 Click the blue text to follow us
Click the blue text to follow us
First, let me clarify that this section and the following ones are the author’s insights from learning about Redhat’s network virtualization. Readers who are impatient can directly click:
https://www.redhat.com/en/blog/introduction-virtio-networking-and-vhost-net
https://www.redhat.com/en/blog/deep-dive-virtio-networking-and-vhost-net
https://www.redhat.com/en/blog/hands-vhost-net-do-or-do-not-there-no-try
The three elements of virtualization:
For network cards, in a virtualized environment, one or more VMs run on a physical machine, and these VMs have independent operating systems, which are run on the physical machine’s operating system through a hypervisor. At the same time, this physical machine must provide corresponding resources to the VMs, such as providing a virtual network card to the VMs, which the VMs treat as a real physical network card. This involves three parts:
KVM
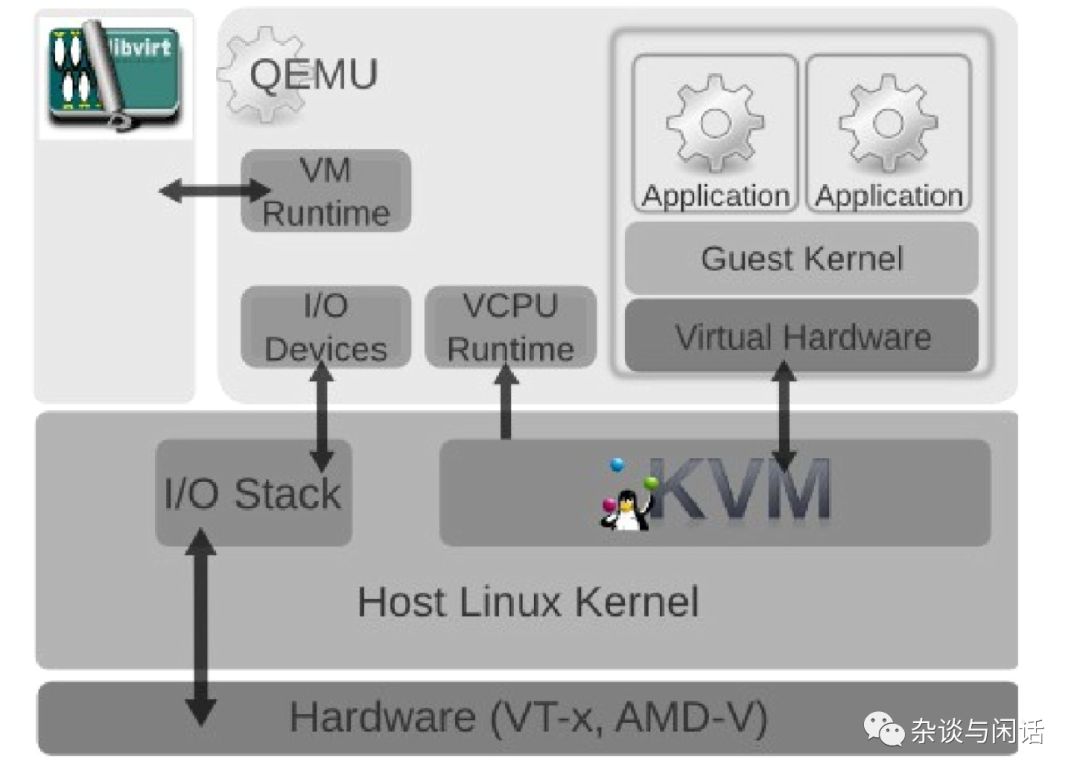
The kernel-based VM allows Linux to function as a hypervisor. This module provides the necessary functions for a hypervisor, while functions such as memory management, scheduling, and network protocol stacks are provided by the Linux kernel. These VMs are like user-space processes managed under the standard Linux process scheduler, with the only difference being that they have exclusive virtual hardware devices.
QEMU
A virtual machine monitoring process running in the host user space, which provides a range of different hardware and device interfaces to the VMs through emulation. Together with KVM, QEMU can provide VMs with performance close to that of real hardware. A guest can configure QEMU via CLI.
Libvirt
A tool that converts XML-based configuration information into QEMU CLI commands. It also provides a management daemon to manage subprocesses, such as QEMU, so that QEMU does not require root privileges. Therefore, in OpenStack Nova, when creating a VM, it can create a QEMU process for the VM through Libvirt, creating a separate QEMU process for each VM.
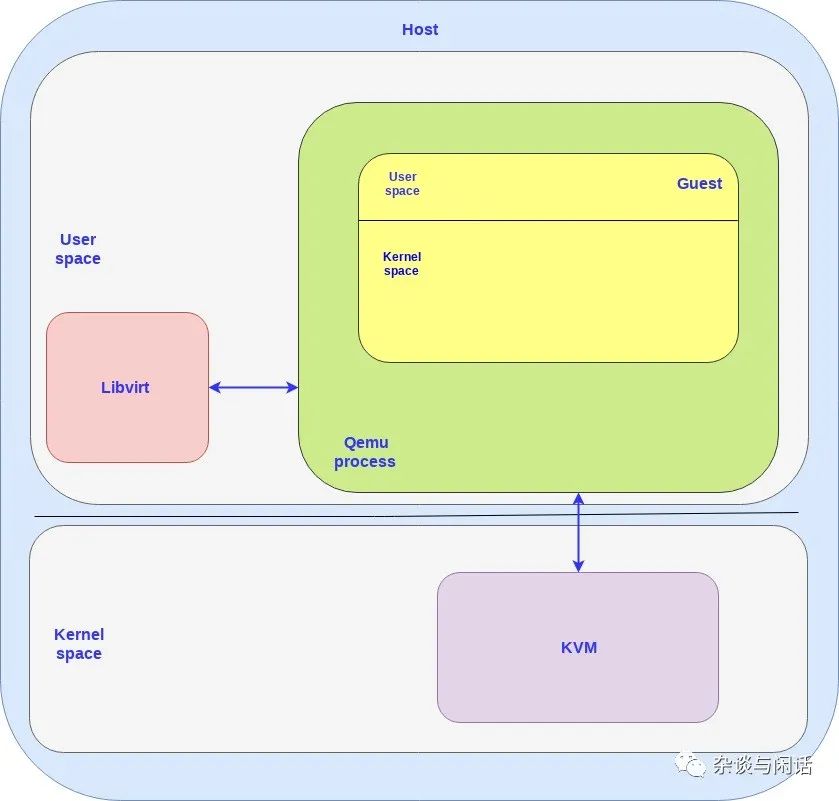
Therefore, in this block diagram, the points to note are:
-
Both host and guest have user space and kernel space.
-
The OS on the guest runs as a user-space process under QEMU.
-
For the host, the number of VMs corresponds to the number of QEMU processes, and Libvirt can interact with them.
In the above diagram, it can be seen that CPU virtualization is achieved through the collaboration of QEMU and KVM, while VM management is implemented by Libvirt. However, I/O virtualization is primarily implemented by the existing kernel protocol stack of the host. This is the root of all issues.
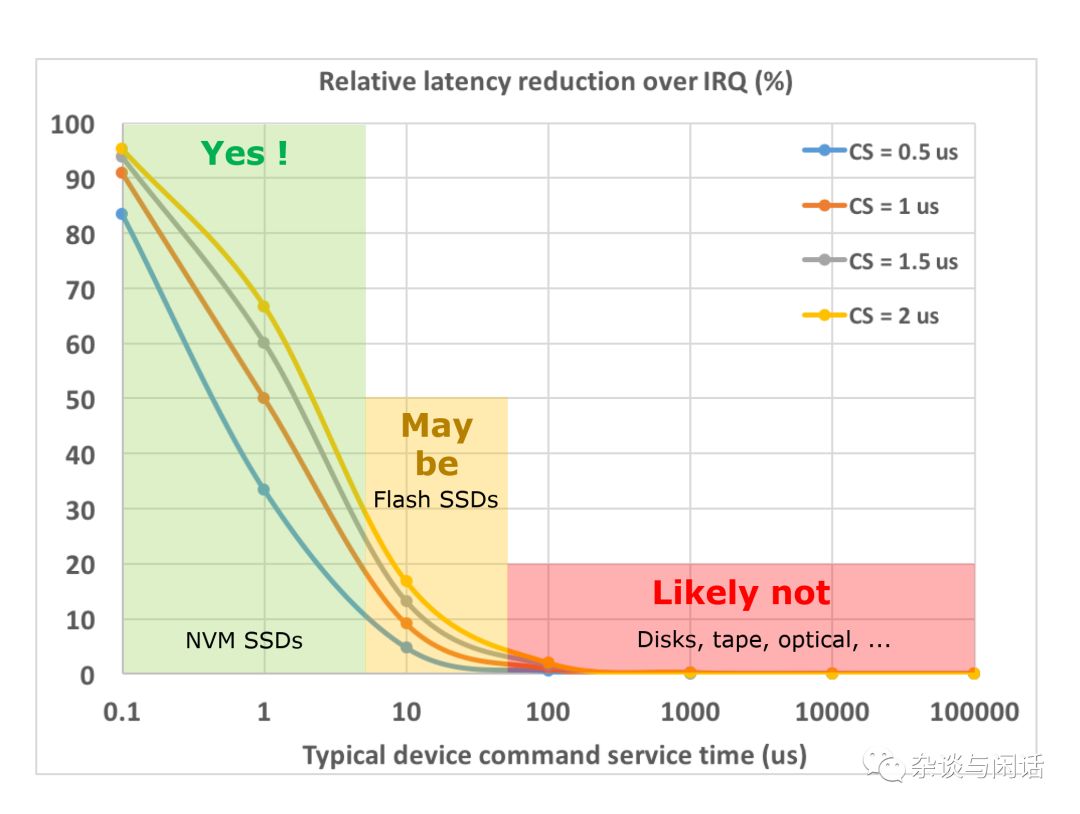
The I/O stack is inherently slow; for the Linux kernel network stack, the default packets per second (pps) is 350K[1]. By utilizing multi-queue network cards and multi-threading on the CPU, it can eventually reach 1M pps. For disk I/O, those who have used HBA+SSD configurations know the overhead of the Linux block I/O stack. For NVMe SSDs, IRQ becomes a relatively large overhead.
At the same time, the original QEMU networking is based on file TAP/TUN interfaces.[2]
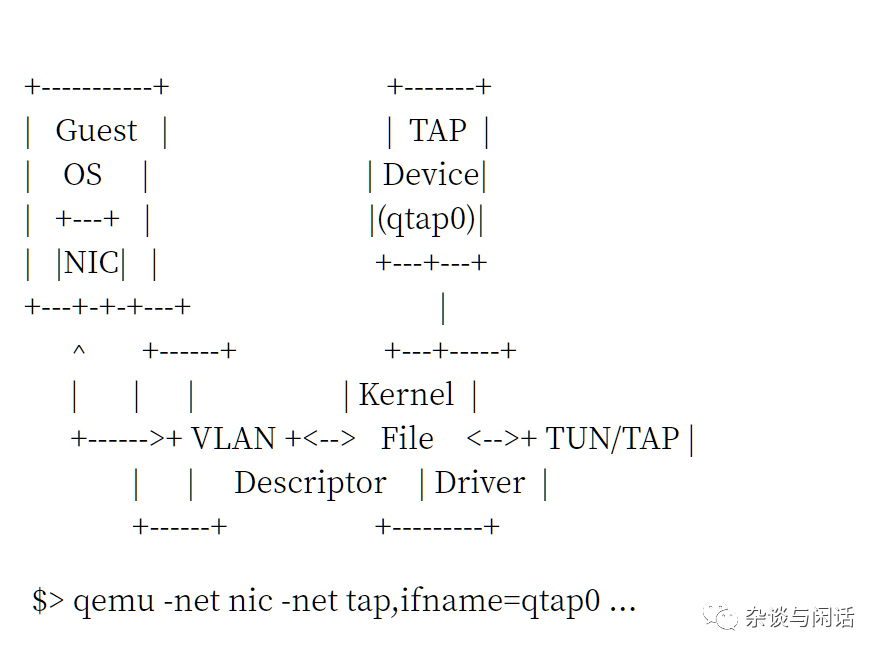
Everyone should note that with such a slow stack, we have to go through it twice, twice, twice.
