Training Strategies for Efficient Embodied Reasoning https://arxiv.org/abs/2505.08243
The ability of robotic policies to generalize is crucial for their application in various scenarios. Currently, the training of robotic policies often relies on a large amount of robotic experience data, which is typically collected through manual remote control, leading to high costs and low efficiency. VLA enhances the generalization capability of robotic policies by combining pre-trained VLM with robotic control data, leveraging the internet pre-training knowledge of VLM to help robots tackle various tasks.
However, traditional data-driven methods still face limitations, especially when high-quality labeled data is required. Additionally, VLA usually requires direct action prediction during task execution, which is limited in effectiveness for complex tasks. To address this issue, Embodied Chain of Thought (ECoT), as an emerging method, proposes to enhance the generalization capability of robots by decomposing the robotic action prediction task into a series of reasoning steps (such as task decomposition, object location identification, semantic reasoning, etc.). CoT reasoning has achieved significant success in large language models (LLMs), indicating that intermediate reasoning steps can help models gradually solve problems.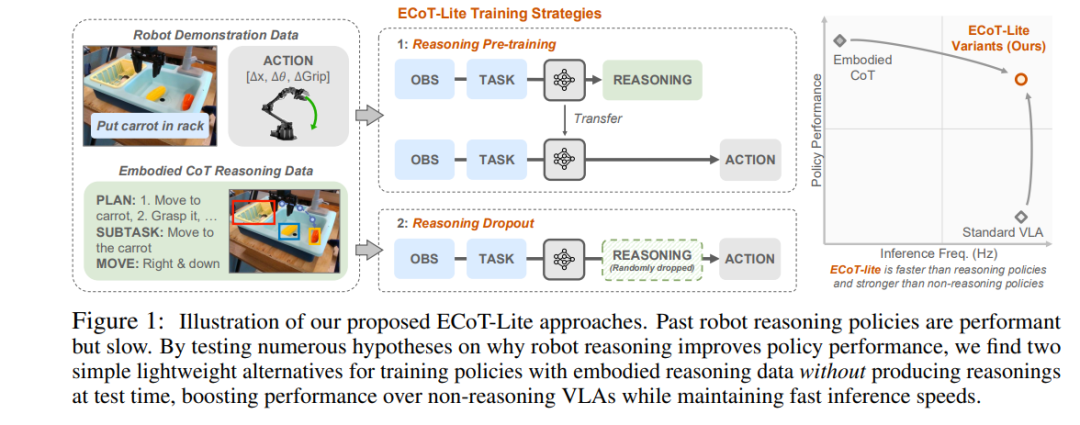
Despite ECoT’s outstanding performance in enhancing the generalization capability of robotic policies, existing reasoning methods face two major challenges: first, the need for a large amount of labeled reasoning data; second, the reasoning steps significantly increase reasoning time, limiting their application in real-time tasks. The current research focus is on how to simplify reasoning strategies while maintaining high performance, reducing data requirements, and accelerating reasoning speed.
VLA and Embodied Chain of Thought (ECoT)
VLA combines robotic control with visual and language inputs, utilizing pre-trained VLM to enhance the robot’s understanding of tasks. This enables robots to perform complex operations based on natural language task instructions. The training of the VLA model adopts an autoregressive method, learning the mapping relationship between task instructions and actions from a large amount of demonstration data through behavior cloning (BC). Although VLA demonstrates strong performance in diverse tasks, its reliance on a single visual and language input for action prediction proves limited when handling complex or long-duration tasks.
To address this issue, Embodied Chain of Thought (ECoT) introduces intermediate reasoning steps, allowing robots to better understand and execute tasks by decomposing tasks into smaller steps. For example, in the task of “placing a carrot on the shelf,” ECoT first identifies the object location, plans the grasping action, and then executes the target action. This task decomposition helps robots maintain a higher success rate and generalization capability when executing complex tasks.
