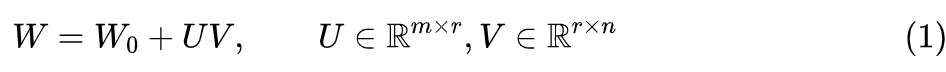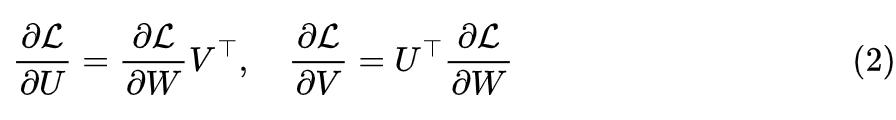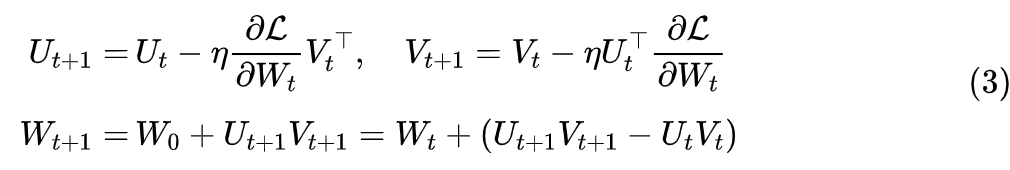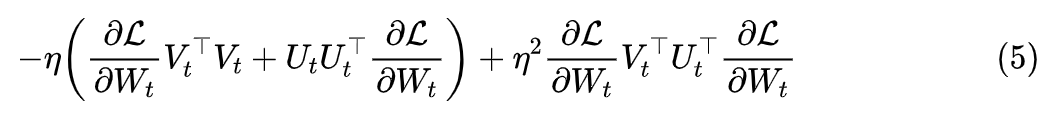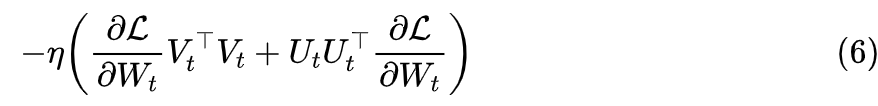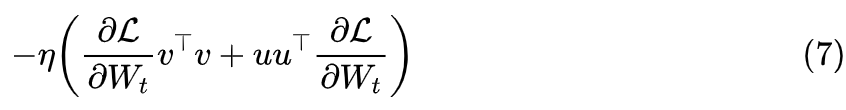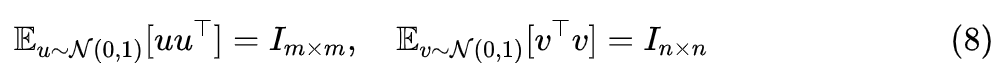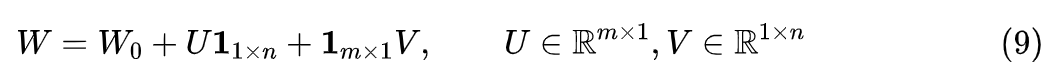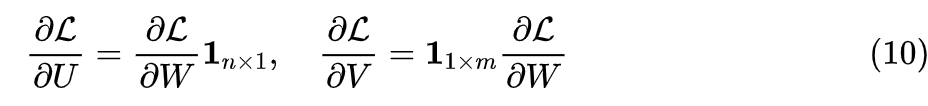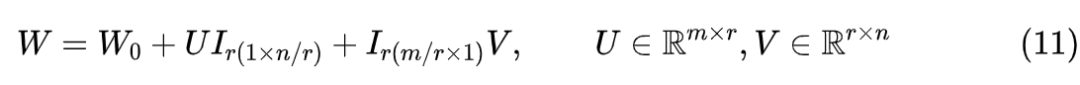With the popularity of ChatGPT and its alternatives, various parameter-efficient fine-tuning methods have also gained traction, among which one of the most popular is the focus of this article, LoRA, originating from the paper “LoRA: Low-Rank Adaptation of Large Language Models” [1]. The LoRA method is relatively straightforward and has many existing implementations, making it easy to understand and use, so there isn’t much to elaborate on.
However, implementing LoRA directly requires modifications to the network structure, which is somewhat cumbersome. Moreover, LoRA feels reminiscent of the previous optimizer AdaFactor [2], leading to the question: Can we analyze and implement LoRA from the perspective of optimizers? This article will discuss this topic.
Method Overview
Previous results (e.g., “Exploring Universal Intrinsic Task Subspace via Prompt Tuning” [3]) indicate that, despite the large number of parameters in pre-trained models, the intrinsic dimension corresponding to each downstream task is not large. In other words, theoretically, we can fine-tune a very small number of parameters to achieve good results on downstream tasks.
