Hello everyone, welcome to my column.
In previous articles, we learned about the characteristics, advantages, and implementation details of vector architecture.
Today, let’s take a look at another form of data-level parallelism—SIMD instruction set extensions.
Table of Content
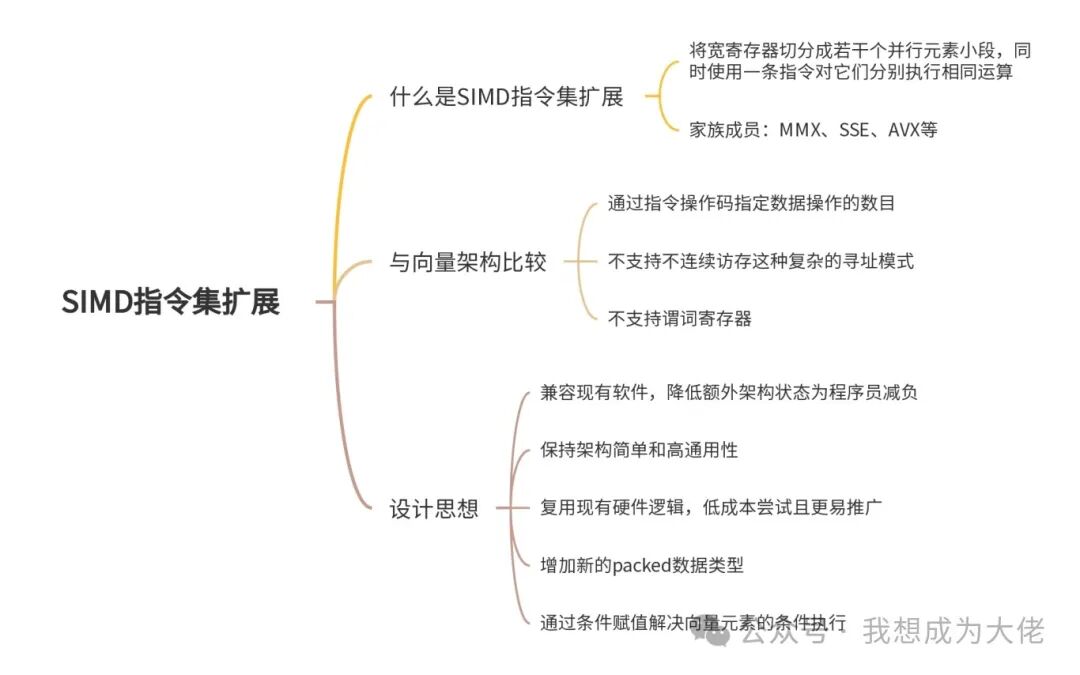
1. What is SIMD Instruction Set Extension
2. Comparison of SIMD Instruction Set Extension and Vector Architecture
3. Design Philosophy of SIMD Instruction Set Extension
Table of Content
Mind Map
 01Birth of SIMD Multimedia Extension Instruction SetBirth
01Birth of SIMD Multimedia Extension Instruction SetBirth
Before designing the SIMD instruction set extension, engineers realized that multimedia applications (image processing, audio and video encoding/decoding, filter calculations, etc.) often handle data that are narrower than 32-bits, such as 8-bits pixel components, 16-bits audio sample values, etc. However, the x86 processors at that time were highly optimized only for 32-bits integer or floating-point operations.
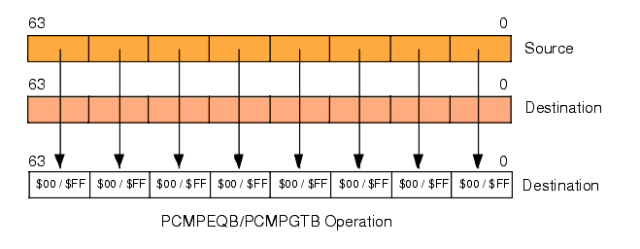
Figure 1 SIMD Instruction Operation
Based on this observation, engineers thought: we cansplit a 64-bits register into several parallel 8-bits or 16-bits segments,and simultaneously perform the same operation on them in a single instruction.