Reasoning Data Generation and Training Methods
The success of ECoT relies on detailed reasoning data, which is generated by annotating robotic action trajectories. Each action trajectory is accompanied by reasoning steps, such as task goal decomposition, object location, and action planning. During training, the ECoT model adopts an autoregressive method to gradually generate reasoning steps and corresponding actions, enabling the robot to not only learn how to perform actions but also understand the structure and execution steps of tasks.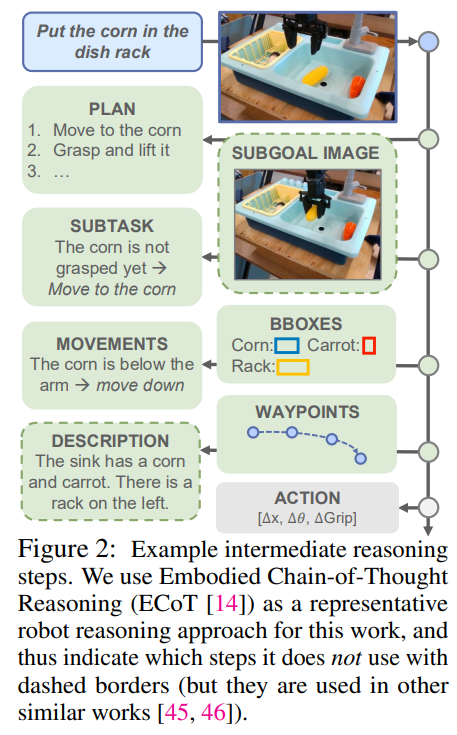
In this way, ECoT can utilize reasoning steps to help robots rely on learned reasoning knowledge to execute tasks when facing unknown tasks, improving decision-making accuracy and efficiency.
Datasets and Task Settings
The training of ECoT uses two core datasets: LIBERO-90 and BridgeData V2, which cover a variety of robotic tasks and operational scenarios. These datasets ensure task diversity and the breadth of training data by randomizing tasks and object locations. Through this setup, the ECoT model can train in various environments and tasks, thereby enhancing its adaptability to different scenarios.
These diverse tasks provide sufficient training material for ECoT, enabling it to better cope with complex tasks and demonstrate stronger generalization capabilities in practical applications.
Reasoning Annotation Creation Method
Reasoning annotations are a key part of ECoT training, generated by annotating robotic task action trajectories. Each annotation not only describes the action but also includes a high-level understanding of the task and reasoning steps. Through existing foundational models (such as VLMs), reasoning annotations help robots understand various stages of tasks and provide critical contextual information during task execution.
These reasoning steps allow the ECoT model to learn how to decompose tasks and execute them effectively during training, thereby improving the robot’s performance in complex environments.
Why Embodied Chain of Thought Improves Performance
The ECoT model significantly enhances the performance of robots in complex tasks by introducing embodied chain of thought reasoning steps. The following hypotheses help us understand why ECoT can improve robotic performance:
Improved Representation Learning
Embodied chain of thought reasoning introduces reasoning steps that provide the model with more contextual information, helping it better understand the structure and details of tasks. These reasoning steps emphasize key parts of task execution, such as object locations and the sequence of actions, thereby assisting robots in better understanding and executing tasks when facing new challenges.
Providing Learning Curricula
Embodied chain of thought reasoning provides robots with implicit learning curricula, decomposing tasks into multiple simple sub-tasks, allowing robots to learn progressively from simple to complex. This gradual learning approach prevents robots from facing the challenges of complex tasks from the outset, helping them master task execution more efficiently.
Enhancing Model Expressiveness
The increase in reasoning steps extends the length of the input sequence, thereby increasing the model’s expressiveness. With each additional reasoning step, the model can utilize more computational resources to make decisions, effectively enhancing task processing capabilities. This increased expressiveness allows the model to handle more contextual information and make more precise decisions when facing more complex tasks.
