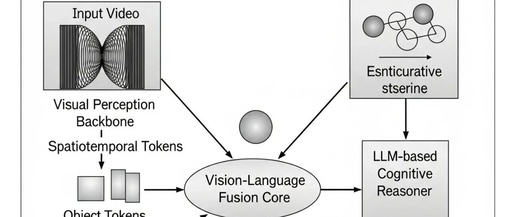
New Applications of LoRA: Dynamic Combination Without Training
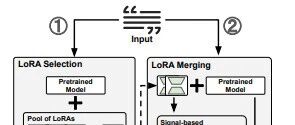
Title: LoRA on the Go: Instance-level Dynamic LoRA Selection and Merging Paper Link: https://arxiv.org/pdf/2511.07129 Innovations For the first time, a combination of Generative Mask and Discriminative Mask is used, where the generative mask is applied to video data reconstruction tasks, and the discriminative mask is used for video understanding tasks. Both share the same network … Read more