This way, we do not waste register and bus bandwidth, and we can change an instruction that originally could only perform one 64-bits operation to a SIMD operation that processes 8 or 4 smaller data at once, greatly increasing throughput.
Based on the above idea, Intel officially released the MMX instruction set extension in 1996, which was designed to meet the demand for parallel processing of large amounts of “small data” in multimedia (image, audio, video) algorithms. By “trimming” narrower data segments from the original 64-bits register, it can perform parallel operations on multiple data elements, significantly improving throughput.
02Showdown Between SIMD Instruction Set Extension and Vector ArchitectureBurden
In terms of better executing vectorization through compilers, SIMD instruction set extensions have three significant drawbacks compared to vector architecture:
-
Specifying the number of data operations through instruction opcodes, the x86 architecture’s MMX, SSE, and AVX extensions thus added hundreds of instructions; in contrast, RVV uses parameter registers for specification, which avoids the need for a large number of opcodes and easily adapts to different vectorizable programs
-
Does not support more complex addressing modes, such as strided and gather-scatter addressing modes present in vector architecture
-
Does not support predicate registers, making it inefficient to perform conditional execution of elements like vector architecture
These three drawbacks make it more challenging for compilers to use SIMD extension instructions for automatic vectorization.
The design intention of the MMX instruction set includes “not increasing the burden on programmers“, so it is understandable to use opcodes to specify the number of data operations in a way that does not add extra architectural state.
Secondly, the primary goal of the MMX instruction set isto accelerate multimedia processing (image, audio, video), which typically processes continuous, regular data blocks (such as pixel blocks, audio samples). Therefore, simple contiguous memory access can meet most needs efficiently.
Thus, from a demand perspective, adding complex memory operations is clearly not cost-effective, as it may affect cache performance, and simple implementations do not perform well.
After reading the design considerations of the MMX instruction set introduced in the following text, we will have a deeper understanding of the reasons behind these three drawbacks.
Since these drawbacks exist, why is the SIMD instruction set extension still popular?
The most important point is the computer’sbinary backward compatibility requirement, older executable code needs to run unchanged on newer products, which requires newer computer hardware and/or software to have all the functionalities of older versions. This means that once an architecture starts down the SIMD path, it is challenging to deviate from it.
Since the RISC-V instruction set does not have the historical burden of backward compatibility, it has only released what the designers consider to be a superior vector architecture instruction set extension, rather than a SIMD instruction set extension.
At the same time, the SIMD instruction set extension has a more maturesoftware ecosystem, as mainstream software (such as game engines, deep learning frameworks) has deeply relied on SIMD instruction optimizations, making migration costs high.
However, the SIMD instruction set extension still has its own advantages.
⭐ Low Cost + Easy to Implement ⭐
Compared to vector architecture, SIMD instruction set extensions are lower in cost and easier to implement. The reason is that the latter choosesto maximize the reuse of existing CPU hardware.
For example, the MMX instruction set extension reuses existing floating-point registers and computation paths at the hardware level; at the software level, it reuses existing floating-point register save/restore code logic.
This avoids the complexity of needing a completely new design for vector architecture, making it suitable for rapid integration. At the same time, the low cost makes it easier for manufacturers to promote, accelerating market acceptance.
⭐ Less Additional Architectural State ⭐
The MMX instruction set extension can achieveas small a change as possible at the software level. Programmers only need to develop one version of the application, optimizing the data-intensive parts of the program using MMX instructions. Other parts of the software do not require any changes, as the MMX instruction set reuses the existing CPU state.
Although subsequent SIMD instruction set extensions released by Intel, such as SSE and AVX, began to add independent register states, the operations of these new states are concentrated at the operating system level, not violating the original intention of “reducing the burden on programmers”.
⭐Lower Memory Bandwidth Requirements⭐
Compared to vector architecture, the number of elements operated in parallel by SIMD instruction set extension instructions is smaller, that is,the vector length is shorter. This means that the peak performance of computing units is lower, so excessive external memory bandwidth requirements can lead to resource waste.
