0. Introduction
From the author’s perspective, autonomous driving and embodied intelligence are becoming increasingly close. Whether it is the technology stack or the ultimate goal, both aim to keep humans in the loop. This is a rough outline of the text related to GuYue’s live broadcast. The main focus will be on the evolution of autonomous driving and some technical points that practitioners in the field should pay attention to.
1. Evolution of Autonomous Driving
In the continuous evolution of autonomous driving technology, the modular design of the end-to-end architecture has gradually revealed its unique advantages and challenges. In the second phase of decision-making and planning modular design, compared to traditional rule-based solutions, the system’s ability to handle complex scenarios has been significantly enhanced. This model-based approach not only makes full use of large amounts of data but also simplifies the model upgrade process, enabling the system to adapt more quickly to new environments and demands.
1.1 Traditional Autonomous Driving Architecture
The traditional autonomous driving architecture is largely derived from robotic architecture. Therefore, the three major modules of perception, localization, and planning in the field of robotics have long been the tone of the development of autonomous driving architecture. A typical autonomous driving system usually includes the following core modules:
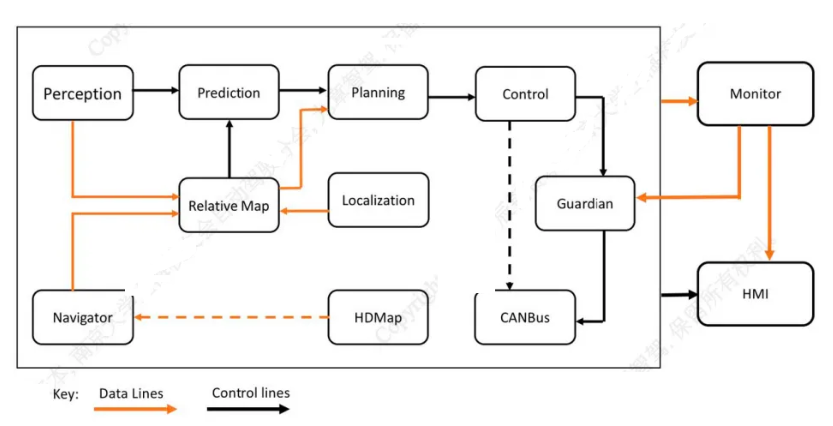
Perception Module
The perception module is responsible for collecting and interpreting information about the vehicle’s surrounding environment. This includes using various sensors such as cameras, LiDAR, radar, and ultrasonic sensors to detect and recognize surrounding objects, such as other vehicles, pedestrians, traffic signals, and road signs. The perception module needs to process data from these sensors and convert it into an environmental model that the vehicle can understand. The output of traditional perception modules is often based on human definitions, such as detecting surrounding obstacles and segmenting boundaries and regions. Traditional perception systems ensure that their output is understandable to humans, representing an abstraction of the environment.
Localization Module
The localization module’s task is to determine the precise location of the vehicle within the environment. This typically involves using GPS, inertial measurement units (IMU), and sensor data to estimate the vehicle’s global position. Additionally, map-based localization techniques can be employed, such as matching the vehicle’s sensor data with pre-made detailed maps.
Prediction Module
The prediction module is used to predict the behavior and intentions of other road users, such as predicting the trajectories of other vehicles and the movements of pedestrians. This helps the autonomous driving system make decisions in advance to avoid potential collisions and conflicts.
Decision and Planning Module
The decision module is responsible for formulating the vehicle’s driving strategy based on information from perception and prediction. This includes selecting the best driving path, deciding when to change lanes or overtake, and how to respond to complex traffic situations. The planning module is responsible for generating detailed driving trajectories, ensuring the vehicle can safely and efficiently travel from its current location to its destination.
Control Module
The control module executes the actual vehicle control commands output by the decision and planning module. It is responsible for precisely controlling the vehicle’s throttle, brakes, and steering to achieve smooth and safe driving.
The traditional approach to module division makes independent development of each module easier and simplifies and speeds up problem tracing. However, the cost of this approach is that it limits the flexibility and generalization capabilities of the modules and the entire system.
1.2 Evolution of End-to-End Autonomous Driving Architecture
Currently, the evolution of autonomous driving architecture can be divided into four main stages:
1.2.1 Stage One: Perception “End-to-End”
In this stage, the entire autonomous driving architecture is divided into two main modules: perception and prediction decision planning, where the perception module has achieved module-level “end-to-end” through multi-sensor fusion-based BEV (Bird Eye View) technology. By introducing transformers and cross-sensor cross-attention schemes, the accuracy and stability of perception output detection results have seen significant improvement compared to previous perception schemes, however, the planning decision module is still primarily rule-based.
