Machine Heart reports
Low-Rank Adaptation (LoRA) is a commonly used fine-tuning technique that allows foundational LLMs to efficiently adapt to specific tasks. Recently, researchers from Singapore’s Sea AI Lab, Washington University in St. Louis, and the Allen Institute for AI proposed a new learning method called LoraHub, which enables LLMs to adapt to various unseen new tasks with a small number of samples. The researchers released the code for LoraHub to facilitate related research.
Large pre-trained language models (LLMs) such as OpenAI GPT, Flan-T5, and LLaMA have significantly advanced the field of natural language processing (NLP). These models perform exceptionally well on many NLP tasks. However, due to the large number of parameters in these models, fine-tuning involves issues related to computational efficiency and memory usage.
Low-Rank Adaptation (LoRA) is an efficient fine-tuning technique that alleviates these issues. It reduces memory requirements and computational costs, thereby enhancing the training speed of LLMs.
The approach of LoRA is to freeze the parameters of the foundational model (i.e., LLM) and then train a lightweight auxiliary module, which typically achieves good performance on the target task.
Although previous studies have explored using LoRA to improve efficiency, few have investigated the inherent modular characteristics and composability of LoRA modules. Generally speaking, previous methods trained LoRA modules that specialize in various tasks and domains. However, the inherent modular characteristics of LoRA modules present an interesting research question: Can LoRA modules be used to efficiently generalize LLMs to unseen tasks?
This paper explores the potential of LoRA’s modular characteristics in broad task generalization, moving beyond single-task training. By carefully constructing LoRA modules, it can achieve certain performance on unknown tasks. Most importantly, this method reportedly enables automatic composition of LoRA modules, eliminating the need for manual design or human expertise. By simply taking a few examples from unseen tasks, this new method can automatically orchestrate compatible LoRA modules without human intervention. The researchers did not preset which LoRA modules trained on specific tasks could be combined; rather, any modules that meet the criteria (e.g., using the same LLM) can be flexibly merged. Because this method uses various available LoRA modules, the researchers named it LoraHub and referred to the new learning method as LoraHub learning.

Paper link: https://arxiv.org/abs/2307.13269
Code link: https://github.com/sail-sg/lorahub
They also experimentally validated the efficiency of the new method, using Flan-T5 as the foundational LLM and the widely recognized BBH benchmark for evaluation. The results indicate that through some few-shot LoraHub learning processes, the combination of LoRA modules can be efficiently applied to unseen tasks. Notably, the scores obtained by the new method are very close to the performance of few-shot context learning.
Additionally, compared to context learning, the new method significantly reduces inference costs, eliminating the LLM’s need for example inputs. This learning process also demonstrates another important advantage: computational efficiency; it employs a gradient-free method to obtain the coefficients of LoRA modules, requiring only a few inference steps for unseen tasks. For example, when evaluated on the BBH benchmark, the new method achieves better performance within a minute using a single A100 GPU.

Figure 1: Zero-shot learning, few-shot context learning, and the newly proposed few-shot LoraHub learning. Note that the composition process is executed based on each task, not based on each example. The inference throughput of the new method is similar to zero-shot learning while its performance on the BIG-Bench Hard (BBH) benchmark is close to that of context learning.
It is important to note that LoraHub learning can also be performed on computers with only CPUs, as it only requires proficient handling of LLM inference. This method, with its versatility and robust performance, is expected to give rise to a platform that allows users to effortlessly share and acquire trained LoRA modules for new tasks. The researchers envision that through such a platform, a library of reusable LoRA modules with countless functionalities could be cultivated. This could also provide a stage for collaborative AI development, allowing the community to enrich LLM capabilities through dynamic LoRA compositions. The potential for sharing and reusing modules is expected to achieve optimal resource utilization across different tasks.
Method
As shown in Figure 2, the researchers first train LoRA modules on various upstream tasks. Specifically, for N different upstream tasks, N LoRA modules are trained separately. Then, for a new task (such as the Boolean expression in Figure 2), the examples of that task are used to guide the LoraHub learning process.
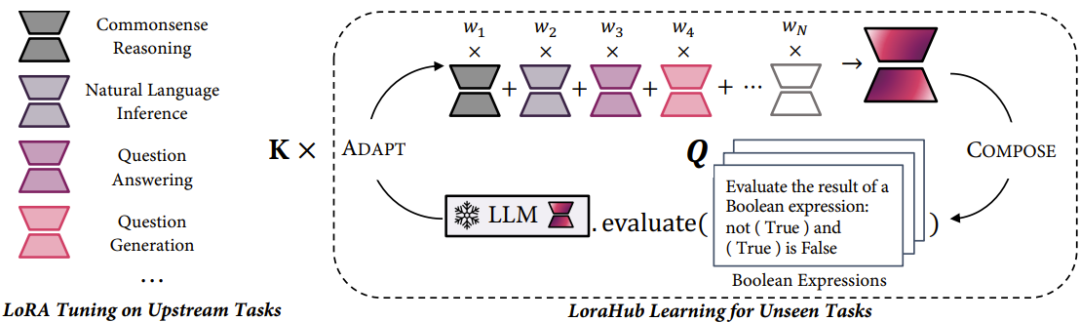
Figure 2: The new method consists of two stages: the composition stage (COMPOSE) and the adaptation stage (ADAPT).
