In the group, developers often mention that they have several NVIDIA Jetson boards and wonder if they can “combine” them for use.
However, I also mentioned that you cannot expect the performance of a cluster to exceed that of a single, more powerful machine, which led to some questions:

Today, I saw a tutorial titled “Running a ChatGPT-Like LLM-LLaMA2 on a Nvidia Jetson Cluster”.
The author successfully installed Llama.cpp on a Nvidia Jetson board with 16GB RAM, allowing the use of the machine learning LLM to generate human-like text directly from the terminal. He ran inference on the LLaMA2 model, achieving 5 tokens per second on GPU and 1 token per second on CPU.
Then the author decided to build a Jetson cluster.
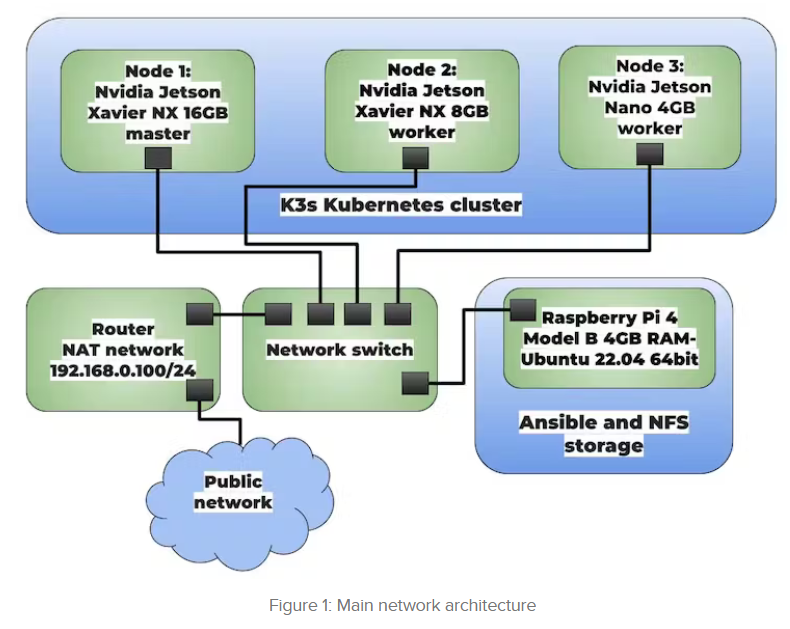
The cluster consists of three nodes:
-
Node 1: Nvidia Jetson Xavier NX 16GB – Master Node
-
Node 2: Nvidia Jetson Xavier NX 8GB – Worker Node
-
Node 3: Nvidia Jetson Nano 4GB – Worker Node
The cluster is managed by an Ansible node running on a Raspberry Pi 4 Model B. It also serves as NFS storage for data. The cluster can be expanded by adding more nodes.

The cluster is managed by an Ansible node running on a Raspberry Pi 4 Model B. It also serves as NFS storage for data. By adding more nodes, the cluster can be expanded. The author used an unmanaged 5-port switch connected to the router, allowing local communication between the master and worker nodes, while the router provides internet access to the host. The cluster operates on a local network with 1GB per second. The IP addresses are managed by the router using DHCP.
Steps:
1. Install Ansible on Raspberry Pi 4
2. Set up NFS sharing on Raspberry Pi 4
3. Lightweight Kubernetes k3S setup
4. Kubernetes dashboard setup
5. Deploy llama.cpp to the K3s cluster using Volcano and MPI
The system will create six Pods, including five worker nodes and one master node, as shown in the figure below.
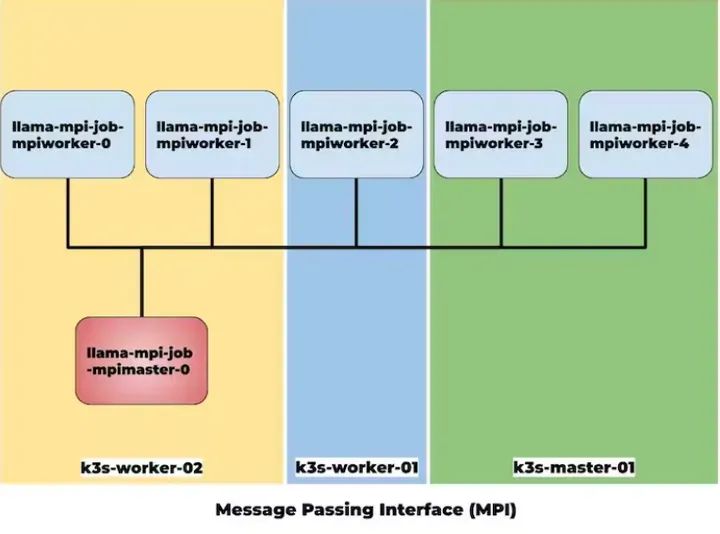
The main Pod lama-mpi-job-mpimaster-0 is responsible for managing resources and tasks in the K3s cluster.
As you can see, the author used MPI for inference of the large language model.
Here are the results from the author’s tests:
Initially, I ran it on a single master node, processing about 1 token per second. Then, I executed inference on two multi-nodes, processing 0.85 tokens per second on each node. Finally, I scaled up to run inference on all available nodes, processing 0.35 tokens per second on each node. The performance degradation when scaling inference of large language models using MPI is due to communication overhead and synchronization delays between nodes, which results in a reduced token processing speed. Communication between nodes is slower than within a single node, which can vary depending on factors such as cluster architecture.
Indeed, the performance decreased after clustering.
Regarding this result, the author’s reflection:
The MPI implementation currently supports pipeline parallelization, allowing each node to handle a portion of the pipeline and pass the results to subsequent nodes. This method enables each node to effectively focus on limited aspects of the model, allowing for efficient distribution of the model across the entire cluster. This differs from tensor parallelization, where all nodes can simultaneously process different parts of the graph, leading to more efficient handling of complex models.
Although MPI is primarily designed for inter-node communication and networking, it is not effective for inference of large language models. To achieve this efficiency, the problem needs to be broken down into smaller chunks and distributed to different nodes. Once each node completes processing its assigned chunk, the results must be reorganized and merged to generate the final output.
In a typical inference pipeline using large language models (LLMs), the model must be reloaded each time, which can introduce significant latency, especially when dealing with large models. In such cases, the wait time for the model to produce output can exceed several minutes.
Large language models (LLMs) are known to have what is referred to as “hallucinations.” This means they can generate seemingly accurate human-like text information, but it is, in fact, incorrect information. The goal of model quantization is to reduce parameter precision, typically from 16-bit floating-point to 4-bit integer. This is a 4x compression of the model. Most quantization methods experience some degree of information loss, resulting in performance degradation. This process involves a trade-off between model accuracy and inference performance.
Before distributing applications across multiple nodes, consider optimizing them. Distributing compute-intensive tasks across different nodes does not guarantee it will outperform processing on a single node.
In addition to GPU and CPU, you also need sufficient RAM (random access memory) and storage space to hold model parameters and data. The amount of RAM required depends on the type of GGML quantization and the model you are using.
The author’s complete tutorial has been translated and is available on Zhihu for everyone to read: