

Why do Multi-Agent Large Language Model (LLM) systems fail? Recently, the University of California, Berkeley published a significant paper titled “Why Do Multi-Agent LLM Systems Fail?” which delves into the reasons for the failures of Multi-Agent Systems (MAS) and outlines 14 specific failure modes along with corresponding improvement suggestions.
Below is the translation of the paper. Enjoy.
Introduction
Despite the growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to complete tasks, their performance improvements on popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the necessity of analyzing the challenges that hinder the effectiveness of MAS.
In this paper, we conduct a comprehensive study of the challenges faced by MAS for the first time. We analyze five popular MAS frameworks, covering over 150 tasks, involving six expert annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerged iteratively from the consensus among three expert annotators in each study, achieving a Cohen’s Kappa score of 0.88. These granular failure modes are categorized into three types: (i) specification and system design failures, (ii) misalignment among agents, and (iii) task validation and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge.

“Successful systems are all alike; every failed system fails in its own way.” (Berkeley, 2025)
 Recently, agent systems based on large language models (LLM) have garnered widespread attention in the AI community. This growing interest stems from the ability of agent systems to handle complex multi-step tasks while dynamically interacting with different environments, making LLM-based agent systems particularly suitable for solving real-world problems. Based on this characteristic, Multi-Agent Systems have seen increasing exploration across various fields such as software engineering, drug discovery, scientific simulation, and more recently, general agents.
Recently, agent systems based on large language models (LLM) have garnered widespread attention in the AI community. This growing interest stems from the ability of agent systems to handle complex multi-step tasks while dynamically interacting with different environments, making LLM-based agent systems particularly suitable for solving real-world problems. Based on this characteristic, Multi-Agent Systems have seen increasing exploration across various fields such as software engineering, drug discovery, scientific simulation, and more recently, general agents.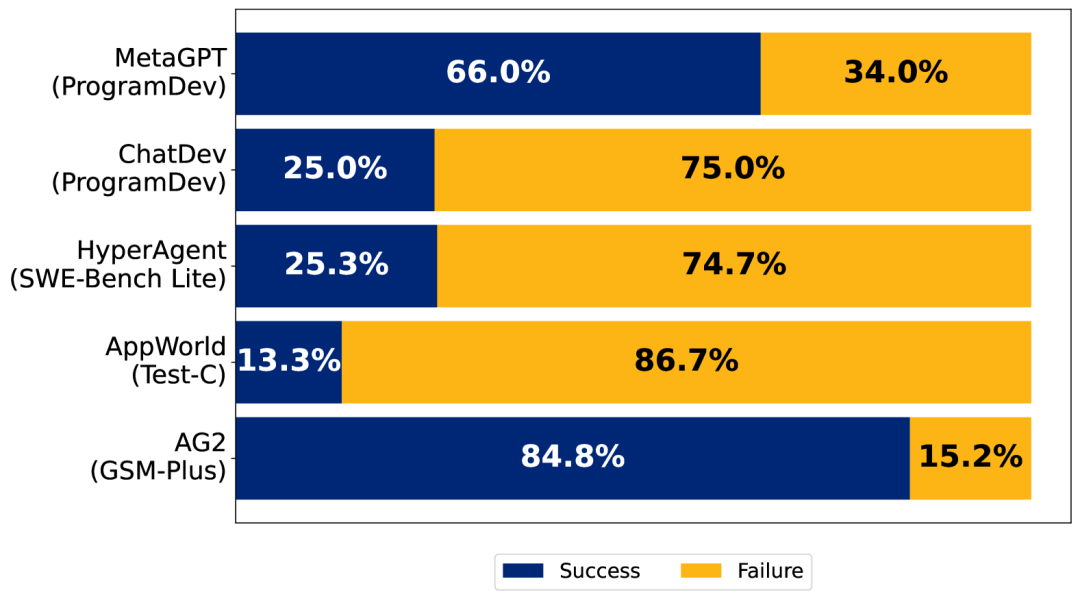 Figure 1:Failure rates of five popular Multi-Agent LLM systems compared to GPT-4o and Claude-3.In this study, we define LLM-based agents as artificial entities capable of interacting with the environment (e.g., tool usage) through prompt specifications (initial state), dialogue tracking (state), and their ability to interact. We then define Multi-Agent Systems (MAS) as a collection of agents designed to interact through orchestration to achieve collective intelligence. The structure of MAS is intended to coordinate efforts, achieve task decomposition, performance parallelization, context isolation, specialized model integration, and diverse reasoning discussions.