What to do? The default KVM I/O stack is indeed unusable; both performance and CPU consumption are issues. At this point, everyone thought of the evolution process in CPU virtualization, from full instruction simulation to paravirtualization. This is when the Virtio interface shines.[2]
VirtIO
VirtIO defines control and data paths. The control path’s function is to establish and clear the data path between the host and guest. The data path focuses on the transmission of packet payloads between the host and guest. Having two paths means different paths. The control path requires manageability and flexibility, while the data path demands performance. The Virtio specification can be divided into two parts:
-
virtio spec – The Virtio spec, maintained by OASIS, defines how to create a control plane and a data plane between the guest and host. For example, the data plane consists of buffers and ring layouts detailed in the spec.
-
vhost protocol – A protocol that allows the Virtio data plane implementation to be offloaded to another element (user process or kernel module) to enhance performance.
The control path of Virtio is implemented in the QEMU process according to the Virtio specification, but the data path cannot be done this way because each time data moves from the Guest OS to the Host OS, a context switch is required, which is too costly. Therefore, the data path must bypass QEMU.
The purpose of Vhost is to establish a direct path from the host kernel to the guest, thereby bypassing the QEMU process. The Vhost protocol defines how to establish the data path, but there are no strict regulations on how to implement it; this implementation depends on the layout of rings and the description of data buffers on the host and guest, as well as the mechanisms for sending and receiving data packets.
Vhost can therefore be implemented in the kernel (vhost-net) or in user space (vhost-user).
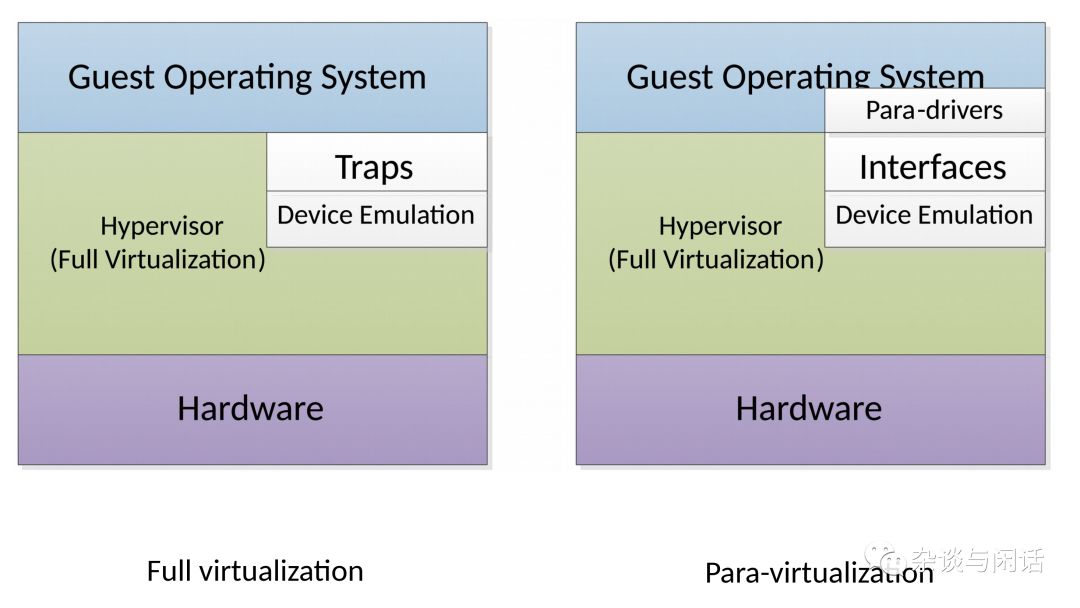
Let’s first look at the vhost-net/virtio-net implementation.
In this diagram, the Virtio backend interface runs on the host’s kernel as vhost-net, while the Virtio frontend interface runs on the Guest Kernel as Virtio-net.
Between the frontend and backend, we have data and control paths. The control path, as shown in blue in the diagram, is established between the vhost-net kernel driver and the QEMU process, as well as the guest’s virtio-net. Vhost-net follows the Vhost protocol specification to establish a direct data channel between the host and guest kernels based on shared memory areas.
