With the development of AI intelligence, many chips more suitable for AI learning have been introduced following traditional CPUs and GPUs. This article introduces how to develop NPU chips based on the SDK provided by the RK platform.
1. Introduction to NPU Chips
NPU stands for Neural Network Processing Unit.
2. Using RKNN
1. SDK Download and Content Introduction
You can obtain <span>/home/develop/rk/project/Rockchip_RK356X_RKNN_SDK_V0.7.0_20210402</span>
Here, RKNN_API_for_RK356X mainly contains demos for how to use model files to call the NPU for AI computation on Linux and Android systems.
The rknn-toolkit is a demo for converting models from other neural network training frameworks into rknn architecture models. It is available in both docker and non-docker versions. It is recommended to use the docker version because the non-docker version has strict requirements for Python 3 and pip software versions, making the environment difficult to set up.
2. Using the rknn-toolkit Tool
Here, I will use the docker version as an example.
- First, navigate to the rknn-toolkit2-0.7.0/docker/ folder.
- You will see the rknn-toolkit2-0.7.0-docker.tar.gz image file.
- Use the command
sudo docker load --input rknn-toolkit2-0.7.0-docker.tar.gzto load the image. - After loading successfully, you can confirm with the command
sudo docker images.
Once loaded normally, you can enter the docker environment as follows:
docker run -t -i --privileged -v /home/kylin/:/home/kylin/ rknn-toolkit2:0.7.0 /bin/bash
After executing, the command line prefix will change.
Once in the docker environment, navigate to the <span>rknn-toolkit2-0.7.0/examples/</span> directory, where you will find folders named after common neural network training frameworks.
Here, we will take caffe as an example to convert the caffemodule to rknnmodule.
Enter the caffe/vgg-ssd/ folder, which is a demo for converting the caffemodule. It uses the layer model provided in the deploy_rm_detection_output.prototxt file to convert the caffemodule into rknnmodule via rknn.api. The key functions include the following:
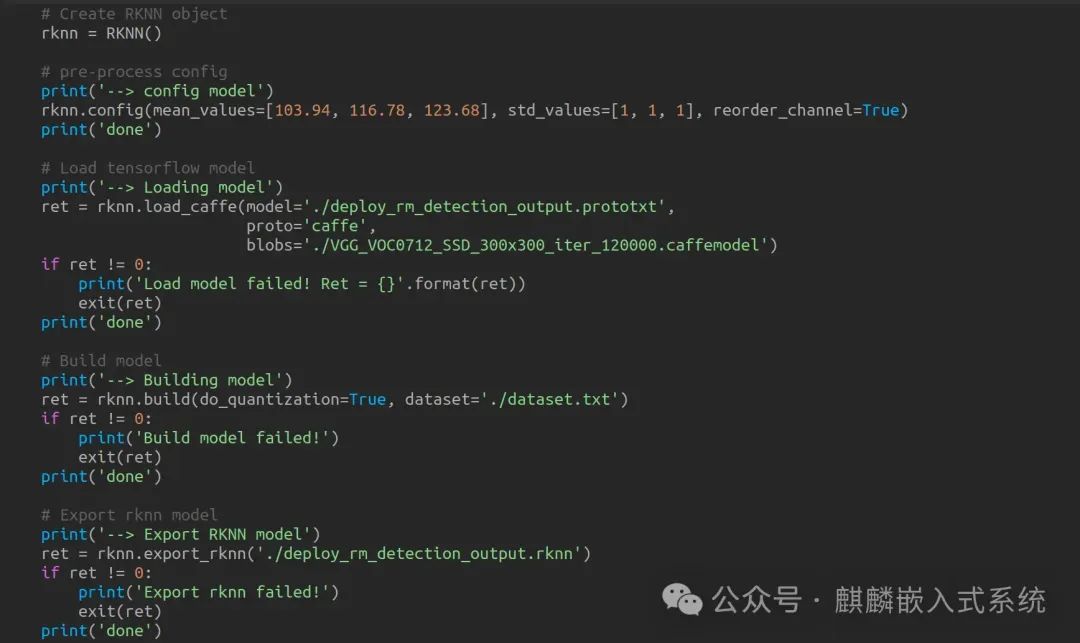
You can see that the process is consistent with the documentation provided by RK, and you can operate according to the steps.Here, a training model of caffemodule is required, which can be downloaded from
https://eyun.baidu.com/s/3jJhPRzo , password is rknn
Then execute <span>python test.py</span> to run the script. After successful execution, you will see a file with the .rknn suffix in the folder, which is the model for the RK platform. This completes the model conversion. During the process, you may need to modify some parameters based on model efficiency/accuracy requirements, which can be adjusted according to the documentation in the SDK.
3. Using the RKNN Model
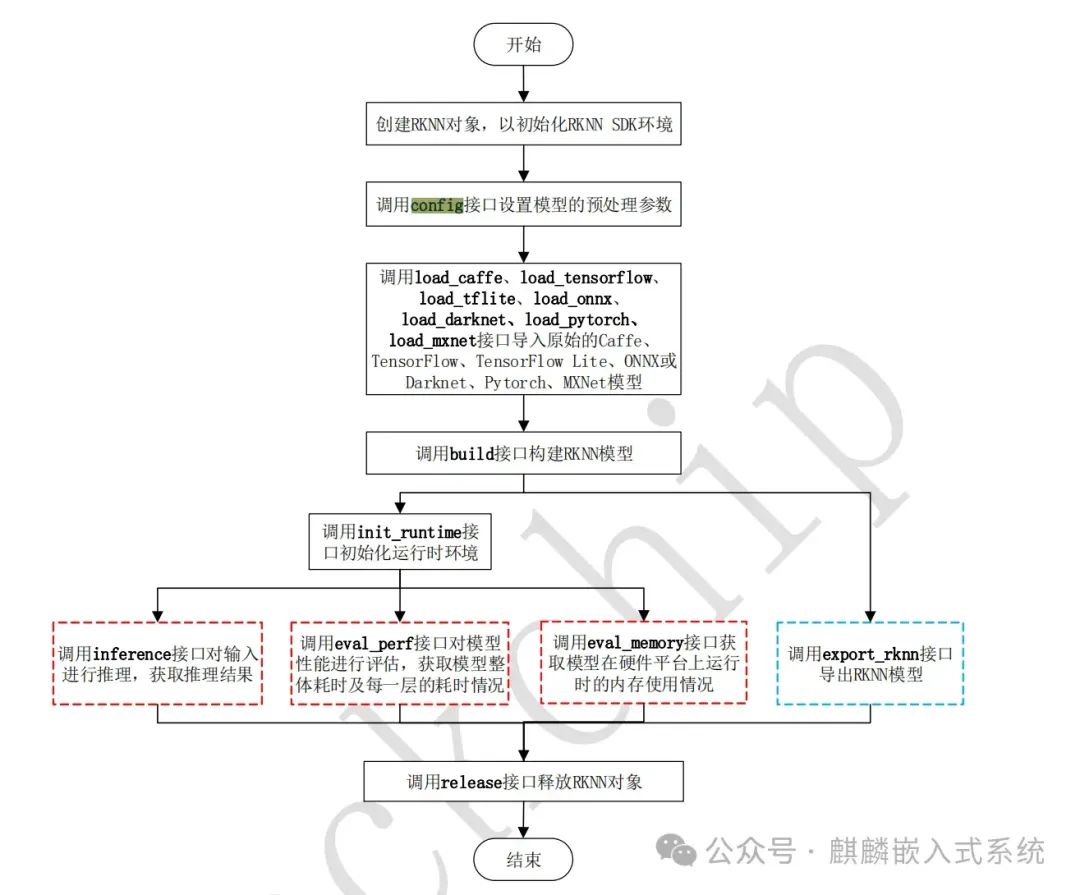
Now that we have obtained the model file with the .rknn suffix, we will explain how to use the model on the RK platform to perform image parsing operations through the NPU. In fact, the above conversion already included an example of image parsing using a Python script. This chapter introduces the process of calling the RKNN interface through C language in the demo.
Navigate to <span>RKNN_API_for_RK356X_v0.7_20210402/examples/rknn_ssd_demo/</span> folder, where we will first look at the source code calling process.
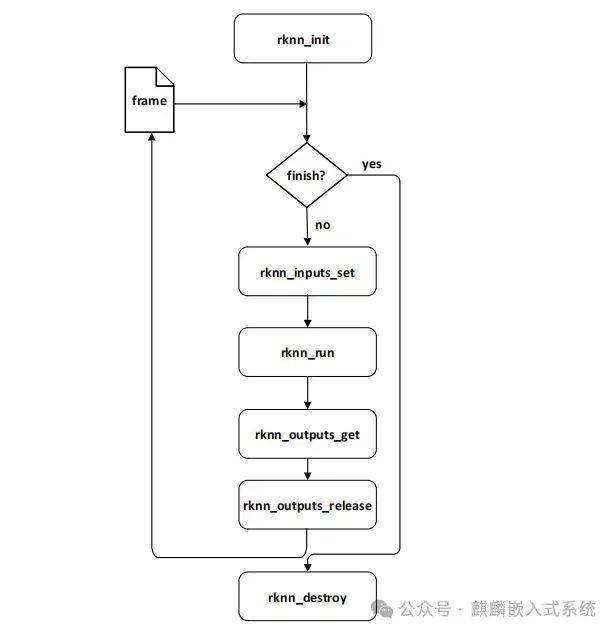
This is consistent with the documentation process, with an additional step postProcessSSD, which converts the values in the results to coordinate points in the image for later drawing boxes.