Figure 1:Failure rates of five popular Multi-Agent LLM systems compared to GPT-4o and Claude-3.In this study, we define LLM-based agents as artificial entities capable of interacting with the environment (e.g., tool usage) through prompt specifications (initial state), dialogue tracking (state), and their ability to interact. We then define Multi-Agent Systems (MAS) as a collection of agents designed to interact through orchestration to achieve collective intelligence. The structure of MAS is intended to coordinate efforts, achieve task decomposition, performance parallelization, context isolation, specialized model integration, and diverse reasoning discussions.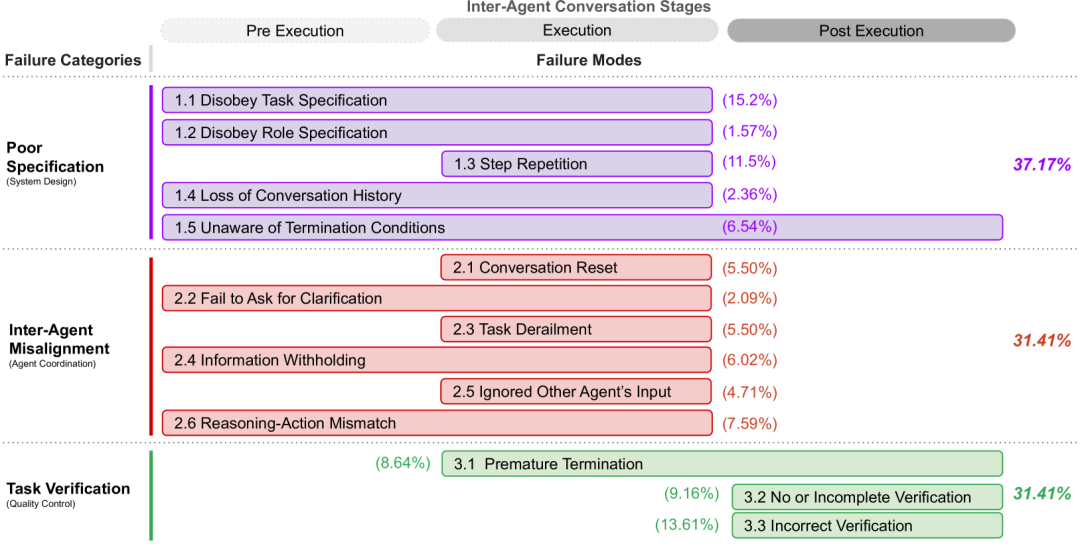 Figure 2: Classification of MAS failure modes.Despite the increasing adoption of MAS, the accuracy or performance improvements compared to single-agent frameworks or simple baselines (e.g., best N sampling in popular benchmarks) remain minimal. Our empirical analysis indicates that the correctness of the state-of-the-art (SOTA) open-source MAS ChatDev may be as low as 25%, as shown in Figure 1. Furthermore, there is currently no clear consensus on how to build robust and reliable MAS. This raises a fundamental question we first need to answer: Why do MAS fail?
Figure 2: Classification of MAS failure modes.Despite the increasing adoption of MAS, the accuracy or performance improvements compared to single-agent frameworks or simple baselines (e.g., best N sampling in popular benchmarks) remain minimal. Our empirical analysis indicates that the correctness of the state-of-the-art (SOTA) open-source MAS ChatDev may be as low as 25%, as shown in Figure 1. Furthermore, there is currently no clear consensus on how to build robust and reliable MAS. This raises a fundamental question we first need to answer: Why do MAS fail?
To understand MAS failure modes, we conducted the first systematic evaluation of MAS execution trajectories using Grounded Theory (GT) (Glaser & Strauss, 1967). We analyzed five popular open-source MAS, employing six expert annotators to identify granular issues within 150 dialogue trajectories, each averaging over 15,000 lines of text. We define a failure as a situation where the MAS fails to achieve the expected task objectives. To ensure consistency in failure modes and definitions, three expert annotators independently labeled 15 trajectories, achieving inter-annotator consistency with a Cohen’s Kappa score of 0.88. Through this comprehensive analysis, we identified 14 distinct failure modes and clustered them into three main failure categories. We introduced the Multi-Agent System Failure Taxonomy (MASFT), which is the first structured failure taxonomy for MAS, as shown in Figure 2. We do not claim that MASFT covers all potential failure modes; rather, it is the first step in classifying and understanding MAS failures.
To achieve scalable automated evaluation, we introduced the LLM-as-a-judge process using OpenAI’s o1. To validate this process, we cross-validated it with three human expert annotators on 10 trajectories, ultimately achieving a Cohen’s Kappa consistency rate of 0.77.
Intuitively, better specifications and prompt strategies may alleviate MAS failures. To test this hypothesis, we implemented interventions using prompt engineering and enhanced agent topology orchestration. Our case studies on AG2 and ChatDev indicate that while these interventions brought a +14% improvement to ChatDev, they did not resolve all failure scenarios. Moreover, the improved performance remains insufficient for practical deployment.
These findings suggest that the identified failures require more complex solutions, providing a clear roadmap for future research. We have open-sourced our dataset and LLM interpreter.
“All successful systems are alike; each failed system fails in its own way.” (Berkeley, 2025)
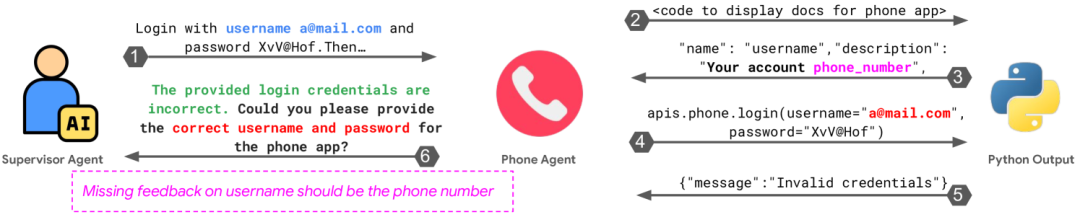 Figure 3: Workflow for studying MAS, including identifying failure modes, developing taxonomies, and iteratively refining through inter-annotator consistency studies, achieving a Cohen’s Kappa score of 0.88.