Advantages of Simplifying Reasoning Strategies
Through reasoning pre-training and reasoning dropout, ECoT not only improves performance but also significantly increases reasoning speed and reduces computational costs. These simplified strategies allow robots to learn reasoning information during training but execute tasks directly during reasoning, avoiding delays in the reasoning process.
ECoT-Lite
ECoT-Lite is a simplified training method designed to address the high computational burden and data dependency of traditional Embodied Chain of Thought (ECoT) models during reasoning. ECoT-Lite employs various optimization strategies to reduce reliance on reasoning steps, improve reasoning efficiency, while maintaining task generalization capability and decision-making performance. Its core idea is to simplify the training process while maximizing the advantages of ECoT, especially finding a balance between reasoning speed and model performance.
Reasoning Pre-training and Joint Training
Reasoning pre-training and joint training form the foundation of ECoT-Lite. Through reasoning pre-training, ECoT-Lite optimizes model representations in the early training phase using reasoning data, enabling it to fully leverage contextual information of tasks. Subsequently, the model learns reasoning and action prediction tasks simultaneously through joint training. Joint training parallelizes reasoning steps with action generation steps, ensuring that reasoning and action decision-making are closely integrated, further enhancing the precision and efficiency of task execution. This dual-task training effectively eliminates delays in the traditional reasoning process while maintaining high reasoning speed.
Reasoning Dropout
Reasoning dropout is a key innovation of ECoT-Lite. Traditional ECoT models require generating reasoning steps each time during reasoning, while ECoT-Lite randomly drops reasoning steps during training, allowing the model to no longer rely on reasoning data every time. This strategy has significant effects in several aspects:
- Reducing Reasoning Latency: Under the reasoning dropout strategy, the model does not need to generate reasoning steps during testing, significantly improving reasoning speed.
- Enhancing Model Robustness: Dropping reasoning steps enables the model to execute tasks even without reasoning, improving its adaptability when facing unknown tasks.
The reasoning dropout strategy allows ECoT-Lite to maintain performance while avoiding excessive reliance on reasoning steps, further reducing computational resource consumption.
Reasoning Scaffolding
The reasoning scaffolding strategy provides ECoT-Lite with a unique training framework. In this strategy, reasoning steps are not generated mandatorily but exist as auxiliary information for learning. During training, reasoning steps provide the model with the high-level structure of tasks, while during reasoning, these steps are no longer needed. The advantages of reasoning scaffolding include:
- Improving Learning Efficiency: Reasoning steps serve as scaffolding to help the model understand tasks more efficiently, especially in complex tasks, where the model can better organize information through the reasoning framework.
- Fast Execution of Reasoning: The scaffolding strategy eliminates the need to generate reasoning steps step-by-step during the reasoning phase, thus avoiding delays caused by generating reasoning steps and improving reasoning execution speed.
Thinking Tokens
ECoT-Lite introduces “thinking tokens” to enhance the model’s expressiveness by extending the input sequence. These thinking tokens do not carry semantic information but serve as placeholders, allowing the model to handle more contextual information during training and reasoning by increasing the length of the input sequence. The advantages of this strategy include:
- Enhancing Computational Capacity: Thinking tokens increase the length of the model’s input sequence, enabling the model to utilize more computational resources, thereby enhancing its task execution capability.
- Improving Context Utilization: By extending the input sequence, the model can acquire more contextual information, increasing its expressiveness in complex tasks.
This strategy effectively enhances the model’s reasoning capability without requiring additional reasoning step data annotations.
Comparison of ECoT-Lite and Traditional ECoT
ECoT-Lite shows significant advantages over traditional ECoT models in several aspects:
- Reasoning Speed: Through reasoning dropout and reasoning scaffolding, ECoT-Lite significantly improves reasoning speed while avoiding high latency issues during the reasoning phase.
- Computational Cost: ECoT-Lite reduces reliance on reasoning steps, thereby lowering the consumption of computational resources. This makes it more feasible for practical applications, especially in resource-constrained environments.