SIMD instruction set extensions reduce bandwidth requirements, which lowers costs, making them more suitable for desktop computers and servers.
⭐Simplified Handling of Virtual Memory Issues⭐
This advantage benefits from the fact that SIMD instruction set extensions do not support complex memory access patterns. Gather-scatter instructions allow multiple arbitrary address loads/stores, where each element may be located on different pages. In the worst case, each element access of a gather-scatter instruction triggers a page fault, leading to multiple exception handling and context switching, reducing execution efficiency in virtual machine environments.
Early MMX/SSE/AVX instruction extensions required memory address alignment, combined with fixed-size vector access and contiguous address access patterns, mapping a single instruction to multiple data elements within the same page,maximizing the reduction of page fault occurrences.
03Exploring the “Grand View Garden” of SIMD InstructionsFeature
The MMX instruction set, launched in 1996, reuses the low 64-bits of the x87 floating-point registers. MMX instructions can execute 8 parallel 8-bits or 4 parallel 16-bits data operations. The MMX instruction set can also complete memory access using floating-point data transfer instructions.
The SSE instruction set, launched in 1999, adds 16 independent registers of 128-bits width, capable of executing 16 parallel 8-bits, 8 parallel 16-bits, or 4 parallel 32-bits data operations. It also resolves the issue of mixing SIMD instruction set extensions with floating-point instructions. The SSE instruction set also adds separate data transfer instructions.
The AVX instruction set, launched in 2010, expands the register width to 256-bits and adds new instructions for wider vector parallel operations. Subsequent versions of the AVX instruction set began to support gather-scatter instructions, but performance is not as good as contiguous access, especially when cache misses occur..
3.1 The Design Wisdom and Trade-offs Behind the MMX Instruction Set
The emergence of the MMX instruction set was entirely a bottom-up process, driven by thedemand for multimedia, communication, and new internet applications that prompted engineers to explore. The adoption of a certain MMX instruction is predicated on its cost-effectiveness in these areas.
However, the premise for adopting new technology is: it must maintainbackward compatibility with existing software, including operating systems and applications. Adding MMX technology to IA architecture processor systems must be seamless, with no compatibility or negative performance impact on all existing processors.
Similar to the philosophy of vector architecture,the goal is to keep the architecture simple and sufficiently general. Keeping the architecture simple facilitates easy upgrades of microarchitecture process nodes and allows for microarchitecture expansion. Sufficiently general means not providing special support for specific algorithms, avoiding redundant functionality in the future.
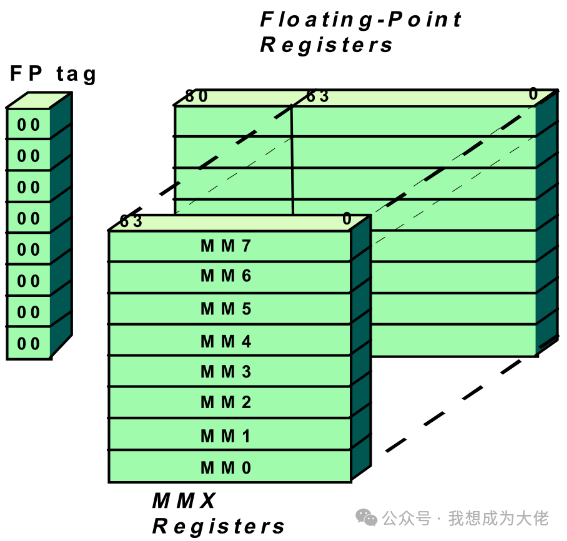
Figure 2 MMX Register
The requirement for compatibility means that MMX instructions use opcodes to specify vector lengths, rather than using additional architectural registers. The key principle is:MMX technology is defined as mapping within the existing IA floating-point architecture registers, as existing operating systems and applications already know how to handle IA floating-point architecture register states.