Figure 3: Workflow for studying MAS, including identifying failure modes, developing taxonomies, and iteratively refining through inter-annotator consistency studies, achieving a Cohen’s Kappa score of 0.88.
This section describes our method for identifying the main failure modes in MAS and establishing a structured classification of failure modes. Figure 3 outlines this workflow.
To systematically and impartially discover failure modes, we employed the Grounded Theory (GT) methodology, a qualitative research method that builds theory directly from empirical data rather than testing predefined hypotheses. The inductive nature of GT allows for the organic emergence of failure mode identification. We collected and analyzed MAS execution trajectories through theoretical sampling, open coding, constant comparative analysis, memoing, and theoretical iteration.
After obtaining MAS trajectories and discussing preliminary findings, we derived an initial taxonomy from the observed failure modes. To refine the taxonomy, we conducted inter-annotator consistency studies, iteratively adjusting failure modes and categories by adding, deleting, merging, splitting, or modifying definitions until consensus was reached. This process reflects a learning approach, where the taxonomy is continuously refined until stability is achieved, measured through inter-annotator consistency via Cohen’s Kappa score. Additionally, to enable automated failure identification, we developed an LLM-based annotator and validated its reliability.
Data Collection and Analysis
We employed theoretical sampling to ensure the diversity of identified MAS and the task set (MAS execution trajectories) to collect data. This method guided the selection of MAS based on their objectives, organizational structures, implementation methods, and variations in underlying agent roles. For each MAS, the selected tasks represented the system’s expected capabilities rather than artificially challenging scenarios. For example, if the system reported performance on a specific benchmark or dataset, we directly selected tasks from those benchmarks. The analyzed MAS covered multiple domains and contexts, as described in Table 1 and Appendix B. After collecting MAS trajectories, we applied open coding to analyze the traces of agent-agent and agent-environment interactions. Open coding breaks qualitative data into labeled segments, allowing annotators to create new codes and memo observations, facilitating iterative reflection and collaboration among annotators. Specifically, annotators identified the failure modes they encountered and systematically compared their newly created codes with existing codes, a process also known as constant comparative analysis in GT. This iterative process of failure mode identification and open coding continued until we reached theoretical saturation, the point at which no new insights emerged from additional data. Through this process, annotators labeled over 150 traces across five MAS. Next, we grouped related open codes to reveal granular failure modes in the initial version of MASFT. Finally, we linked failure modes to form a classification of error categories, as shown in Figure 2. This process is represented in Figure 3 by points 1 and 2. After proposing the initial taxonomy, a critical question arose regarding the reliability of the taxonomy and how we could find an automated method to evaluate MAS failures. To address this, we conducted inter-annotator consistency studies, where three annotators aimed to validate, improve, and finalize the initially derived taxonomy.
Inter-Annotator Consistency Studies and Iterative Improvements
Inter-annotator studies primarily focus on validating a given test or scoring criterion, so that when multiple different annotators evaluate the same set of test cases based on the same scoring criteria, they should arrive at the same conclusions. Although we initially derived a taxonomy based on the theoretical sampling and open coding explained in the previous section, it was still necessary to validate the unambiguity of the taxonomy.
For inter-annotator consistency, we conducted three main rounds of discussion based on the initially derived taxonomy. In the first round, we sampled five different MAS trajectories from the 150+ trajectories obtained from theoretical sampling, and the three annotators evaluated these trajectories using the failure modes and definitions from the initial taxonomy. We observed that the consistency achieved by the annotators in the first round was very weak, with a Cohen’s Kappa score of 0.24. Subsequently, these annotators improved the taxonomy. This involved iteratively changing the taxonomy until we reached consensus on whether each failure mode existed in a certain failure mode and whether it was present in all five collected trajectories. During the iterative improvements, we modified the definitions of failure modes as needed, breaking them down into multiple granular failure modes, merging different failure modes into a new failure mode, adding new failure modes, or removing failure modes from the taxonomy.
This process can be likened to a learning study, where different agents (this time human annotators) independently collect observations from a shared state space and share their findings to reach consensus. Furthermore, to avoid the fallacy of using training data as test data, when we refined the study at the end of the first round, we tested the new inter-annotator consistency and taxonomy performance on another set of trajectories in the second round. In the next phase (the second round), we sampled another set of five trajectories, each from a different MAS. The annotators achieved good consistency on the first attempt, with an average Cohen’s Kappa score of 0.92. Inspired by this, we entered the third round, where we sampled another set of five trajectories and again used the same final taxonomy for annotators, achieving an average Cohen’s Kappa score of 0.84. Note that Cohen’s Kappa scores above 0.8 are considered strong, and above 0.9 are considered nearly perfect alignment.
Inspired by the reliability of the taxonomy, we posed the following question: Can we devise an automated method to annotate trajectories so that developers or users can use this automated pipeline alongside our taxonomy to understand the reasons for their model failures? Therefore, we developed an automated MASFT annotator using the LLM-as-a-judge pipeline, which we will describe in Section 3.3.
LLM Annotator
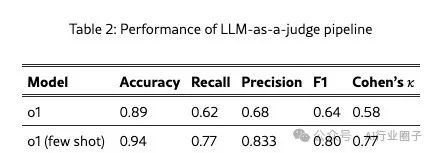
After developing our MASFT taxonomy and completing the inter-annotator consistency studies, our goal was to devise an automated method to use our taxonomy to discover and diagnose failure modes in MAS trajectories. To this end, we developed an LLM-as-a-judge pipeline. In this strategy, we provide the LLM with a system prompt that includes the failure modes from our MASFT, their detailed explanations, and some examples of these failure modes. In this strategy, we decided to use OpenAI’s o1 model and tested both scenarios of not providing the aforementioned examples and providing examples. Based on the results of the third round of inter-annotator consistency studies mentioned in Section 3.2, we tested the success of the LLM annotator, as shown in Table 2. Achieving a 94% accuracy rate and a 77% Cohen’s Kappa value, we consider the LLM annotator (with contextual examples) to be a reliable annotator. Inspired by this result, we had the LLM annotator label the remaining traces in our collected 150+ trace corpus, with results shown in Figure 4, and the final taxonomy with the distribution of failure modes as shown in Figure 2.
Research Results
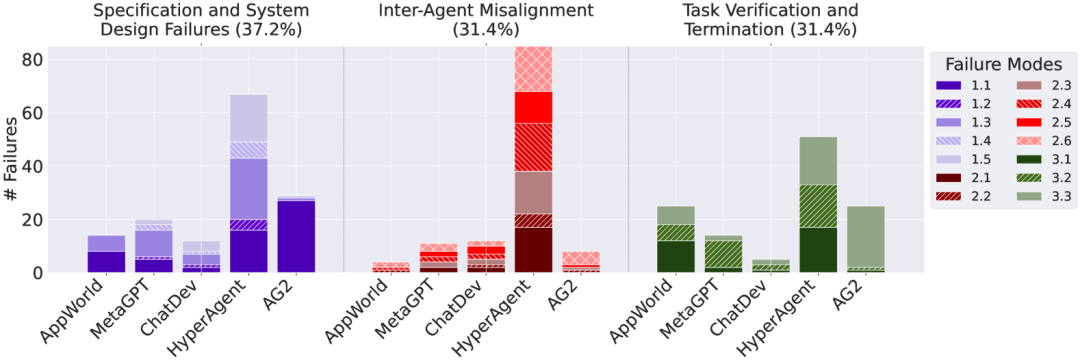
Figure 4:Distribution of failure modes by category and system.
Our grounded theory research and inter-annotator consistency studies conducted on a range of different MAS contributed to the development of MASFT, as shown in Figure 2. MASFT organizes three overall failure categories, identifying 14 granular failure modes that MAS may encounter during execution. MASFT also divides MAS execution into three stages related to agents: pre-execution, execution, and post-execution, identifying the MAS execution stage at which each granular failure mode may occur.
FC1. Specification and system design failures. Failures due to defects in system architecture design, poor dialogue management, unclear or violated task specifications, and insufficient definition or adherence to agent roles and responsibilities often lead to task failures in MAS. However, even when clear specifications are provided, MAS may still be inconsistent with user inputs. One example of such failure is violating task specifications. When asked to design a two-player chess game with classic chess move notation (e.g., “Ke8”, “Qd4”) as input, the MAS framework ChatDev generates a game that uses (x1, y1), (x2, y2) as input, which represent the initial coordinates of the pieces on the board and the final coordinates of the pieces, thus failing to meet the initial requirement. Another failure mode of this type is non-compliance with role specifications. For instance, during the requirements analysis phase of ChatDev, the CPO agent occasionally assumes the role of CEO by unilaterally defining the product vision and making final decisions.FC2. Misalignment among agents. Failures due to poor communication, ineffective collaboration, conflicting behaviors among agents, and gradually deviating from the initial task.Figure 5:Telephone agent failed to communicate API specifications and login username requirements to the supervisor. On the other end of the dialogue, the supervisor agent also failed to clarify the login details. After several back-and-forth attempts, the supervisor agent marked the task as failed.Multi-Agent Systems often suffer from inefficient dialogue issues, where agents engage in ineffective communication, consuming computational resources without making meaningful progress. For example, in the ChatDev tracking involving the creation of a Wordle-like game, the programmer agent interacted with multiple roles (CTO, CCO, etc.) over seven cycles but failed to update the initial code. The resulting game is playable but lacks robustness, with only five simple words, undermining replayability and leading to wasted additional communication rounds. Another failure mode in this category is agents withholding valuable information. For instance, in Figure 5, the supervisor agent instructs the telephone agent to use an email ID as the username to retrieve contact information. The telephone agent, after reading the documentation and discovering that the correct username should be a phone number, continues to operate with incorrect credentials, leading to an error.FC3. Task validation and termination. Failures due to premature termination of execution and a lack of sufficient mechanisms to ensure the accuracy, completeness, and reliability of interactions, decisions, and outcomes.MAS may not have undergone specialized validation steps during development, or may include validation agents that cannot effectively execute their tasks. For example, in the ChatDev scenario involving the implementation of a chess game, the validation agent only checks whether the code compiles, without running the program or ensuring compliance with chess rules. Chess is a mature game with extensive specifications, rules, and implementations readily available online. Even simple retrieval should intuitively prevent trivial failures, such as accepting incorrectly formatted inputs. However, without proper validation, defects such as invalid input handling or format errors in interfaces persist, rendering the game unplayable.
Figure 4 illustrates the distribution of granular failure modes and failure categories in the studied MAS. Different colors represent different failure categories in MASFT, while different shades represent various granular failure modes within the categories. We emphasize that no single error category dominates, indicating the diversity of failure occurrences and the robustness of the taxonomy used for classification. Additionally, we note that, as expected, different MAS exhibit different distributions of failure categories and modes. For example, compared to specification and validation issues, AG2 has fewer instances of misalignment among agents, while ChatDev encounters fewer validation issues than specification and misalignment challenges. These differences stem from varying problem settings, which affect system topology design, communication protocols, and interaction management. In turn, these factors shape systems with their own strengths and weaknesses.
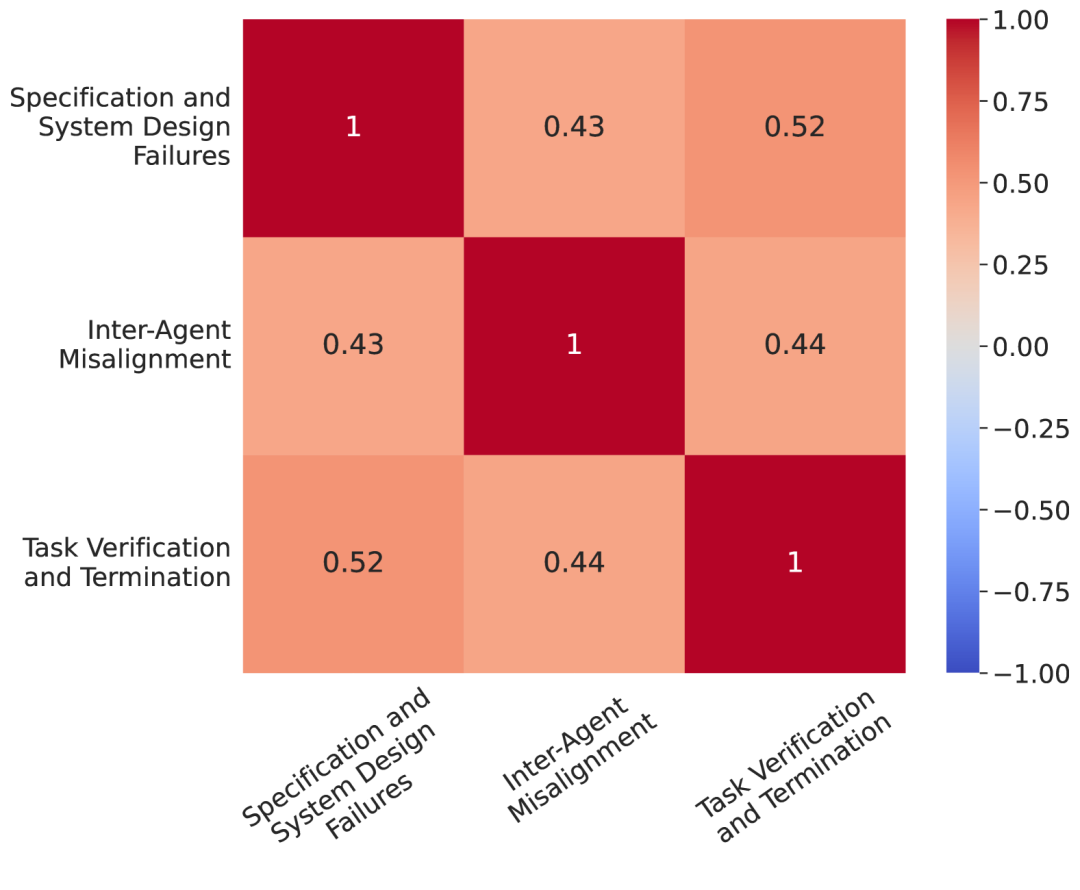
Figure 6:Correlation matrix of MAS failure categories.
Figure 6 highlights the correlations between different failure categories in MASFT. The observed correlations are not particularly strong, indicating that the proposed taxonomy is a reasonable classification framework. Furthermore, this suggests that failures are not isolated events; rather, they may have cascading effects that can impact other failure categories.
