to allow asynchronous communication between all different services. In our case, we use Redis as the message bus, which shares across all different services. And BT (which may refer to a specific service or component) will write to Redis, the analysis service reads the metadata, generates time series insights, and stores it in the data store, all connected via APIs.
Therefore, we can use AI services. We have AI to get API, which sends requests from your cloud to any downstream services. Again, emphasize that all these services run on the Jetson Orin platform, and in the cloud, we also have services that can deploy these applications on any clock and connect to user services deployed on public or private clouds, you can connect your identity provider for authentication and authorization, etc.
First, all these services will be provided as part of JetPack. We will provide all the services I mentioned earlier. They will all be available with our JetPack 6. In fact, we are making it very easy for all developers to access these services. Just like how you currently get JetPack, starting May, you will be able to access all these services through JetPack and the SDK manager. Everything I mentioned earlier, including the WIT gateway, all the way to your AI-based services, will be available.

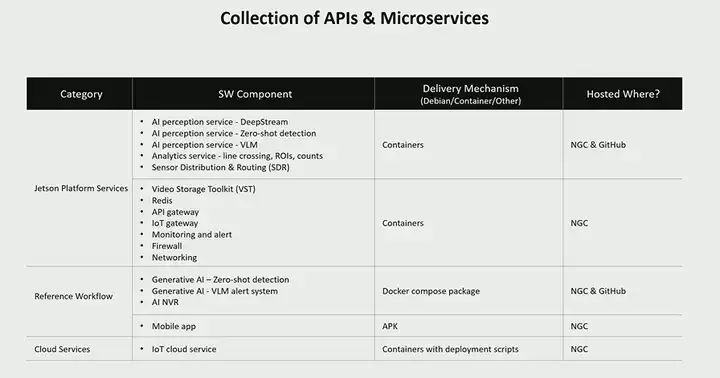
This table lists all the different microservices we offer, including platform-level services and all the different reference workflows we have here. We have several reference workflows, including several generative workflows, one of which is for zero-shot detection. This is a feature we released a few months ago, where you can provide prompts to detect any objects you want to detect, which is very useful when you do not know what the model has been trained on. You do not need a special model to detect object A or object B; you can simply say, “Hey, detect this,” for example, detect a laptop or check a bag, and it can do these tasks well.
The new VLM alert system workflow is a new feature we are about to release, expected to be available in about a month. The reference application I showed earlier is a comprehensive application from video input to AI analysis, supporting features like creating virtual boundaries, automatically setting areas of interest lines, creating virtual lines to generate time series insights, etc. Additionally, we have a mobile application to demonstrate how to integrate this application. Our idea is to simplify these processes, so we provide this application for developers to build their final products based on.
How to Integrate with Generative AI
Let’s talk about how generative AI applications integrate with various platform services.
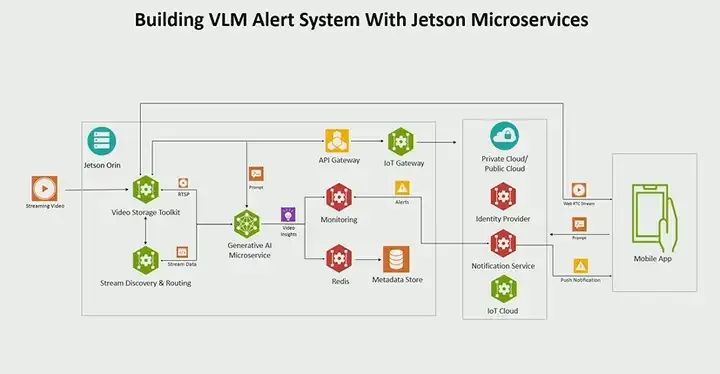
This is an alert application, so we call it the VLM or Visual Language Model alert system. The idea is that you can build this microservice, so we are not creating anything new; this is the existing architecture I showed earlier. The only thing we did was replace the perception service with our generative AI microservice, which I will show you later. But other than that, everything else remains the same. It’s that simple, so you can quickly build new applications, create new services, and plug them in directly. In fact, this is not an either-or choice; you do not need to use the entire stack or set of services. You can say you are only concerned about video management or sensor management and storage; you can choose VST; you can also say I am more concerned about monitoring, I want to see the status of jetson metrics and generate some alerts based on that; we provide a monitoring service for that. So, this architecture is very modular; it is not either-or; you can use any services you need to build your application.