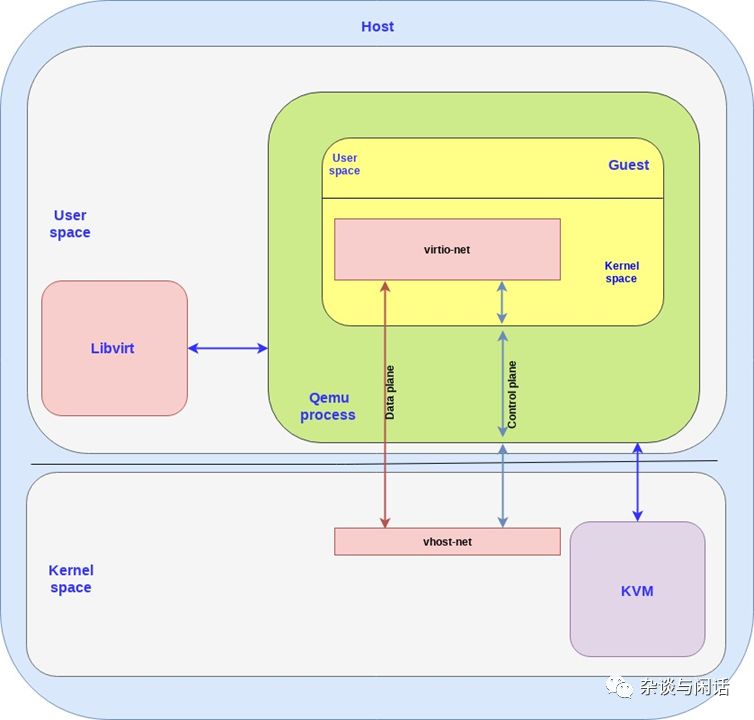
For performance, since Virtio itself is defined by queues, multi-queue implementation is achieved.[3]
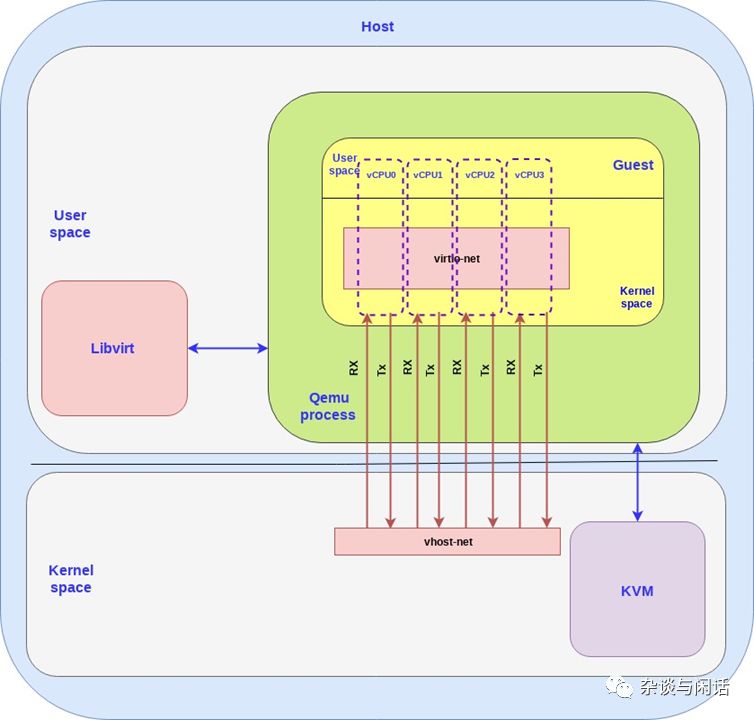
So far, we have discussed how the guest sends data to the host kernel; this is just the data between the VM and PM. In a real cloud computing environment, we also need to address the data issues of VMs on one PM and the data of VMs on two different PMs, which is where OVS comes into play.
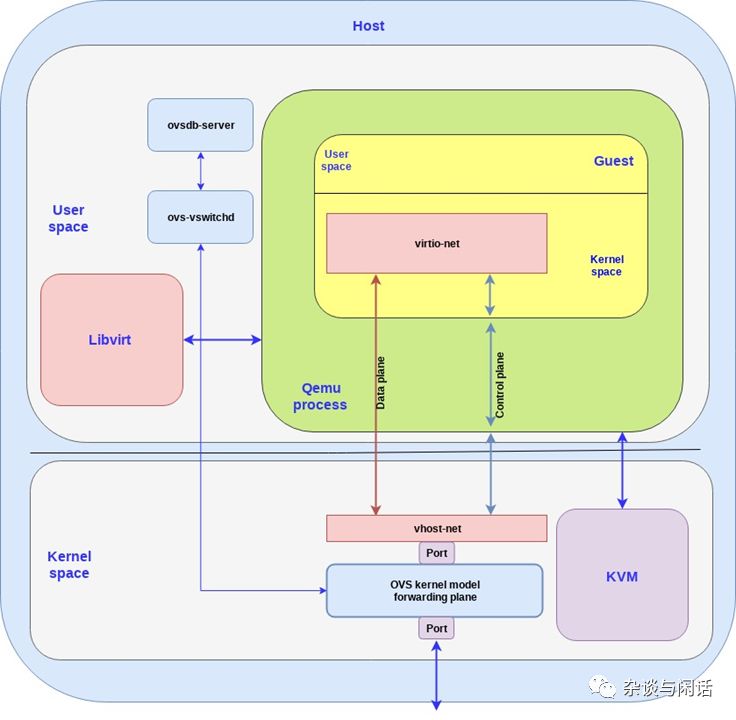
It can be seen that the implementation of OVS and Virtio-networking consists of two parts:
-
User space on the host, which implements the OVSDB database and manages the vswitch daemon.
-
The host kernel, which implements the data path and forwarding path through the OVS kernel driver.
The OVS controller and database server communicate with the forwarding path of the host kernel. We use the Linux port mechanism to allow network packets to enter and exit OVS. In the diagram, we use one port to connect the physical network and the OVS kernel forwarding path, and another to connect to the backend vhost-net of Virtio-networking. It should be noted that in reality, we can have multiple network cards connected to OVS through multiple ports, while multiple VMs can have multiple backend vhost-net connections to OVS.
So far, we are still reviewing and summarizing; this is the classic KVM+QEMU+Virtio+OVS structure, which is probably not widely used anymore. But before moving towards user-space DPDK, we should dive deeper.
Deep Dive into Virtio-Networking and Vhost-Net
Networking
In our discussion, the physical network card is a real physical device that helps the computer connect to the outside world. It may have some CPU offloading capabilities, similar to the offload network cards mentioned earlier, supporting TSO, LSO, etc.
In the Linux network, there is also the concept of virtual networks TUN/TAP, which provide point-to-point network connections, allowing user-space applications to exchange network packets. TAP supports L2 Ethernet frames, while TUN supports L3 IP packets.
When the TUN Linux kernel module is loaded, it creates a /dev/net/tun device. A process can create a TAP device and open it, using the ioctl interface for operations. A new TAP device will be created in the /dev file system with a device name, which other processes can access to send or receive Ethernet frames.