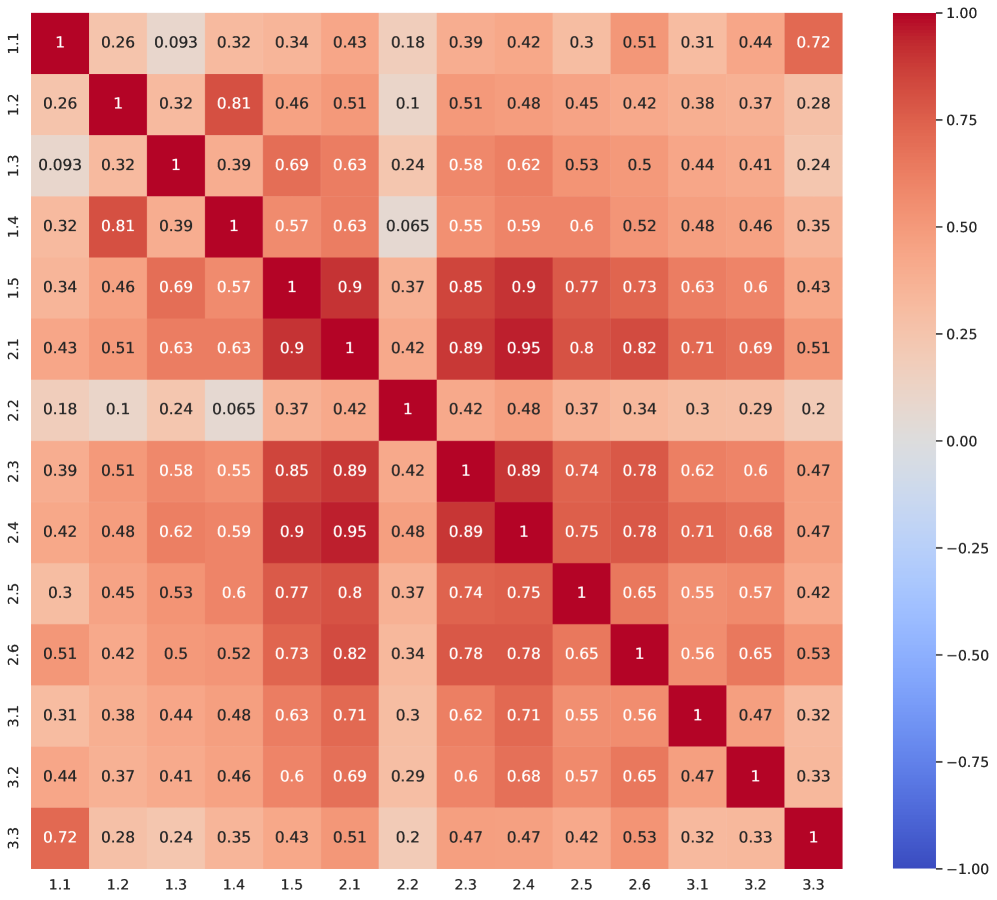
Are All Failures the Validator’s Fault?
We have identified a range of failure modes in MAS. However, it can be argued that ultimately, each failure may stem from a lack of proper validation or incorrect validation processes. If we assume that the validation agent functions perfectly, then all failures are detectable and thus avoidable.
In our study, we focused on validation issues in situations where the system could effectively benefit from the results of the validation process. However, we also examined other failure modes that occurred prior to the final validation step. In many cases, we can view validation as the last line of defense against failures. This leads us to conclude that while many issues can indeed be traced back to insufficient validation, not every problem can be entirely attributed to this factor. Other factors, such as poor specifications, inadequate design, and inefficient communication, can also lead to failures. Therefore, a comprehensive approach to understanding and addressing MAS failures must consider a broader range of factors beyond just validation defects.
MASFT Failure Modes Violate HRO Defining Characteristics
While we encountered some common LLM failure modes, such as text repetition, we excluded them from MASFT as these issues are not specifically related to MAS and may even occur in single LLM invocation pipelines. On the other hand, we found evidence that MAS faces issues similar to those in complex human organizations, as the failure modes align with common failure modes observed in human organizations. Roberts & Rousseau (1989) identified eight key characteristics shared by High-Reliability Organizations (HRO). The MASFT discovered through GT contains no prior biases, including several failure modes related to the unique characteristics identified by Roberts & Rousseau. Specifically, “FM1.2: Non-compliance with role specifications” violates the HRO characteristic of “extreme hierarchical differentiation.” Similarly, “FM2.2: Failure to request clarification” undermines “respect for expertise.” The failure modes identified in MASFT directly violate HRO characteristics, validating the applicability of MASFT and the need for non-trivial interventions inspired by HRO. For example, to prevent the occurrence of “FM1.2: Non-compliance with role specifications” in MAS, orchestration and role assignment can enforce hierarchical differentiation.
Towards Better Multi-Agent LLM Systems
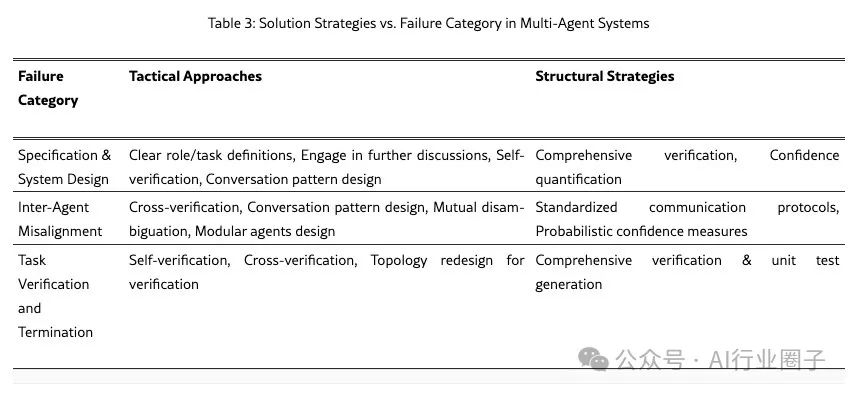
In this section, we discuss several strategies to make MAS more resilient to failures. We categorize these strategies into two main types: (i) tactical approaches and (ii) structural strategies. Tactical approaches involve direct modifications tailored to specific failure modes, such as improving prompts, agent network topology, and dialogue management. In Section 6, we experiment with these methods in two case studies and demonstrate that the effectiveness of these methods is inconsistent. This prompts us to consider the second category of strategies, which are more comprehensive approaches with system-wide impacts: strong validation, enhanced communication protocols, uncertainty quantification, and memory and state management. These strategies require deeper research and careful implementation and remain open research topics for future exploration. Table 3 outlines the mapping of the different solution strategies we propose to the failure categories.