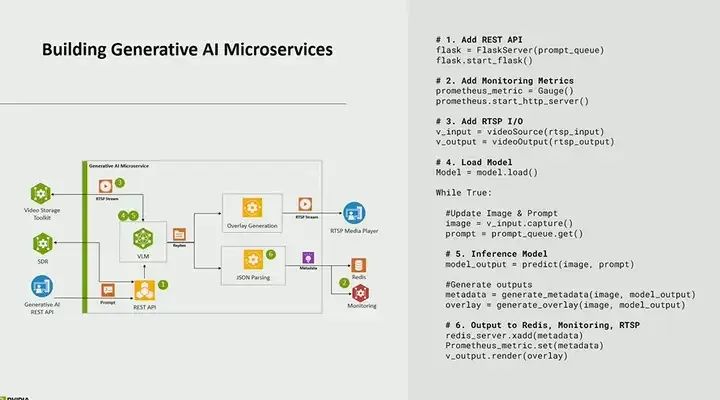
Let’s dive into the generative AI microservices. What we did is that this is actually a Python-based application that we took from our Jet AI lab and turned it into a microservice. There are some things we need to do that I won’t go into detail about, but first, you need to make it into an API so that you can call it using REST API and be able to add or remove streams, as you might have different needs; this is something that needs to be dynamically configured, and you also need to be able to provide prompts dynamically. So, the questions I provide in the application and the questions asked are all provided via API.
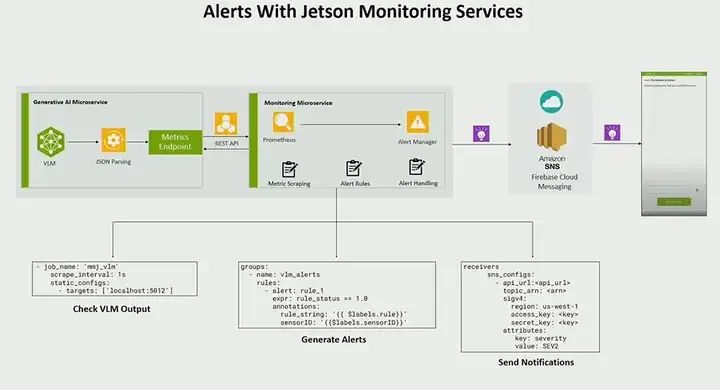
Additionally, another feature we added is that when certain things happen, this alert system will trigger. For example, if the output of the VLM is true, we want to create an alert. You might say, “There is a fire over there.” So what we did is write the metadata into our monitoring service. We added some code to create monitoring metrics, which is implemented via Prometheus. We use Prometheus, an open-source tool for monitoring and alerting.
Then, the fifth part of AI, this is actually where our inference model resides. So it reads the input, reads image input or video input. It reads the text provided via API and then generates some output; here, the output is basically a response.
Finally, we also store all outputs and all metadata in Redis. In this case, you want to be able to backtrack and see different alerts, different metadata, and the generated content, and you can do that here.
Again, emphasize that this six-step process can be done on your own perception service. This is not just an option; we provide a recipe; you may already have your own AI, and you can easily integrate it.
Another thing I showed you earlier is that this is a prompt system. You can provide natural language prompts. The way we implement alerts is by providing prompts. As you recall from the video, I said, “Is there a fire?” “Is there smoke?” So here is a system prompt call that we provide for all alerts; in this case, it indicates that the user will provide a set of rules, evaluate those rules, and respond in JSON format with yes or no. Then these are the rules provided by the user. So you get all this, provide your video frames, and then send them to your real-time model and output model, and the output will be some JSON that will say yes or no, and the number of rules. This is also fully configurable. You might have fifty rules, and then it will just print out all the different rules based on the evaluation results in JSON.