1.2.2 Stage Two: Decision Planning Modeling
In this stage, the entire autonomous driving architecture is still divided into two main modules: perception and prediction decision planning, where the perception side still maintains the previous generation’s solutions, but the prediction decision planning module has undergone significant changes—the functional modules from prediction to decision to planning have been integrated into the same neural network. It is worth noting that although perception and prediction planning decisions are implemented through deep learning, the interface between these two main modules is still based on human understanding definitions (such as obstacle locations, road boundaries, etc.); additionally, in this stage, each module will still conduct independent training.
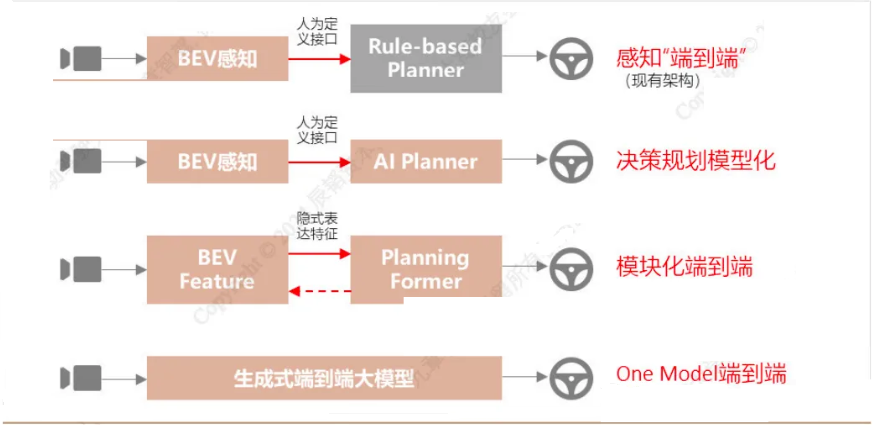
1.2.3 Stage Three: Modular End-to-End
Structurally, this stage’s structure is similar to the previous stage, but there are significant differences in the details of the network structure and training schemes. First, the perception module no longer outputs results based on human-understandable definitions, but instead provides feature vectors. Accordingly, the comprehensive model of the prediction decision planning module outputs motion planning results based on feature vectors. In addition to the output between the two modules transitioning from human-understandable abstractions to feature vectors, the training approach in this stage requires the model to support cross-module gradient propagation—both modules cannot be independently trained; training must occur simultaneously through gradient propagation.
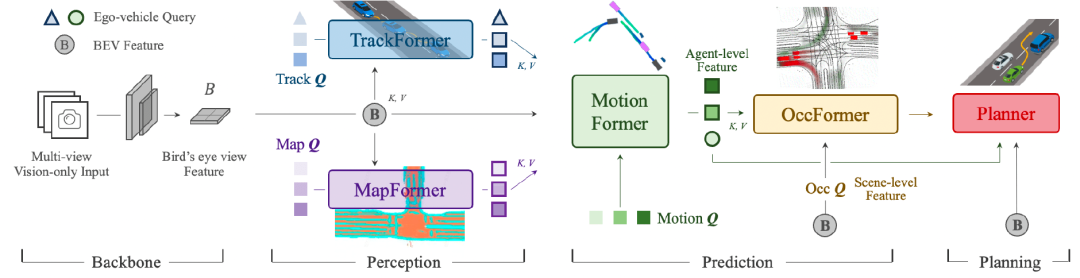
1.2.4 Stage Four: One Model/Single Model End-to-End
In this stage, there are no longer distinct functions for perception, decision planning, etc. From the input of raw signals to the output of final planning trajectories, a single deep learning model is directly used. Depending on the implementation scheme, this stage’s One Model can be an end-to-end model based on reinforcement learning (RL) or imitation learning (IL), or it can be derived from generative models like world models. Currently, more work seems to be focused on perception measurement. However, ideas like FSD’s WM+RL still rely on large amounts of data to execute and perform self-supervised learning (https://hermit.blog.csdn.net/article/details/139148727)
1.3 Rule-driven → Data-driven → Data + Knowledge-driven
As the tasks of autonomous driving evolve from single perception tasks to a comprehensive multi-task of perception and decision-making, the diversity and richness of the data modalities for autonomous driving become crucial. Relying solely on models trained on large amounts of collected data can only achieve third-person intelligence, i.e., an AI system that observes, analyzes, and evaluates human behavior and performance from an outsider’s perspective (which is what we refer to as enabling robots/autonomous vehicles to have self-thinking abilities). The ultimate form of autonomous driving will be to achieve general artificial intelligence in the field of driving, making the shift from data-driven paradigms to knowledge-driven paradigms an inevitable requirement for the evolution of autonomous driving.