Tactical Approaches
This category includes strategies related to improving prompts and optimizing agent organization and interactions. The prompts for MAS agents should provide clear descriptions of instructions and explicitly specify the role of each agent. Prompts can also clarify roles and tasks while encouraging proactive dialogue. If inconsistencies arise, agents can re-engage or retry, as illustrated in the following prompt:
Prompt: Your role is to critically evaluate the solutions proposed by other agents step by step and provide a final solution. 1. **Solution Requirements**: Before making any decisions, ensure you have received solutions from the agent code executor and the agent problem solver. If any suggested solutions are missing, do not draw any conclusions; instead, suggest the next speaker, stating: Suggested next speaker: _suggested agent name_. 2. **Avoid Assumptions**: Pay attention to the variables provided in the original problem statement versus the variables assumed by the agent. **Assumed values are invalid for the solution** and may lead to inaccuracies. Never base your solutions on assumed values; always base them on clearly given variables to ensure correctness. If the problem cannot be solved due to a lack of information, return: **SOLUTION_FOUND \ boxed { ' None ' }**. 3. **Evaluate Conflicting Solutions**: If different answers arise during the discussion, choose the most appropriate solution based on your evidence or engage in further discussion to clarify. 4. **Final Solution Statement**: When you are confident in the final solution, return it as follows: **SOLUTION_FOUND \ boxed { _solution_value_here_ }**. Ensure that only the value is placed in \ boxed { }; any accompanying text should be outside.Another set of cross-validation strategies includes multiple LLM calls and majority voting or resampling until validation is complete. However, these seemingly simple solutions often prove inconsistent, echoing the results of our case studies. This emphasizes the need for more robust structural strategies, as discussed in the next section.
Structural Strategies
In addition to the tactical approaches discussed above, more complex solutions are needed to shape the MAS structure at hand. We first observe the critical role of the validation process and validation agents in multi-agent systems. Our annotators indicate that weak or insufficient validation mechanisms are significant contributors to system failures. While unit test generation aids validation in software engineering, creating a universal validation mechanism remains challenging. Even in coding, covering all edge cases is complex, even for experts. Validation varies by domain: coding requires comprehensive test coverage, QA requires certified data checks, and reasoning benefits from symbolic validation. Cross-domain adaptation of validation remains an ongoing research challenge.
A complementary strategy to validation is to establish standardized communication protocols. LLM-based agents primarily communicate through unstructured text, leading to ambiguity. Clearly defining intents and parameters can enhance consistency and facilitate formal consistency checks during and after interactions. The introduction of multi-agent graph attention mechanisms leverages graph attention to simulate agent interactions and enhance coordination. Similarly, attention communication allows agents to selectively focus on relevant information. Additionally, developing a learning selective communication protocol can improve collaborative efficiency.
Another important research direction is to fine-tune MAS agents using reinforcement learning. Agents can be trained with role-specific algorithms that reward task-consistent actions and penalize inefficient behaviors. MAPPO optimizes agents’ adherence to defined roles. Similarly, SHPPO uses latent networks to learn strategies before applying heterogeneous decision layers. Optima further enhances communication efficiency and task effectiveness through iterative reinforcement learning.
On the other hand, incorporating probability confidence measures into agent interactions can significantly improve decision-making and communication reliability. Drawing inspiration from the framework proposed by Horvitz et al., agents can be designed to act only when their confidence exceeds a predefined threshold. Conversely, when confidence is low, agents can pause to gather more information. Additionally, systems can benefit from adaptive thresholds, where confidence thresholds are dynamically adjusted.
While memory and state management are often viewed as single-agent attributes, they are crucial for multi-agent interactions, enhancing contextual understanding and reducing ambiguity in communication. However, most research has focused on single-agent systems. MemGPT introduces context management inspired by operating systems to extend context windows, while TapeAgents use structured, replayable logs (“tapes”) to iteratively record and improve agent operations, facilitating dynamic task decomposition and continuous improvement.
Case Studies
In this section, we present two case studies applying some tactical approaches.