IPC, System Programming
Inter-process communication is an old friend of Unix programming, especially in the parts combined with QEMU and Vhost. If you look at the code, you will see the eventfd model.[5] The most commonly used is to implement an event-driven thread pool. Of course, the eventfd file handle can also have more modes, such as poll, select, epoll, and being written to and notified (callback).
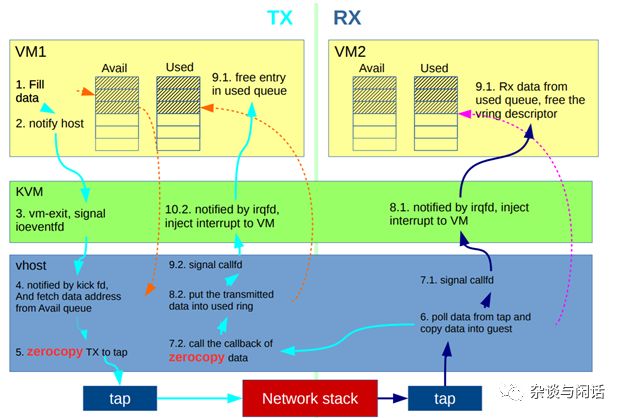
This is the KVM and QEMU-based IPC network communication mechanism.[6]
QEMU and Device Simulation
Although QEMU appears to be just an ordinary process from the host’s perspective, containing its own memory space, from the perspective of the guest VM, the memory space provided by QEMU is its physical memory.
For the host, when interacting with real physical devices for I/O, special instructions must be executed, and pre-allocated memory address spaces must be accessed. Therefore, when QEMU wants to access this space, control must return to QEMU, which provides interfaces to the guest through device simulation.
Virtio Spec Device/Driver
The Virtio specification includes two important elements: devices and drivers. In a common deployment, the hypervisor exposes Virtio devices to the guest through certain mechanisms. From the guest’s perspective, these devices are its physical devices.
The commonly used mechanism is the PCI or PCIe bus. Of course, devices can also be placed in predefined guest memory addresses through MMIO. The physical devices seen by the guest OS can be completely virtualized (with no corresponding host physical devices) or correspond to an interface of a device.
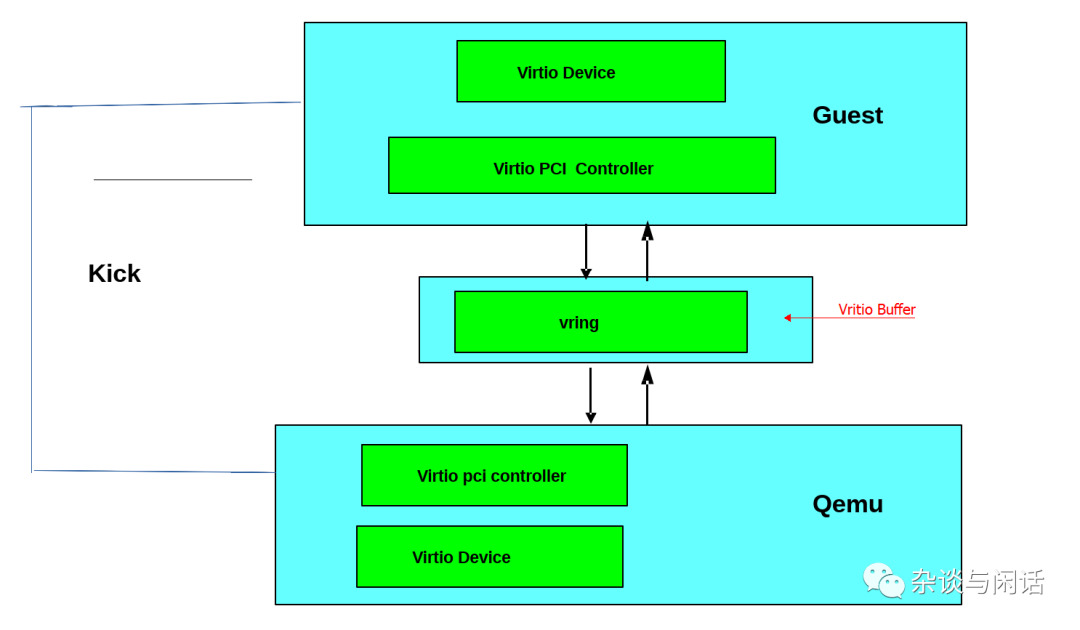
The benefit of exposing devices through the PCI protocol is leveraging the widespread use of PCI. Real physical PCI devices have a segment of memory space for configuration space, and drivers can read and write the PCI device’s registers through this address space. In virtualization, the hypervisor intercepts access to these address spaces and performs device simulation, providing the corresponding memory address space content and access responses as if it were a physical machine. The Virtio protocol defines these PCI configuration spaces.
When the guest starts and initializes PCI/PCIe, the Virtio device will provide the corresponding PCI vendor ID and device ID, and the guest OS will call the corresponding driver for interaction, which is the Virtio driver.
The Virtio IO driver must allocate a memory area that both the hypervisor and the Virtio device can access, generally through shared memory. The previously discussed data path utilizes these memory areas for data transfer, while the control path is for setting up and maintaining this memory area.
Virtio Spec Virtqueue
Each Virtio device has 0 or n Virtqueues. A Virtqueue consists of a series of buffers allocated by the guest, which can also be read and written by the host. The Virtio protocol also defines a bidirectional notification mechanism.
-
Available Buffer Notification: Used by the driver to signal that there are buffers ready to be processed by the device.
-
Used Buffer Notification: Used by the device to signal that it has finished processing some buffers.
For example, with a PCI device, the guest can send an available buffer notification by writing to a special memory address, while the Virtio device can use the vCPU interrupt to send a used buffer notification.Of course, this notification mechanism can be dynamically disabled, allowing the Virtqueue to use polling mechanisms, which will be explained in detail in the next chapter on DPDK.