The knowledge-driven paradigm does not completely detach from the original data-driven methods, but rather builds upon them by adding the design of knowledge or common sense, such as common sense judgment, experiential induction, and logical reasoning. Knowledge-driven methods need to continuously summarize from data and rely on AI agents to explore the environment and acquire general knowledge, not executing predefined human rules or abstracting features from collected data.
1.3.1 Rule-driven
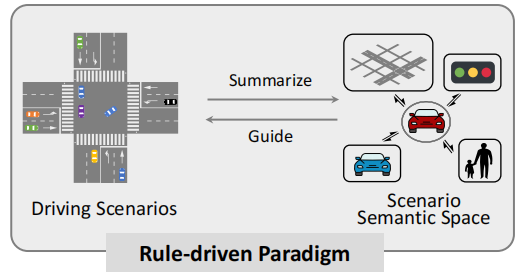
Rule-based Scene Understanding: In the rule-driven paradigm, autonomous driving systems rely on expert-defined rules to understand driving scenes. These rules are typically based on a deep understanding of traffic regulations, road conditions, vehicle behaviors, etc.
Guided Driving by Rules: The system uses these rules to make decisions, such as path planning, speed control, and obstacle avoidance. For example, stopping at a red light or driving at a speed limit in specific areas.
When autonomous driving was first developed, this method emphasized logic and determinism, making it suitable only for scenarios where rules could be clearly defined. However, as the number of autonomous driving scenarios increased and roads became increasingly complex, the rule-based paradigm could no longer meet the demands of autonomous driving-related technologies.
1.3.2 Data-driven
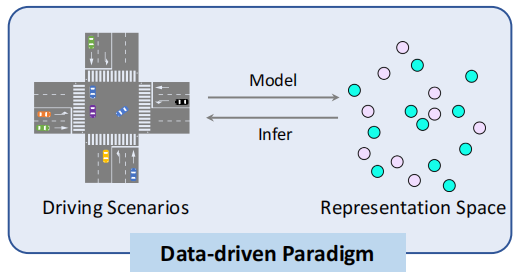
Modeling Driving Scenarios: The data-driven paradigm focuses on learning and simulating driving scenarios through large amounts of data. This data may include sensor data, driver operations, traffic flow, environmental conditions, etc.—that is, imitation learning.
Real-world Inference: Through machine learning algorithms, the system can learn patterns from data and apply them to real-world driving tasks. For example, optimizing driving strategies by analyzing data under different road conditions—this is reinforcement learning.
At this stage, while the data-driven paradigm can handle complex and changing environments, it requires a large amount of training data. As the volume of collected data increases, the likelihood of covering new extreme situations decreases, and the marginal effect of capability enhancement becomes weaker.
The data-driven method is gradually approaching its development bottleneck. In the anticipated iterations from L1 to L2, upgrading from L1 to L2 by increasing the number of sensors, then achieving L3 by increasing data volumes to adapt to more scenarios, aiming for levels L4 and even L5. However, in practice, despite increasing data volumes at the L2 stage, it seems to encounter an insurmountable barrier, consistently reaching only a near L3 level of L2.999, indicating a persistent bottleneck.
1.3.3 Data + Knowledge-driven
Knowledge-enhanced Representation Space: The knowledge-driven paradigm combines knowledge and data in the field of autonomous driving. It enriches the model’s understanding of scenarios by introducing information about driving scenarios into a knowledge-enhanced representation space.
Generalized Knowledge Deduction: The system not only learns scenario-specific patterns but also attempts to derive more generalized knowledge that can be applied across different scenarios and conditions.
Knowledge Reflection Guidance: By reflecting on and optimizing its decision-making process, it guides driving in a smarter and more adaptive way. For example, the system might use knowledge of traffic rules to interpret and predict the behavior of other vehicles.