Reducing the burden on programmers also facilitates application migration, accelerating the promotion of the MMX instruction set extension.
Although floating-point registers are 80-bits, thefloating-point data path is 64-bits, for example, loading and storing units automatically expand or round; execution units also only pass operands in 64-bits as the basic unit, microcode now reads all mantissas in 64-bits, then reads additional exponents and signs in 16-bits, ultimately completing result merging automatically. Therefore,MMX chose a vector width of 64-bits to reuse existing data paths.
The issue of register reuse is:MMX instructions and floating-point instructions cannot be mixed. Inside applications, MMX code and floating-point code need to be encapsulated in different code sequences, resetting the floating-point architecture register state after one sequence is completed before starting the next sequence. Subsequent SIMD instruction set extensions added independent registers to solve this problem.
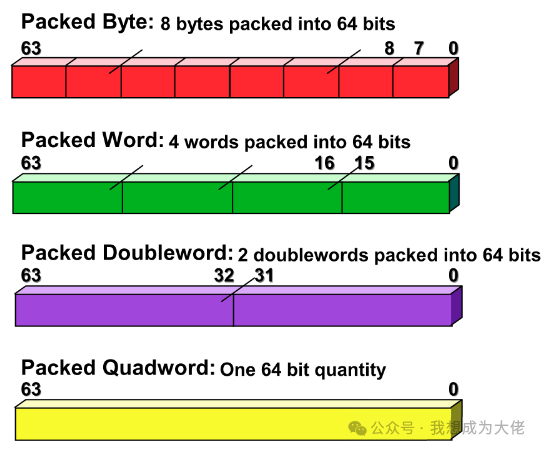
Figure 3 MMX Architecture Data Types
As mentioned at the beginning of this article, the typical operand data width for multimedia applications is small, for which the MMX instruction set defines a new register format for multimedia data representation, known aspacked data format.
It includes four data types: packed byte, packed word, packed doubleword, and packed quadword. They are all packed within a 64-bits register, and each element within the packed data is an independentfixed-point integer, which is consistent with vector architecture.
The architecture does not specify the position of the decimal point within the elements, which needs to be controlled by the user during program execution, dynamically controlling the decimal point position based on different interpretations of the binary.

Figure 4 Example of MMX Processing Conditional Execution
The approach of the MMX instruction set to handle conditional execution is: converting conditional execution intoconditional assignment. The MMX instruction set includes vector comparison instructions, generating masks through vector comparison instructions, which are then used with logical operations to achieve conditional assignment.

Figure 5 Mask Generated by Comparison Operation
In the program example in Figure 4, Rx is the mask generated by the comparison instruction. When the condition is true, all bits of the corresponding elements in Rx are set to 1; otherwise, they are set to 0.
In contrast, the RVV vector architecture uses predicate registers to handle branch execution, designing the v0 register as a hidden predicate register for use with regular computation instructions.
The reason the MMX instruction set did not use this scheme may be that the design goal was to be “good enough”; early attempts typically aimed to achieve multimedia performance improvements at relatively low costs. Adding predicate registers would certainly require new instructions and hardware logic, and the “good enough” solution was readily available.
Thank you for your reading and companionship. This article provides a comprehensive introduction to the design philosophy of SIMD multimedia extension instruction sets, and I hope it is helpful to you. If you have any questions or suggestions, please feel free to leave a comment for discussion.
 Follow me for knowledge sharing every Sunday
Follow me for knowledge sharing every Sunday Previous links:Decoding the Core Technologies Behind the Performance Surge of Vector Processors: A Breakdown of Four Core Data Parallel Optimization TechniquesBreaking Through Instruction-Level Parallelism Bottlenecks, Revealing How Vector Machines Boost Computational Efficiency
Previous links:Decoding the Core Technologies Behind the Performance Surge of Vector Processors: A Breakdown of Four Core Data Parallel Optimization TechniquesBreaking Through Instruction-Level Parallelism Bottlenecks, Revealing How Vector Machines Boost Computational Efficiency