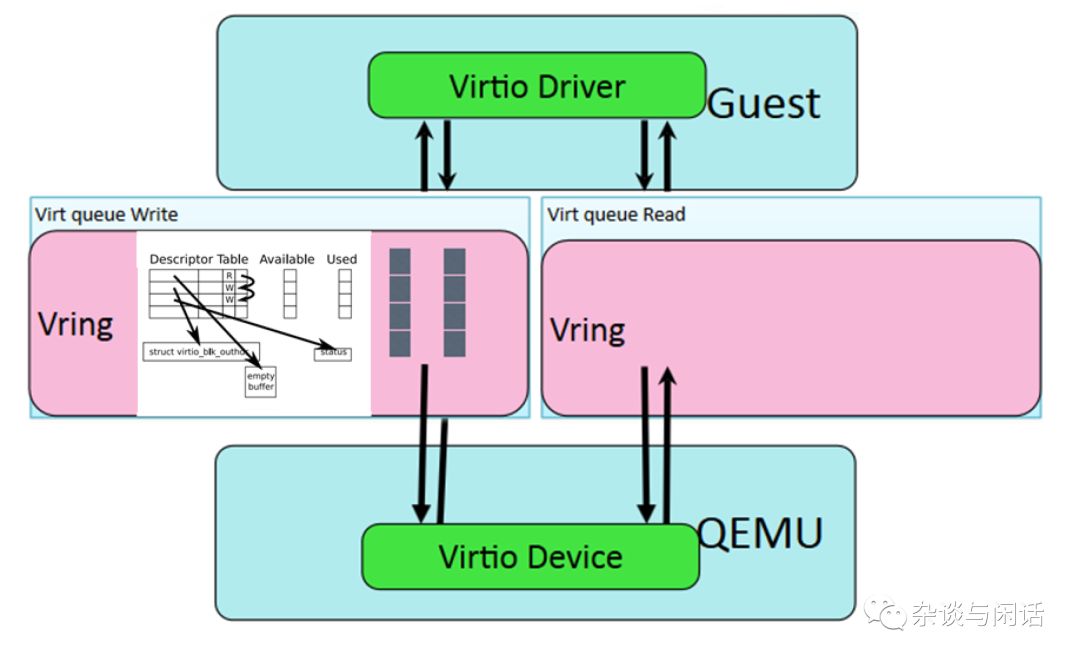
Regarding the interface of Virtio devices, to summarize:
-
Device’s feature bits (which device and guest have to negotiate)
-
Status bits
-
Configuration space (that contains device-specific information, like MAC address)
-
Notification system (configuration changed, buffer available, buffer used)
-
Zero or more Virtqueues
-
Transport-specific interface to the device
Virtio-net on QEMU
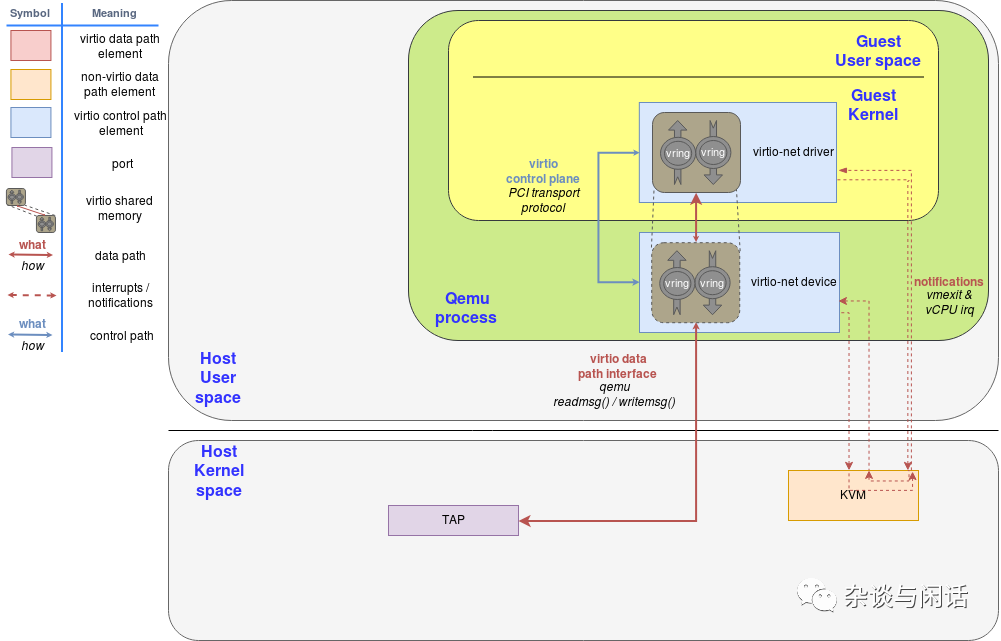
QEMU Virtio sending buffer flow diagram
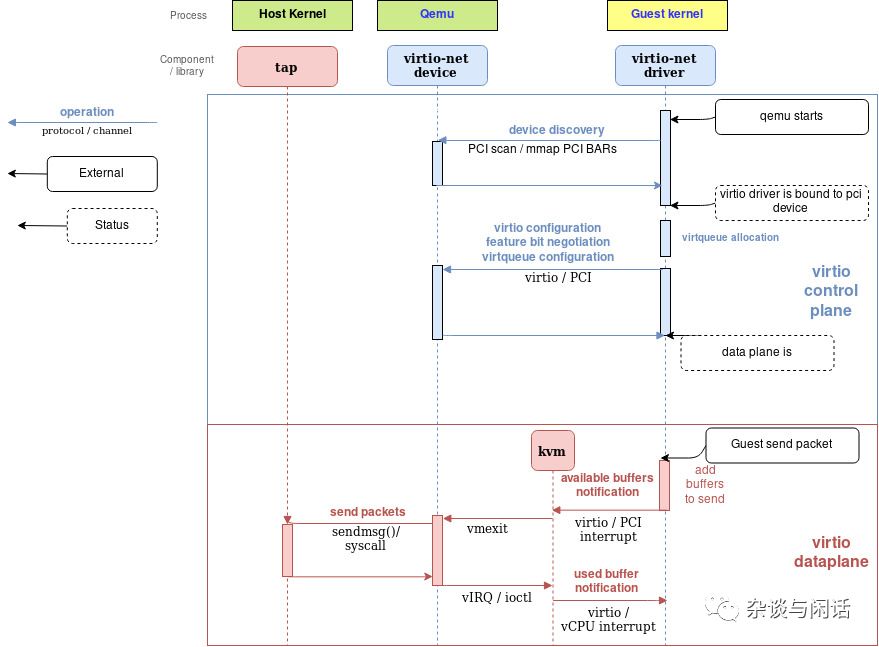
These two diagrams clearly explain the entire process. Points to note are:
1. There are additional Virtqueues that are not on the data path; they are only used to provide communication between the Virtio-net driver and the device. They can provide some control functions, such as advanced filtering, setting the MAC address, and the number of active queues. It should be noted that Virtio devices, like real physical network cards, can provide offloading capabilities, notifying the guest OS as long as the underlying host device implements it.