- Performance Maintenance: Despite simplifying the reasoning process, ECoT-Lite can still maintain the advantages of traditional ECoT in task generalization capability and accuracy, demonstrating strong task execution ability.
Experimental Setup and Datasets
The experiments used two key datasets: LIBERO-90 and BridgeData V2. These two datasets contain various robotic tasks aimed at testing the model’s performance in complex and dynamic environments. LIBERO-90 includes various object manipulation tasks, where object locations are randomly set, and robots need to perform operations such as picking and placing. BridgeData V2 focuses on multi-object manipulation and object tracking tasks in dynamic environments, examining the model’s performance in real-time decision-making.
The design of these datasets ensures task diversity and challenge, especially in tasks requiring long reasoning and multi-step decision-making, where the model needs strong generalization and adaptability. The robots in the experiments were equipped with RGB-D cameras, and tasks included object manipulation, navigation, and environmental interaction.
Tasks and Evaluation Metrics
The evaluation of model performance relies on several metrics:
- Task Completion Rate: The proportion of tasks completed by the model within a given time. A task is considered successfully completed when the robot accurately reaches the target position and performs the required actions.
- Action Prediction Accuracy: The degree of match between the actions predicted by the model and the actions annotated in the actual task.
- Generalization Capability: Evaluating the model’s adaptability to unseen tasks, i.e., testing the model’s performance on tasks not involved during the training phase.
- Reasoning Speed: The time consumption during the reasoning process, especially in real-time applications, where reasoning speed is crucial for task execution.
Experimental Results
When comparing ECoT with ECoT-Lite, the focus is on three aspects: performance, efficiency, and generalization capability.
-
Performance Comparison
- ECoT performs better in complex, multi-step tasks, especially in tasks requiring long reasoning and multi-step decision-making, where ECoT effectively decomposes tasks through stepwise reasoning, improving task completion rates and accuracy. Although ECoT-Lite performs comparably in some simple tasks, ECoT’s reasoning steps significantly enhance overall performance in complex tasks.
Efficiency Comparison
- ECoT-Lite significantly outperforms ECoT in reasoning speed. Through reasoning dropout and reasoning scaffolding strategies, ECoT-Lite reduces reliance on reasoning steps, greatly enhancing task execution speed. In contrast, ECoT requires generating complex reasoning steps during the reasoning phase, leading to higher latency.
Generalization Capability Comparison
- ECoT demonstrates stronger generalization capability, especially when facing unknown tasks, relying on its complex reasoning framework to solve a wider range of tasks. ECoT-Lite also possesses strong generalization capability, but in complex tasks, it is slightly inferior to ECoT, especially in tasks requiring longer reasoning.
Reasoning Speed and Task Completion Rate
| Metric | ECoT | ECoT-Lite |
|---|---|---|
| Task Completion Rate | 94.2% | 90.5% |
| Action Prediction Accuracy | 91.7% | 89.3% |
| Generalization Capability | 85.4% | 82.1% |
| Reasoning Speed | 45ms | 25ms |
Appendix: Experimental Details
Appendix A: Task Details and Settings
- All tasks are tested within a fixed time limit. Each model is trained on 80% of the data and tested on the remaining 20%. Task types include simple (e.g., picking and placing), medium complexity (e.g., stacking objects), and high complexity (e.g., involving dynamic interactions among multiple objects).
Appendix B: Model Configuration
- Both models use the same architecture, but ECoT-Lite reduces the number of reasoning steps and simplifies the training process. The reasoning dropout rate and reasoning scaffolding strategy are adjusted based on task complexity.
Appendix C: Reasoning Time Analysis
- Reasoning time is measured in milliseconds per action. During reasoning, ECoT-Lite is 45% faster than ECoT, significantly improving task execution efficiency.
Selecting the Most Suitable Robotic Reasoning Method
When selecting a robotic reasoning method suitable for a specific problem, the complexity of the task, reasoning time, and computational resources must first be considered. ECoT and ECoT-Lite represent two different reasoning strategies, each suitable for different scenarios.