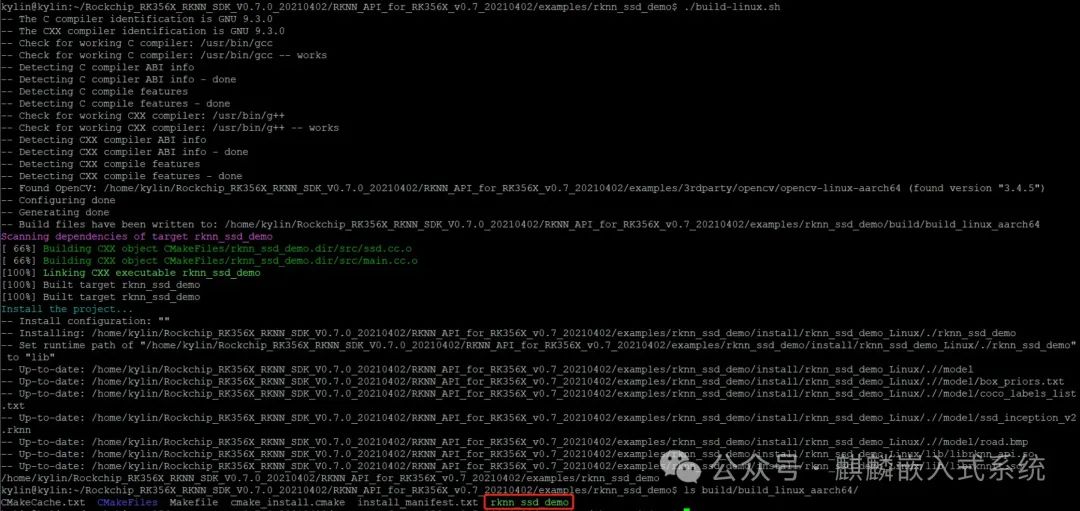
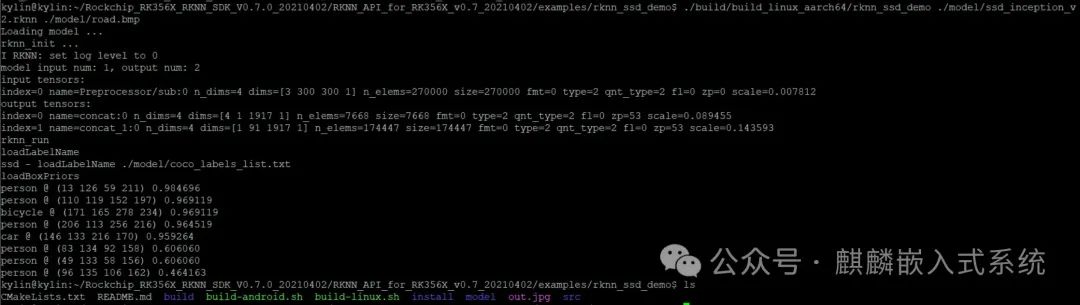
Execute
./build/build_linux_aarch64/rknn_ssd_demo ./model/ssd_inception_v2.rknn ./model/road.bmp
The first parameter is the generated binary file, the second parameter is the .rknn suffixed module model file, and the third parameter is the image to be detected. After execution, an out.jpg image will be generated in the local folder. The output is as follows:


You can see that the model successfully identified the positions of pedestrians and vehicles in the above images.
3. Checking NPU Hardware Information
How can we determine whether the NPU was called to process the above image? We can check through interrupts.

If the NPU is called, the interrupt number will increase. The kernel also provides an interface to adjust the NPU frequency:

Check the modes supported by the NPU, which defaults to simple_ondemand.
echo performance > /sys/devices/platform/fde40000.npu/devfreq/fde40000.npu/governor
Adjust the NPU working mode to performance mode (maintaining maximum frequency).

Check the current working status of the NPU, where @ indicates the usage rate, and the following value is the current frequency.
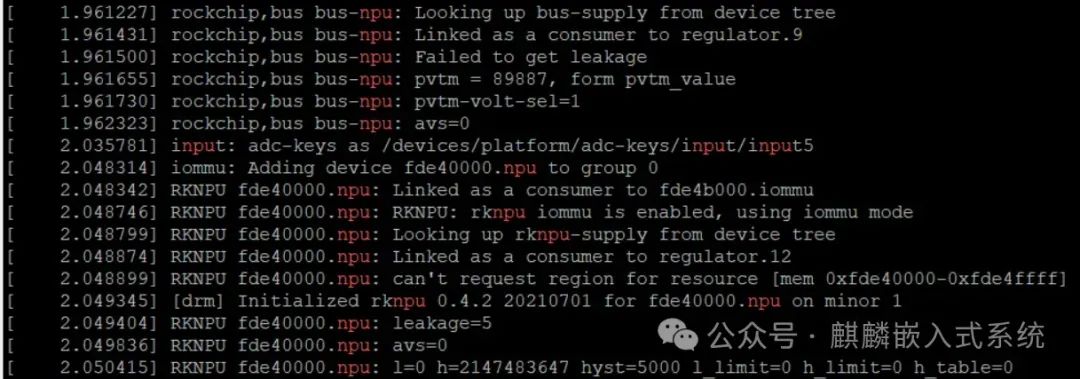
Based on the kernel log, we can determine whether the NPU has been successfully loaded. It can also be seen that the NPU includes the iommu module, which optimizes memory read and write.For more articles, please follow the public account: Kirin Embedded.