2. The Virtio buffer, which is the buffer in the Virtqueue, is allocated and mapped to the Virtio device by the Virtio driver. These devices should be in the hypervisor, allowing the hypervisor to access this part of the guest buffer for read and write operations.
Vhost Protocol
In the implementation mechanism of Virtio mentioned above, there are several areas for improvement:
-
When the guest sends an available buffer notification, the vCPU must stop, and control returns to the hypervisor, which requires a context switch.
-
The synchronization mechanism of QEMU’s own tasks/threads.
-
The TAP package does not have a batching mechanism; each package requires a syscall and data copy.
-
Sending available buffer notifications through vCPU interrupts.
-
Additional syscalls are needed to resume the vCPU’s operation.
Vhost is designed to address these issues. The Vhost protocol API is essentially message-based, helping the hypervisor offload data path operations to other mechanisms (handlers) for more efficient completion. Through this protocol, the master can send the following information to other handlers:
-
The memory layout of the hypervisor, allowing other handlers to locate the Virtqueue and buffer positions in the hypervisor’s memory.
-
A pair of file descriptors for sending or receiving notifications according to the Virtio protocol. These file descriptors are shared between KVM and the handler, allowing communication between them to bypass the hypervisor, thus enabling the data path processing to be entirely handled by this handler, which can directly access the memory address space of the Virtqueue and send and receive notifications between guests.
The Vhost message mechanism can use any host-local communication mechanism, such as sockets or character devices, or the hypervisor can use a server/client mechanism.
Next, let’s analyze the implementation of vhost in the kernel, vhost-net.
Vhost-net Kernel Implementation
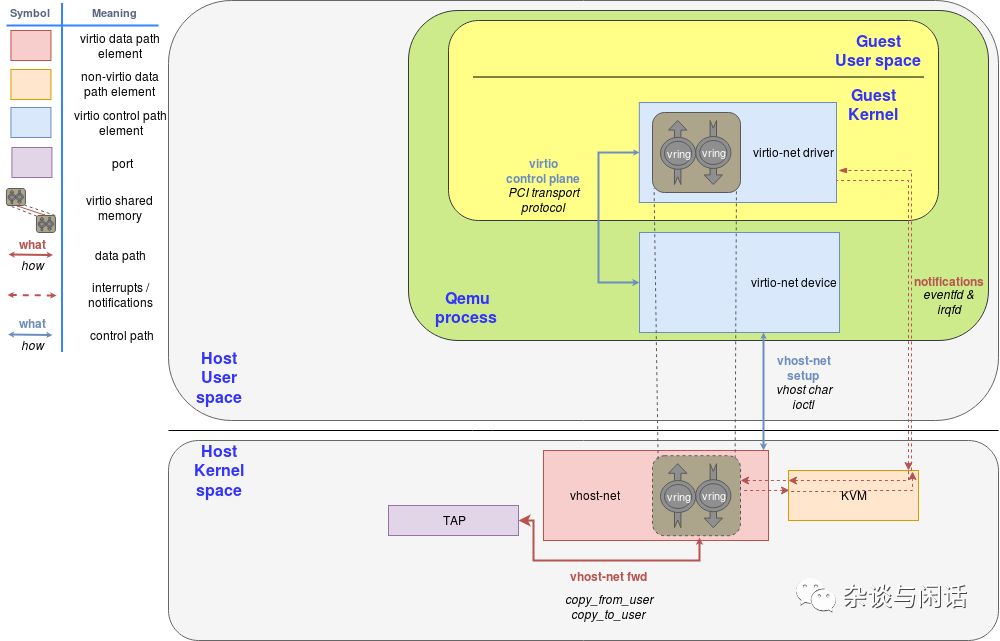
Vhost-net sending buffer diagram flow
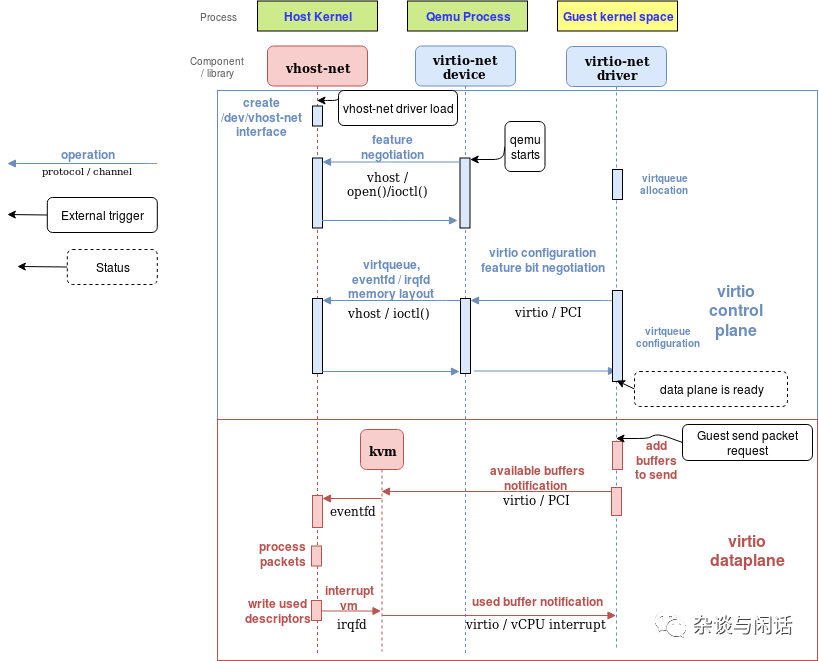
Like the previous diagrams without Vhost, the above two diagrams explain the role of Vhost in reducing context switches on the data path. At the same time:
-
QEMU and the Vhost-net handler exchange Vhost messages through ioctl, using eventfd-based irqfd and ioeventfd for notification processing.