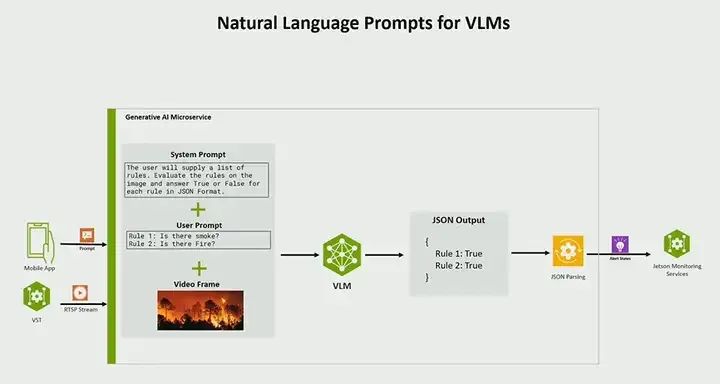
The monitoring service is actually the service that generates alerts. Here’s how it works: the monitoring microservice, as I mentioned earlier, uses Prometheus. Its operation is first to scrape these metrics; you can configure it at the bottom right or bottom left, with a scrape interval of 1 second. Therefore, it scrapes once per second, trying to pull those metrics every second. Then in the middle part is the part that generates alerts. What do you want to do with it? What action do you need to take? The last part is the notification; where do you want to send the notifications? In this case, we send it to Amazon SNS, but this can be any notification service. So get the metrics or get the output, create alerts, take action, and then send it to one of the downstream services.
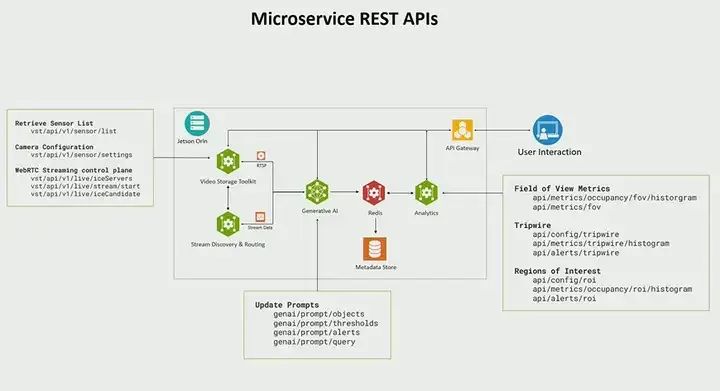
Next, I want to talk about this REST API. I mentioned earlier that we created REST APIs for almost all microservices. Starting with our VST video storage toolkit, we have a rich set of APIs to perform operations like adding sensors and retrieving a list of added sensors. You can also automatically scan for sensors. If you have cameras, you can automatically scan for sensors and be able to stream them out or perform WebRTC processing, which is very powerful, allowing you to play in your web browser, just like we demonstrated, you can stream it to WebRTC, or even say play real-time video, or show video from sensor 1 from time t0 to t1 and be able to replay it on WebRTC. In terms of generators, we have prompts to update. If you are doing zero-shot detection models, you can update what objects to detect, set thresholds, and even say what alerts you want to perform. In terms of queries, you can also provide API requests to generate or use different camera streams. Finally, in terms of analysis, I haven’t talked about our analysis capabilities, but analysis is one of our very rich microservices, providing many ready-made time series insights, such as being able to count objects, being able to count the number of people in view, or you can create virtual boundaries, allowing you to draw polygons and calculate the number of objects in the area of interest from time t0 to t1, or you can create a line to measure data coming in and out, such as the number of people entering, the number of objects entering, etc. All of this is done through APIs, which is its strength, making it very easy to build applications.
Next, I want to briefly talk about the concept of using LLM (language models). We have a VL system that can ask questions on real-time video streams, such as what is happening, when did this event happen, is there a fire, etc. But there is also a concept where you may have collected a lot of data and want to ask questions in natural language, such as “What is this data about?” or “How many are in these boxes?” For this, we are connecting a new microservice that can run on Jetson but may also run in data centers or the cloud. Its function is to take natural language prompts from users and translate them into API calls, then send them to our API gateway. So it receives natural language and converts it into API calls. We use a rag (retrieve augment generate) model. In this case, we provide a set of APIs to map natural language prompts to a series of API calls and LLM (large language models). This essentially initiates an API call to OpenAI or any other LLM. But the key is that this gives you the ability to interact with your data, interact with the data you have collected.