The composition stage integrates existing LoRA modules into a unified module through a set of weight coefficients. The adaptation stage evaluates the merged LoRA module using a small number of examples from unseen tasks. Then, a gradient-free algorithm is used to optimize the aforementioned weights. After several rounds of iteration, a highly adapted LoRA module is produced, which can be integrated into the LLM to perform the target task. For a detailed mathematical description of this method, please refer to the original paper.
Evaluation
The researchers evaluated the newly proposed method, using Flan-T5 as the LLM.
Table 1 presents the experimental data, showing that the efficacy of the new method is close to zero-shot learning while its performance in few-shot scenarios approaches that of context learning. This observation is based on the average results of five different experiments.
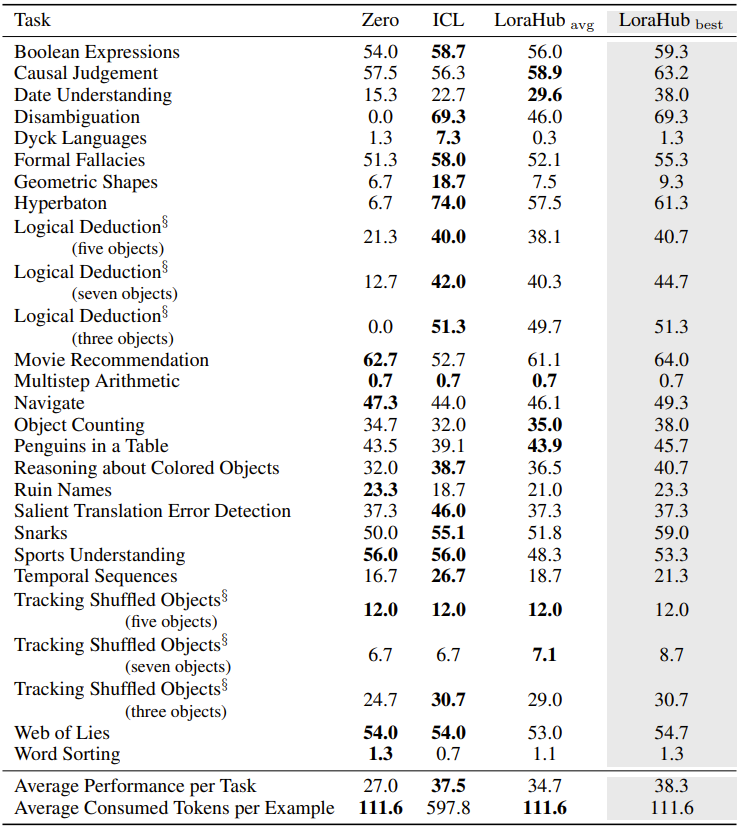
Table 1: Performance comparison of zero-shot learning (Zero), few-shot context learning (ICL), and the newly proposed few-shot LoraHub learning.
It is important to note that in the experiments, the number of tokens used by the model employing the new method is the same as that used by the zero-shot method, and significantly less than that used by context learning. Although performance may occasionally fluctuate, the performance of the new method outperforms zero-shot learning in most instances. The real highlight of the new method is that its optimal performance surpasses that of context learning while using fewer tokens. In the era of LLMs, inference costs are proportional to input length, so LoraHub’s ability to economically utilize input tokens to achieve near-optimal performance will become increasingly important.
As shown in Figure 3, when the number of examples from unseen tasks is less than 20, the performance of the new method generally exceeds that of LoRA fine-tuning.
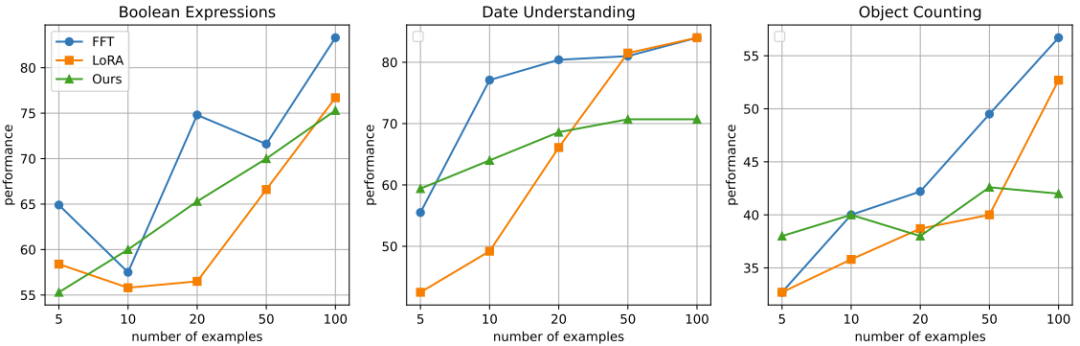
Figure 3: Performance comparison of traditional fine-tuning (FFT), LoRA fine-tuning (LoRA), and the newly proposed LoraHub learning (Ours) under different numbers of task examples.
© THE END
For reprint authorization, please contact this public account.
Submissions or inquiries: [email protected]