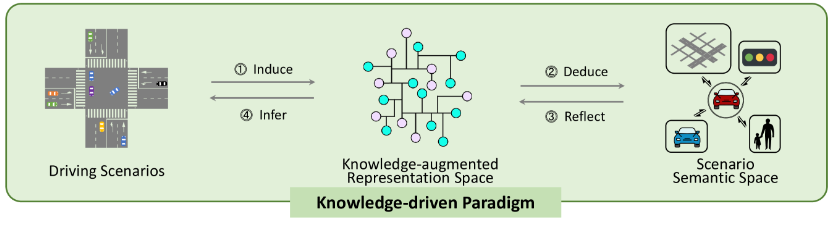
At this stage, knowledge-driven methods can construct a foundational model with general understanding capabilities by summing experiences from multi-domain data, thereby compressing the driving capability space into a low-dimensional manifold space. This space corresponds to driving scenarios that not only include data collected during training but also encompass a vast amount of unseen data, including numerous extreme situations.
This introduces the concept of embodied intelligence: Embodied intelligence, upon perceiving a scene, attempts to understand that scene and formulate a plan. After executing the plan, two outcomes may arise: success or failure. Success is stored as experience; failure requires the model to reflect and regenerate a successful plan to avoid similar incidents. This information is stored in a memory bank. When encountering similar scenarios, the system first queries the memory bank to determine if it has previously dealt with a similar situation, and based on the characteristics of the current scene and past experiences, it makes a decision. The entire process requires embodied intelligence to possess reasoning and decision-making capabilities.
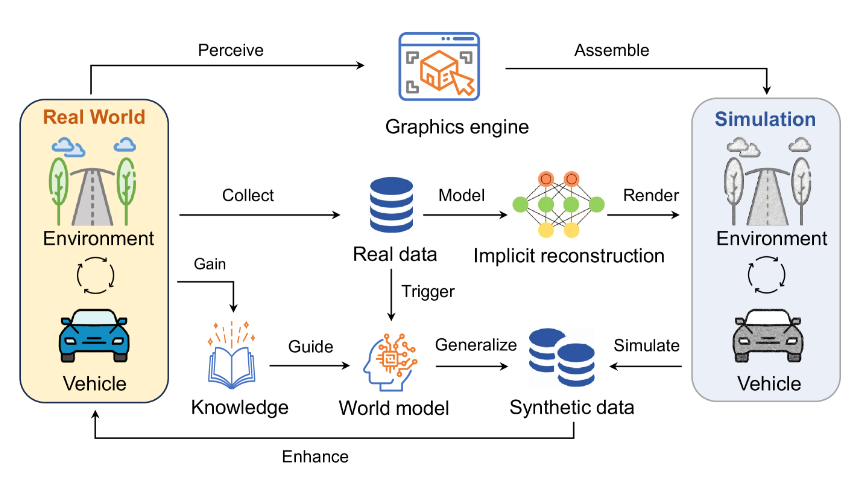
In addition to understanding the current scene, it can also leverage the inherent characteristics of transformers to combine knowledge and data to construct world models (WM), aiding in a realistic understanding of the driving environment. This approach emphasizes not just data collection but also a deep understanding of data and the application of knowledge, rendering simulated environments through data collected from multiple sources. The predictive capability of the world model includes inferring the relative positions and motion trends of other vehicles based on current and past scene information, thus enabling modeling of potential impacts of various actions and making informed decisions.
2. Embodied Intelligence in the Field of Robotics
Applications in Work
From the above, we can see that autonomous driving is already approaching embodied intelligence, and it can be considered a form of embodied intelligence. Currently, the industry mainly discusses embodied intelligence in the context of robotics and robotic arms. While the technology stacks are broadly similar, there are still some distinctions involved, such as the complex motion control of robotic arms in many cases.
For example, at the end of last year, Fei-Fei Li’s team published a paper titled Voxposer, introducing an open command and open object trajectory planner based on LLM (Language to Layout Module) and VLM (Vision to Layout Module). This advancement pushes the boundaries of robotic mapping and task planning to a new stage.
For instance, for the command “open the drawer, but be careful with the vase,” the LLM analyzes the command and understands that the drawer is an attractor area (affordance_map), while the vase is a constraint area (constraint_map). Then, using VLM, it obtains the specific locations of the vase and drawer. The LLM generates code to construct a 3D Value Map, and the motion planner can synthesize the trajectory for the robot to execute the task in a zero-sample manner.

The differences in perception measurement are not significant. By adjusting some code data, it can be made general. However, the more challenging aspect is the learning control of robots, as they have higher degrees of freedom and complexity. Therefore, most work focuses on how to enable robots to acquire new skills and adapt to environments through interaction and learning. This integrates machine learning with robotics, aiming to allow robots to learn and grow like humans. In fact, robotic learning has also undergone development in several research directions:
The first stage involves combining traditional control algorithms with reinforcement learning for robotic control.
