
One of the long-term goals of artificial intelligence is to train a “generalist” model that can simultaneously solve various types of tasks, acting as a versatile general model.
Currently, in the field of AI, the most rapid advancements are seen in subfields such as computer vision, natural language processing, and their intersections. One of the key strategies for progress in these subfields is to achieve optimal performance for a specific task through scaling model size and fine-tuning.
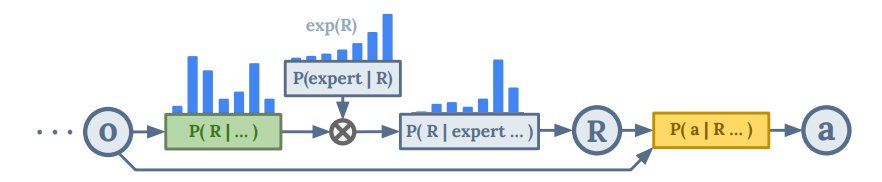
Figure: Explanation of expert-level returns and action decisions (Source: arXiv)
In other words, for large or cross-environment tasks, constructing large-scale models based on transformers through training on large, diverse datasets—even those not directly related to the task—can achieve powerful capabilities. For single tasks or multiple tasks within the same environment, using smaller models can yield similar results to larger models. The success of this strategy in the fields of vision and language raises the question of whether it also applies to reinforcement learning and training for “generalist” models across various environments. To address this question, researchers at Google conducted a study, with the related paper titled “Multi-Game Decision Transformers” published on arXiv [1].

Figure: Related paper (Source: arXiv)
In this paper, the researchers present a fully offline-trained model called Multi-Game Decision Transformers, which is highly versatile and can play 46 different Atari games, achieving performance close to that of humans. During the training and evaluation of the Multi-Game Decision Transformers, the researchers also discovered important experiences and patterns leading towards a “generalist” model. Notably, they found that trends observed in the fields of language and vision also apply to large-scale “generalist” model reinforcement learning, including performance scaling with model size and rapid learning adaptation to new games through fine-tuning. For this training, the researchers chose the Arcade Learning Environment (ALE) as the testing platform, primarily because ALE is designed for empirical evaluation of general capabilities, unlike other well-known deep Q-learning methods that require different hyperparameters for each game.
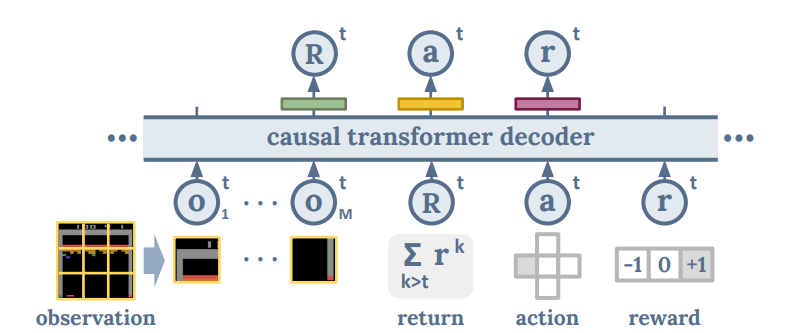
Figure: Multi-Game Decision Transformers model architecture (Source: arXiv)
One important task setting in the model training is to learn to solve multiple tasks in a variety of environments with significantly different dynamics, rewards, and agent implementations; this is quite different from multi-task environments in robotics, where previous multi-task problems were generally in the same or similar environments. In simple terms, the problems and objectives addressed by the Multi-Game Decision Transformers model training are as follows: the system receives an observation of the world Ot at each time interval t and needs to select an action at at each interval. It then receives a scalar reward rt. The training goal is to find the single optimal policy distribution P that maximizes the total return reward Rt.
The training dataset used contains a mix of expert and non-expert behaviors, and to ensure that the generated actions at consistently yield high return rewards, the researchers designed a binary classifier inspired by inference time methods to identify whether expert-level actions are needed at a given time t.
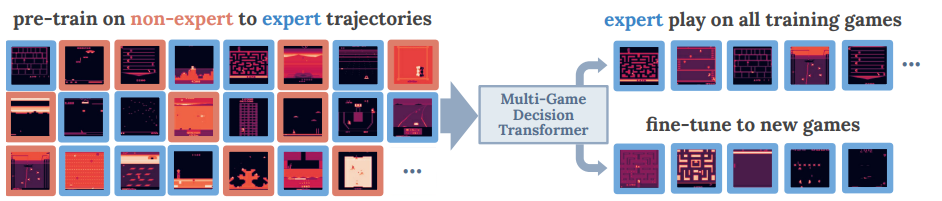 Figure: The training dataset used contains a mix of expert and non-expert behaviors (Source: arXiv) To evaluate the capabilities of the Multi-Game Decision Transformers model, the researchers compared it with other models. The models compared include: the DT model with the target return condition removed, the BC model predicting return tokens; the C51 DQN model that allows classification loss based on minimizing temporal difference; and CQL, CP, BERT, ACL, etc.