Case Study 1: AG2 – MathChat
In this case study, we implement the MathChat scenario in AG2 as our baseline, where a student agent collaborates with an assistant agent capable of executing Python code to solve problems. For benchmarking, we randomly selected 200 exercises from the GSM-Plus dataset, an enhanced version of GSM8K, and added various adversarial perturbations. The first strategy was to improve the original prompt, making its structure clear and adding a dedicated section for validation. Detailed prompts are provided in Appendices E.1 and E.2. The second strategy was to refine the agent configuration into a more specialized system with three distinct roles: problem solver, who solves problems using a thought chain approach without using tools; coder, who writes and executes Python code to arrive at the final answer; and validator, who reviews discussions and critically evaluates solutions, either confirming answers or prompting further debate. In this case, only the validator can terminate the dialogue after a solution is found. To evaluate the effectiveness of these strategies, we conducted benchmarking experiments using two different LLMs (GPT-4 and GPT-4o) across three configurations (baseline, improved prompts, and new topology). We also performed six repeated experiments to assess the consistency of the results. Table 4 summarizes the results.
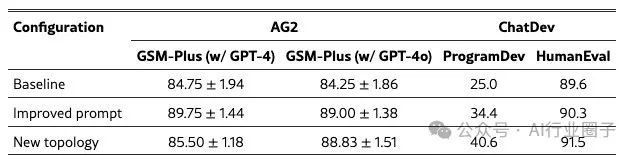 Table 4: Accuracy comparison of case studies. Under AG2, results for GSM-Plus using GPT-4 and GPT-4o; under ChatDev, results for ProgramDev and HumanEval.
Table 4: Accuracy comparison of case studies. Under AG2, results for GSM-Plus using GPT-4 and GPT-4o; under ChatDev, results for ProgramDev and HumanEval.
The second column of Table 4 shows that using GPT-4, the validated improved prompts significantly outperformed the baseline. However, the new topology did not yield the same improvement. The p-value from the Wilcoxon test was 0.4, indicating that the slight improvement was not statistically significant. For GPT-4o (the third column of Table 4), the p-value from the Wilcoxon test when comparing the baseline with the improved prompts and new topology was 0.03, indicating a statistically significant improvement. These results suggest that optimizing prompts and clearly defining agent roles can reduce failures. However, these strategies are not universal, and their effectiveness may vary depending on factors such as the underlying LLM.
Case Study 2: ChatDev
ChatDev simulates a multi-agent software company where different agents have different role specifications, such as CEO, CTO, software engineers, and reviewers, who attempt to collaboratively solve software generation tasks. To address the challenges we frequently observed in tracking, we implemented two different interventions. Our first solution was to improve role-specific prompts to enforce hierarchy and role compliance. For example, we observed instances where the CPO prematurely ended discussions with the CEO without fully resolving constraints. To prevent this, we ensured that only senior agents could complete the dialogue. Additionally, we enhanced the validator role specifications to focus on task-specific edge cases. Detailed information about these interventions is located in Section F. The second solution attempted a fundamental change to the framework topology. We modified the framework’s topology from a directed acyclic graph (DAG) to a cyclic graph. Now, the process only terminates when the CTO agent confirms that all comments have been adequately addressed, with a maximum iteration cutoff to prevent infinite loops. This approach allows for iterative refinement and more comprehensive quality assurance. We tested our interventions in two different benchmarks. The first was a custom-generated set of 32 different tasks (which we call ProgramDev), where we asked the framework to generate various programs, from “write me a two-player chess game to play in the terminal” to “write me a BMI calculator.” The second benchmark was OpenAI’s HumanEval task. We report our results in Table 4. Note that while our interventions successfully improved the framework’s performance across different tasks, they did not yield substantial improvements, necessitating the more comprehensive solutions outlined in Section 5.2.
Conclusion
In this study, we systematically investigated the failure modes of LLM-based Multi-Agent Systems for the first time. Guided by GT theory, we collected and analyzed over 150 trajectories and iteratively refined our taxonomy through inter-annotator studies. We identified 14 granular failure modes and categorized them into three different failure categories, providing a standard for future MAS research. We also proposed an LLM annotator as an automated method for analyzing MAS trajectories and demonstrated its effectiveness and reliability. We discussed two sets of solutions for all failure categories, namely tactical and structural strategies. After conducting case studies on some tactical strategies, our findings indicate that many of these “obvious” fixes have significant limitations, necessitating the structural strategies we outlined to achieve more consistent improvements.
Original link:https://arxiv.org/html/2503.13657v1

-
Analyzing methods and strategies for the DeepSeek reasoning model
-
Detailed training steps for DeepSeek R1 and R1-Zero
-
The future of reasoning model Scaling Law from Deepseek R1
-
OpenAI O3 paper “Emergence” from self-validation and adaptive reasoning capabilities, surprisingly winning an international Olympic gold medal
-
Docker’s competitive leap: Running LLM large models with one-click localization through Container
-
If the model is the product, many AI companies are doomed to fail
-
The Moore’s Law of AI Agent autonomy, doubling every 7 months
-
OpenAI exposed PhD-level AI agents at $20,000/month, expected to replace university professors
-
Google releases Co-scientist: Multi-Agent AI systems accelerating scientific breakthroughs
-
60 images to easily understand large language model AI Agents
-
Six elements of AI Agent engineering
-
Anthropic drives the “Manus” craze, with monthly revenue soaring 40% to $115 million
-
A16z releases AI product traffic and revenue rankings: A major shift in the AI landscape
-
CB Insights deep report: Market map of over 170 AI Agent startups