-
After initialization, Vhost creates a vhost-$pid process, where $pid is the hypervisor’s process.
-
QEMU allocates an eventfd and registers it with Vhost and KVM. The vhost-$pid kernel process polls this fd, and when the guest writes to a special location, KVM writes to this fd. This mechanism is called ioeventfd. Thus, a simple read/write operation at a special location in the guest does not wake up the QEMU process but is directly routed to vhost-$pid for processing. The benefit of this operation is that it is based on the fd message mechanism, which does not require the vCPU to stop and wait, thus avoiding vCPU switching.
-
QEMU allocates another eventfd, also registered with Vhost and KVM, to directly insert interrupts into the vCPU, called irqfd. Writing to it allows any process on the host to generate a vCPU interrupt. This also reduces context switching.
As before, use OVS (standard) to add packet routing functionality.
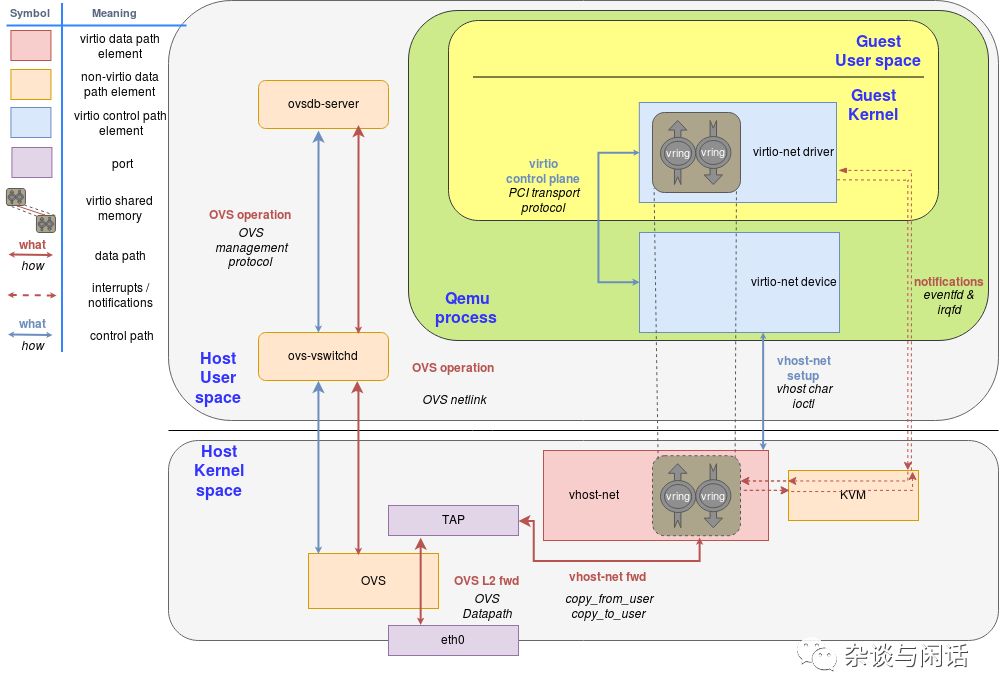
At this point, the Virtio-net/Vhost-net section concludes. It defines an open-source software interface, and the subsequent work mainly focuses on how to enhance its performance. Since 2016, the evolution of the KVM virtualization I/O stack has begun.
Yes, the next section is DPDK.
[1]https://blog.cloudflare.com/how-to-receive-a-million-packets/
[2] https://people.gnome.org/~markmc/qemu-networking.html
[3]https://www.linux-kvm.org/page/Virtio
[4]https://www.linux-kvm.org/page/Multiqueue
[5]https://zhuanlan.zhihu.com/p/40572954
[6]https://medium.com/@jain.sm/network-packet-flow-in-kvm-qemu-dc79db719078
|
High-End WeChat Group Introduction |
|
|
Entrepreneurship Investment Group |
AI, IOT, Chip Founders, Investors, Analysts, Brokers |
|
Flash Memory Group |
Covering over 5000 global Chinese flash memory and storage chip elites |
|
Cloud Computing Group |
All-flash, Software-defined Storage (SDS), Hyper-converged enterprise storage, etc. |
|
AI Chip Group |
Discussion on AI chips and GPU, FPGA, CPU heterogeneous computing |
|
5G Group |
Discussion on IoT, 5G technology, and industry |
|
Third-Generation Semiconductor Group |
Discussion on GaN, SiC, and other compound semiconductors |
|
Storage Chip Group |
Discussion on DRAM, NAND, 3D XPoint, and various storage media and controllers |
|
Automotive Electronics Group |
Discussion on MCU, power supplies, sensors, and other automotive electronics |
|
Optoelectronic Devices Group |
Discussion on optical communication, lasers, ToF, AR, VCSEL, and other optoelectronic devices |
|
Channel Group |
Storage and chip product quotes, market trends, channels, and supply chains |

< Long press to recognize the QR code to add friends >
Join the above group chat
 Long press and follow
Long press and follow
Take you into the era of all things storage, all things intelligent,
All things interconnected flash memory 2.0 era

WeChat ID: SSDFans