The second stage saw the introduction of deep reinforcement learning (DRL), with DeepMind’s AlphaGo achieving significant success. DRL can handle high-dimensional data and learn complex behavior patterns, making it particularly suitable for decision-making and control problems, thus becoming a natural choice for robotics.
In the third stage, the limitations of DRL became apparent as it requires a large amount of trial-and-error data. Efficient learning operations are accomplished through the fusion of imitation learning, offline reinforcement learning, online reinforcement learning, and Sim2Real, such as the previously mentioned DRL-robot-navigation (https://hermit.blog.csdn.net/article/details/142894286), which is a Sim2Real wheeled robot movement method.
2.1 Imitation Learning
Imitation learning aims to minimize the amount of data required by collecting high-quality demonstrations. Google DeepMind and Stanford University jointly released Mobile ALOHA, showcasing a versatile home robot that drew widespread attention, making imitation learning a focal point. They developed a remote operation system for a dual-arm wheeled chassis. Detailed information can be found in this article (https://blog.csdn.net/v_JULY_v/article/details/135429156).

2.2 Offline Reinforcement Learning + Online Reinforcement Learning —-> Sim2Real
The fusion of offline reinforcement learning and online reinforcement learning improves data utilization efficiency, reduces the cost of environmental interaction, and ensures safety. It first learns policies from a large static, pre-collected dataset using offline reinforcement learning, and then deploys them in real environments for real-time interaction and adjusts policies based on feedback. The core concept in reinforcement learning is the interaction between the agent and the environment.
The agent observes the state of the environment, selects actions to alter the environment, and the environment provides rewards and new states based on the actions taken. The agent’s goal is to learn to select the optimal policy to maximize cumulative rewards over a long period of interaction. This cyclical interaction process helps the agent learn how to make the best decisions in different states through trial and error.
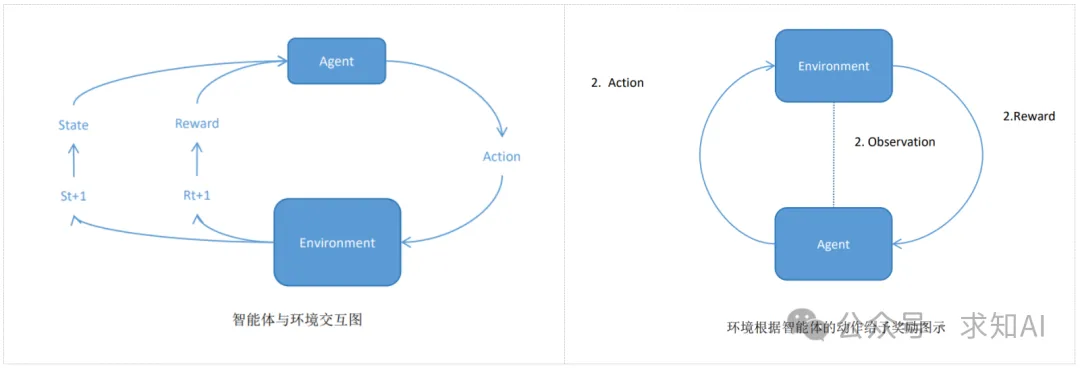
The core mathematical principles include Markov chains.
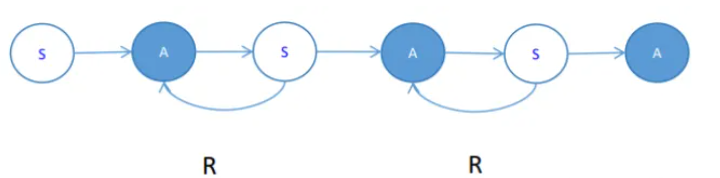
Three important factors: S, A, R, which are state, action, and reward. (1) The agent observes state S in the environment; (2) State S is input to the agent, which computes and executes action A; (3) Action A transitions the agent to a new state and returns reward R to the agent; (4) The agent adjusts its policy based on the reward. The reward phase is further divided into Reward (immediate reward): the instantaneous reward received by the agent at this step. Return (total reward): the total accumulated reward from the current state to the endpoint. Q-value (action value): evaluates the expected cumulative reward the agent can obtain from the current state to the final state after choosing a specific action in that state. The calculation of Q-value is similar to: starting from the current state, assuming multiple