Figure: The training dataset used contains a mix of expert and non-expert behaviors (Source: arXiv) To evaluate the capabilities of the Multi-Game Decision Transformers model, the researchers compared it with other models. The models compared include: the DT model with the target return condition removed, the BC model predicting return tokens; the C51 DQN model that allows classification loss based on minimizing temporal difference; and CQL, CP, BERT, ACL, etc.
In terms of model performance variation with size, the Multi-Game Decision Transformers model exhibited a more pronounced empirical power-law relationship. In fact, in natural language processing and computer vision, American computer scientist and entrepreneur Jerry Kaplan and others have demonstrated an empirical power-law relationship between the size of language models and their performance. Moreover, this trend has been validated across models of various sizes, with the number of model parameters ranging from millions to hundreds of billions.
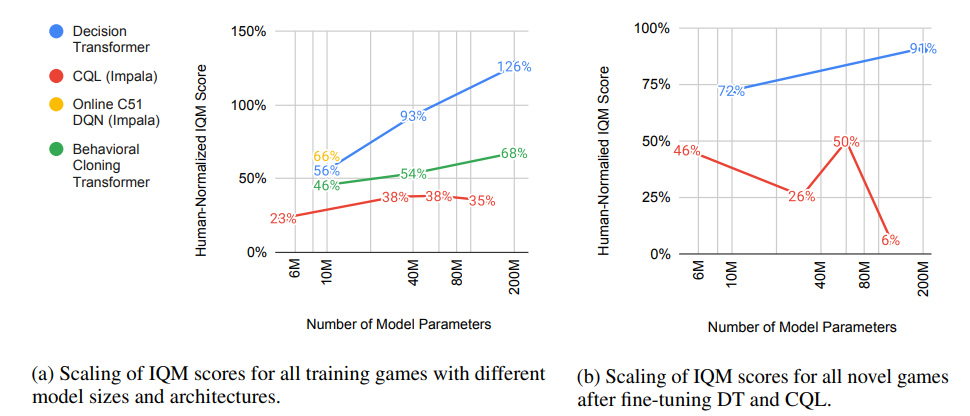 Figure: Performance and fine-tuning performance of Multi-Game Decision Transformer and other models as a function of model size (Source: arXiv) Comparing the performance of the Multi-Game Decision Transformer and other models in Atari games, it can be seen that the performance of this model steadily increases with size, while other models reach saturation and do not increase further after a certain size, and their performance increases much more slowly with model size.
Figure: Performance and fine-tuning performance of Multi-Game Decision Transformer and other models as a function of model size (Source: arXiv) Comparing the performance of the Multi-Game Decision Transformer and other models in Atari games, it can be seen that the performance of this model steadily increases with size, while other models reach saturation and do not increase further after a certain size, and their performance increases much more slowly with model size.
The researchers also evaluated the performance of pre-trained and non-pre-trained Multi-Game Decision Transformer models in fine-tuning. The results showed that the pre-trained DT model performed the best, while the untrained CQL performed the worst.
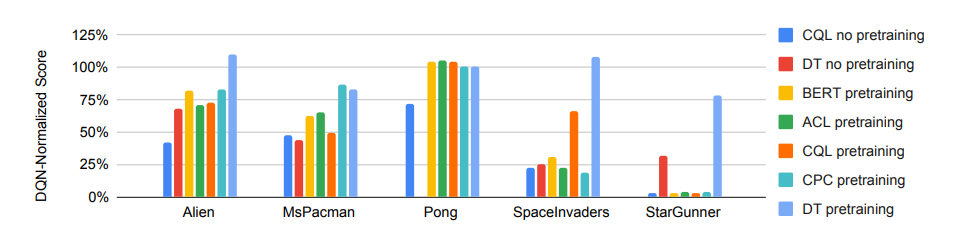 Figure: Performance of pre-trained and non-pre-trained Multi-Game Decision Transformer models compared to other models in fine-tuning (Source: arXiv)
Figure: Performance of pre-trained and non-pre-trained Multi-Game Decision Transformer models compared to other models in fine-tuning (Source: arXiv)
This also validates the researchers’ hypothesis that pre-training indeed helps the model learn new games quickly. Additionally, the team observed that for the DT model, fine-tuning performance correlates with model size, increasing with the model’s growth, while this trend is not consistent for the CQL model.
-End-
References: 1、http://export.arxivarxiv.org/pdf/2205.15241v1
Click the image to read in the Shenghui mini program

Click the image to read in the Shenghui mini program