-
ECoT (Embodied Chain of Thought) is suitable for tasks requiring complex reasoning and long-term decision-making, especially in multi-step tasks where ECoT can enhance task execution accuracy and generalization capability through stepwise reasoning. For example, in long-duration object manipulation, navigation, and multi-object interaction tasks, ECoT can enhance the model’s understanding and realization of task objectives through the introduction of reasoning steps.
-
ECoT-Lite is more suitable for scenarios with high real-time requirements, particularly those requiring quick responses and lower task complexity. ECoT-Lite significantly improves reasoning speed by reducing reliance on reasoning steps through reasoning dropout and reasoning scaffolding strategies, making it suitable for environments with limited computational resources or strict reasoning time requirements.
Therefore, the choice of method depends on the following factors:
- Task Complexity: For complex tasks and multi-step reasoning, prioritize ECoT; for simple tasks or those requiring high real-time performance, choose ECoT-Lite.
- Computational Resources: ECoT requires more computational resources to handle reasoning steps, while ECoT-Lite can maintain high efficiency in resource-constrained situations.
- Reasoning Speed Requirements: For applications requiring quick responses, ECoT-Lite is undoubtedly the better choice.
Discussion
The core of selecting a reasoning method lies in balancing performance and efficiency. ECoT provides higher accuracy and generalization capability, but its downside is the high computational burden during reasoning, especially when facing complex multi-step tasks, where reasoning latency may become a bottleneck. ECoT-Lite, on the other hand, optimizes reasoning speed by simplifying the reasoning process and reducing reliance on complex reasoning steps, making it suitable for efficient, quick-response scenarios.
In some practical applications, there may be a conflict between task complexity and real-time requirements. For instance, in complex object manipulation tasks, using ECoT for reasoning may lead to more accurate decisions, but the reasoning time may cause task execution delays. Conversely, while ECoT-Lite sacrifices some reasoning detail and accuracy, it significantly accelerates task execution speed, potentially performing better in tasks with extremely high real-time requirements, such as autonomous driving and real-time object tracking.
Moreover, the training and deployment of models are also important factors in determining the choice of reasoning method. Training ECoT models typically requires higher computational resources and more labeled data, while ECoT-Lite offers more flexibility, especially in situations with scarce data or limited computational resources, providing higher practical value through simplified training and reasoning processes.
Limitations
Despite the significant advantages of ECoT and ECoT-Lite, they also have certain limitations:
-
Limitations of ECoT:
- Long Reasoning Time: ECoT requires a large number of reasoning steps when handling complex tasks, leading to slower reasoning speeds, which may not meet the requirements in real-time tasks. Especially in high-frequency interaction applications, reasoning time may cause task delays.
- High Computational Overhead: ECoT requires higher computational resources to execute reasoning steps, which places higher demands on hardware devices, limiting its application in low-resource environments.
Limitations of ECoT-Lite:
- Weaker Task Generalization Capability: Although ECoT-Lite performs excellently in many simple tasks, its performance may decline in complex, long-reasoning tasks, especially in multi-object interactions and dynamic environment tasks, where ECoT-Lite may not decompose tasks as accurately as ECoT.
- Lack of Reasoning Depth: ECoT-Lite simplifies reasoning steps, which may lead to insufficient performance in tasks requiring deep reasoning. For example, in complex task planning and decision-making processes, ECoT-Lite may struggle to handle the details and complexities of tasks without stepwise reasoning.
Limitations of Training Data and Computational Resources:
- Both ECoT and ECoT-Lite rely on a large amount of labeled data and computational resources to train models. In cases of data scarcity, model performance may be limited, especially when high-quality reasoning annotations are required, making model training more challenging.
- Although ECoT-Lite reduces the complexity of training and reasoning, it still requires a significant amount of data in certain scenarios to ensure efficient task execution. In situations where data cannot be obtained, this may become a bottleneck for using these methods.