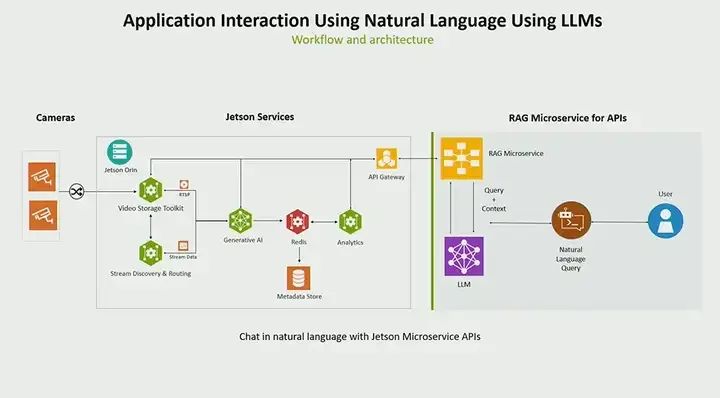
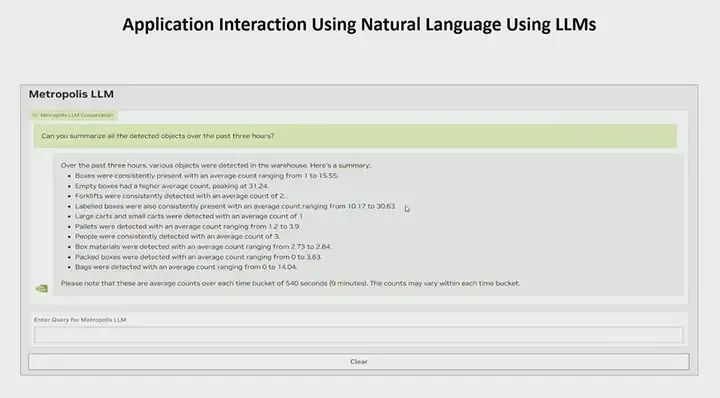
Suppose you ask a question like, “Can you summarize all the objects detected in the past three hours?” In this case, suppose you are doing detection and storing data in your data warehouse, you may already have some APIs to do this, but you want to be able to summarize it. You could write ten different API calls to accomplish this task. But in this case, you only need to write one question, and it will summarize for you and provide a very detailed list. For example, “These boxes have been present,” “forklift,” “pallet,” “person,” etc. This gives you a high-level overview of what is happening. You can say, “Hey, tell me more about the pallets, how many pallets were detected in the past three hours?” Then it will query and get only the pallet information. Okay, it even gives you a more detailed summary, telling you when all the different pallets were detected or how many times pallets were detected. You can also be more specific, such as “Tell me about the pallet information in this specific area.” If you have created sensors for a specific area, you can ask like that, or you can also provide time information. For example, “Where are the most boxes?” Maybe you want to know when your place had the most boxes. I know you can get information about the area you specified. Tell me how my analysis is in this area? So, which area has the most empty boxes? This idea is very powerful and can unlock a lot of new potential. You do not actually need to write all the different APIs or even know all the API calls. It can automatically handle those. You just need to ask questions in natural language, and it will provide summaries in natural language.
To summarize, we just discussed generative AI and how it creates powerful applications in the visual domain. Generative AI can receive visual information, receive text, and generate a wealth of insights. It uses generative AI to generate rich context. If I go back to the fire example, you no longer need to create four models to do one thing; you only need one model. You also no longer need all these custom rule engines; you don’t even need a rule engine. So how do we achieve this? Well, we have microservices. We have created a cloud-native, microservices-based architecture that provides you with modularity, allowing you to build applications quickly. You can use some of the components we provide, such as the perception services we discussed earlier, but you can also bring in your own services. We provide you with guidelines on how to insert and use your own microservices via APIs. We believe this will greatly accelerate your application development. If you plan to build applications and explore generative AI, I strongly recommend you check out our microservices or Jetson services, which will be launched in about a month.

More:
Status of Robotic Learning
What a qualified NVIDIA Jetson developer needs to know about Jetson development tools
Detailed introduction to NVIDIA Jetson products
Detailed introduction to NVIDIA edge computing solutions