With the rise of the Model Context Protocol (MCP) ecosystem, an Assistant may be supported by hundreds of tools/sub-Agents.
- Stuffing all tool descriptions into the Prompt? → Starting at 4,600+ tokens, which is painfully expensive.
- Selecting an Agent before choosing tools? → Coarse-grained descriptions often bury “hidden treasure tools”.
- Using only a single tool? → A set of tools needed for multi-step tasks gets completely disassembled.
The author highlights the pain points with a diagram: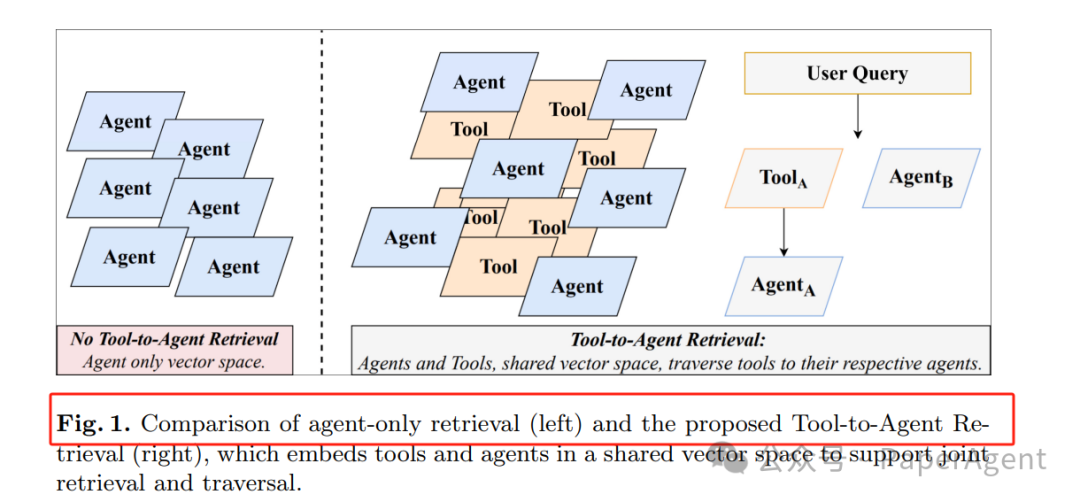
Figure 1: Traditional “Agent-only” retrieval (left) vs. Tool-to-Agent unified retrieval (right)
2. Core Idea: Bringing “Tools” and “Agents” into the Same Vector Space
Tool-to-Agent Retrieval (T2A) = Unified vector indexing + Metadata jumping
- Build a bipartite graph: Agent ↔ Owned tools
- Use the same set of encoders to embed both Agent descriptions & tool descriptions
- During retrieval, first get Top-N (tools + Agents), then map back to the unique Agent set using
<span>owner(·)</span>. - Finally, return Top-K Agents to make the decision of “select tool or select Agent” in a single step
Algorithm pseudocode overview:

Algorithm 1: Combined Tool–Agent Top-K Retrieval
3. Experimental Design: 8 Encoders × 95 Real Tasks × 527 Tools
Dataset: LiveMCPBench
- 70 MCP Servers, 527 tools, 95 multi-turn user Queries
- Each Query manually annotated with 2.68 steps, 2.82 tools, and 1.40 Agents
Comparison Baselines:
- BM25
- Q.Retrieval (dense)
- ScaleMCP (2025 SOTA)
- MCPZero (2025 SOTA)
Evaluation Metrics: Recall@K / mAP@K / nDCG@K, K∈{1,5,10}