LoRA draws on these results and proposes that instead of directly fine-tuning the parameter matrix of the pre-trained model, we assume a low-rank decomposition for the increment:
Among them, one of the matrices is initialized to all zeros and remains fixed, while the optimizer only optimizes the other matrix. Given the conclusion that the intrinsic dimension is small, we can achieve a very small parameter matrix; in many cases, we can even set it to 1. Thus, LoRA is a parameter-efficient fine-tuning method that significantly reduces the number of parameters being optimized.Gradient AnalysisAs mentioned in “Ladder Side-Tuning: The ‘Over-the-Wall Ladder’ for Pre-trained Models”, many parameter-efficient fine-tuning methods only reduce memory requirements without decreasing computational load; LoRA is no exception. To understand this, we only need to observe the gradient:
Here, the loss function is denoted as and we agree that the shapes of the parameters are consistent with the shapes of their gradients. During training, calculating the model gradient is the main computational load; if we perform a full update, the gradient used is , while the gradients used by LoRA are and , which are based on the full update gradient. Therefore, theoretically, the computational load of LoRA is greater than that of a full update.So why does the training speed of LoRA increase in practice? There are several reasons:1. Only part of the parameters is updated: for instance, the original LoRA paper only chose to update the parameters of Self Attention, and in practice, we can also choose to update only certain layers; 2. Reduced communication time: since the number of updated parameters is reduced, especially during multi-GPU training, the amount of data to be transmitted is also reduced, thus decreasing transmission time;
3. Various low-precision acceleration techniques are employed, such as FP16, FP8, or INT8 quantization.
These three factors can indeed speed up training; however, they are not unique to LoRA. In fact, almost all parameter-efficient methods share these characteristics. The advantage of LoRA is its intuitive low-rank decomposition, which achieves results similar to full fine-tuning in many scenarios, and during the prediction phase, it can directly combine and into a single matrix without increasing inference costs.
Optimization Perspective
In fact, the gradient (2) also tells us how to implement LoRA from the perspective of optimizers. The optimizer can directly obtain the full gradient , and we only need to project the gradient according to formula (2) to obtain the gradient and then proceed with the regular optimizer implementation for the update of .If the optimizer is SGD, then it is
If it is an optimizer like Adam with momentum variables, then we only need the projected gradient, thus reducing the number of parameters in the optimizer and saving some memory. As the model size increases, the proportion of memory taken up by these parameters also increases.LoRA stipulates that either or is initialized to all zeros to ensure that the initial state of the model is consistent with the pre-trained one, but this also introduces an asymmetry (one is all zeros, the other is non-zero). In fact, it is also possible to use non-zero initialization for both; we just need to subtract the pre-trained weights from beforehand or equivalently say, parameterize as:
This maintains the initial state consistency while allowing both to use non-zero initialization, enhancing symmetry.
Random Projection
If we expand the update amount in the SGD scenario, the result will be
Assuming that the term can be neglected as a higher-order term, we are left with
From this perspective, compared to the full fine-tuning SGD, LoRA replaces the full gradient with the result in parentheses.For simplicity, we will only focus on the case of , noting that the projection vector at each time depends on , and if we replace them with random vectors that do not depend on , generated anew at each training step, what will happen? We consider , where , so the update amount becomes
It can be proven that
Here, respectively refers to the identity matrix of . Therefore, similar to the “zero-order gradient”, this LoRA, which reinitializes at each step, is actually equivalent to full-rank SGD in an average sense. However, if implemented this way, it may even be slower than full-rank SGD, so its aim is not to speed up but rather to alleviate the catastrophic forgetting problem—by using low-rank matrices (instead of full-rank) to update individual (batch) samples, we reduce the impact on the entire model weights. Of course, this is just a conjecture; the actual effect has yet to be tested by the author.
A Variant
Still focusing on the case of , does LoRA assume that we can make other low-rank decomposition assumptions, such as ? Written in matrix form, it is
Where respectively refers to the full 1 matrix. It is easy to find its gradient as:
It is actually the row sum and column sum of the original gradient. Compared to the original LoRA, this additive decomposition has two advantages: 1) Addition has lower computational cost, and the gradient form is simpler; 2) The rank of UV is always 1, while the rank of may be 2. If rank represents model capacity, it means that with the same number of parameters, the additive expression may have stronger expressive capability. As for the specific effect, I will conduct comparative experiments when I apply LoRA later.So, can additive decomposition be extended to the case of ? Naturally, yes, but with a bit of technique. Here, we assume that can be divisible by , so we only need to change the parameterization to
Where respectively refers to the block matrices of , each block being an identity matrix of . This form means that we treat as block matrices of , and then apply the idea of to operate.Article SummaryThis article introduces the understanding of LoRA from the gradient perspective, including not only the basic introduction but also some conjectures and extensions by the author for readers’ reference.
References
[1] https://arxiv.org/abs/2106.09685
[2] https://kexue.fm/archives/7302
[3] https://arxiv.org/abs/2110.07867
Further Reading
#Submission Channel#
Let Your Writing Reach More People
How can we make more high-quality content reach readers in a shorter path, reducing the cost for readers to find quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly might become a bridge, facilitating the collision of scholars and academic inspirations from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university labs or individuals to share various quality content on our platform, which can be interpretations of the latest papers, analysis of academic hotspots, research insights, or competition experience explanations. Our only goal is to make knowledge flow.
📝 Basic Requirements for Manuscripts:
• The article must be an original work by the individual, not previously published in public channels. If it has been published or is pending publication on other platforms, please indicate it clearly.
• Manuscripts are recommended to be written in markdown format, with images sent as attachments, requiring clear images with no copyright issues.
• PaperWeekly respects the authors’ right to attribution and will provide competitive remuneration for each accepted original manuscript, based on the article’s readership and a tiered quality assessment.