4. Results Overview: Comprehensive Improvement in Metrics, Up to +28%
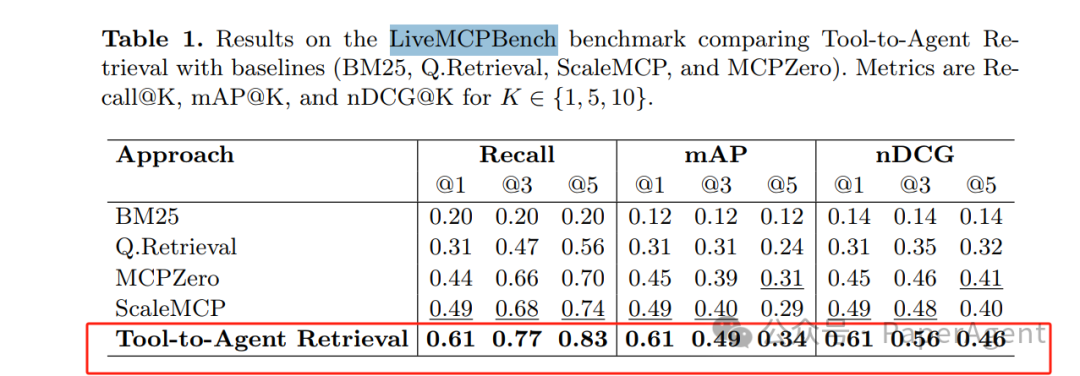 Table 1: Main Metrics of LiveMCPBench
Table 1: Main Metrics of LiveMCPBench
Next, let’s look at the stability of 8 types of embeddings:
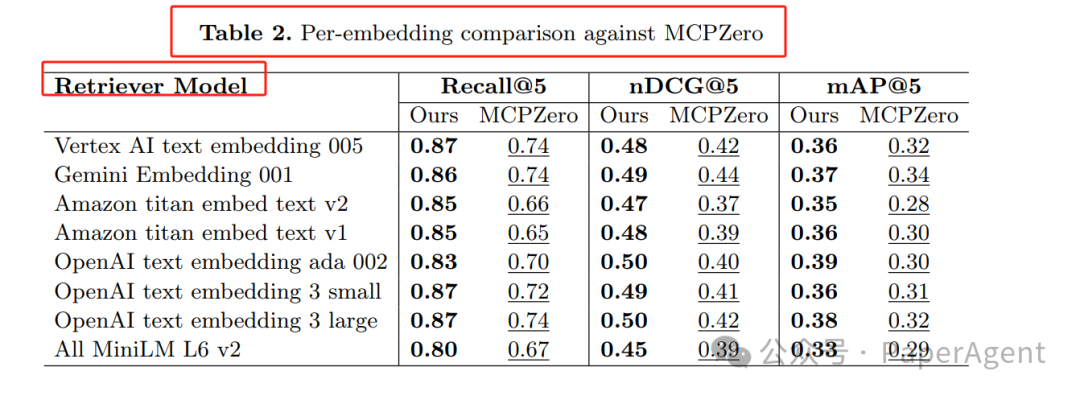
Table 2: Model-by-Model Comparison (Recall@5)
- Amazon Titan v2 shows the most significant improvement: 0.66 → 0.85 (+28%)
- Even the lightweight All-MiniLM-L6 also improved by +13%, indicating that the improvement comes from the framework rather than the large model
5. Ablation Insights: What Does Tool-Level Signal Bring?
-
In the Top-5 returns, **39%** directly hit Agent descriptions, while 34%** are recalled through tool → Agent mapping → proving that “tool details” indeed supplement the semantic omissions of Agent summaries
-
Step-wise Querying (decomposing first and then retrieving step by step) averages an additional +4–6 points in Recall compared to Direct Querying → complex task decomposition retrieval remains effective
https://arxiv.org/pdf/2511.01854
Tool-to-Agent Retrieval: Bridging Tools and Agents for Scalable LLM Multi-Agent SystemsRecommended Reading
Hands-on Design of AI Agents: (orchestration, memory, plugins, workflow, collaboration)
A comprehensive review of 92 pages on Vibe Coding technology for large models
A dark horse emerges in the AI Code track: from ByteDance
A systematic review of the latest self-evolving AI Agents’ new paradigm
One paper on large models every day to exercise our thinking~ If you’ve read this far, feel free to give a thumbs up 👍, ❤️, or share ↗️, and star ⭐ to not get lost!