The core problem that Docker solves is application packaging.
Containers themselves have no value; the value lies in container orchestration.
Underlying Principles of Docker
The underlying principles of Docker utilize Linux’s Cgroups and Namespace technologies. Cgroups are the primary means of creating constraints, while Namespace technology is the main method for modifying process views (isolation).
Namespace
In Linux, to create a new process:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
When creating, you can pass a parameter CLONE_NEWPID:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
At this point, the newly created process will “see” a completely new process space, where its PID is 1.
The technology that sounds very mysterious, Docker, is actually just specifying a set of Namespace parameters needed for the process when creating a container process. This way, the container can only see the resources, files, devices, networks, etc., limited by the current namespace. The host machine and other unrelated programs cannot see it at all.
In summary, a container is just a special kind of process.
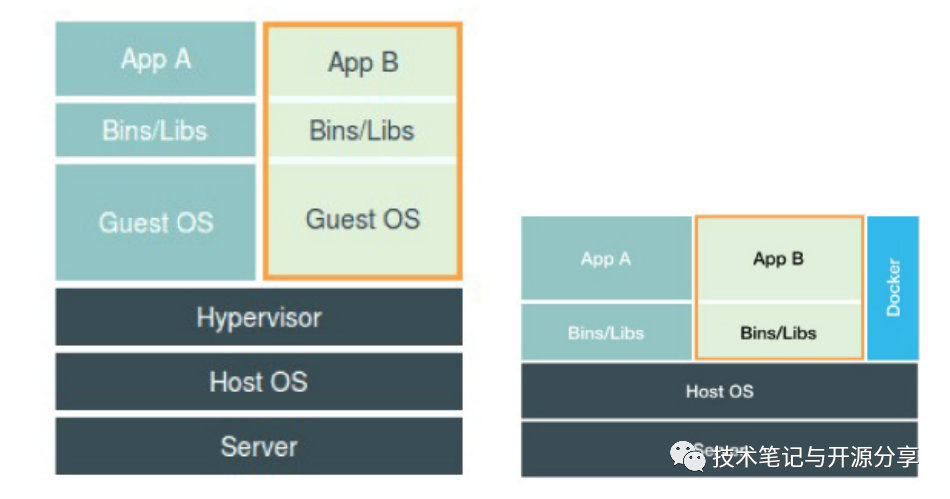
To further understand, a Docker container is not a virtual machine; there is no so-called Docker container running on the host machine. The user process is still the same user process, but Docker helps us add various namespace parameters. The role of the Docker project here is more of a bypassing auxiliary and management task.
We can also see the difference between Docker and virtual machines. Virtualization requires a Hypervisor to create virtual machines, which actually exist and run an operating system inside. A container, in essence, is still just a process on the host operating system.
Namespace Parameters
To isolate different types of resources, the Linux kernel implements the following types of namespaces.
UTS, corresponding macro is CLONE_NEWUTS, indicating that different namespaces can configure different hostnames.
User, corresponding macro is CLONE_NEWUSER, indicating that different namespaces can configure different users and groups.
Mount, corresponding macro is CLONE_NEWNS, indicating that the filesystem mount points of different namespaces are isolated.
PID, corresponding macro is CLONE_NEWPID, indicating that different namespaces have completely independent PIDs, meaning that a process in one namespace and a process in another namespace can have the same PID but represent different processes.
Network, corresponding macro is CLONE_NEWNET, indicating that different namespaces have independent network protocol stacks.
Start a busybox container in the background:
# docker run -it -d busybox
268f11c135bcdf9d5f793a6f12e90e37b5bca07735b9d715c2a02a163d3715c77
# docker exec -it 68f11c135b /bin/sh
# ps
PID USER TIME COMMAND
1 root 0:00 sh
6 root 0:00 /bin/sh
11 root 0:00 ps
Enter the container to check ps, and see that the current main process ID is 1. Isolation.
Use docker inspect to check the actual PID on the host machine. “Pid”: 32694
# docker inspect 68f11c135b
···
"State": {
"Status": "running",
"Running": true,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 32694,
"ExitCode": 0,
"Error": "",
"StartedAt": "2022-01-21T08:48:45.55505132Z",
"FinishedAt": "0001-01-01T00:00:00Z"
},
···
Check on the host machine:
# ps -ef | grep 32694
root 28685 2366 0 16:52 pts/0 00:00:00 grep --color=auto 32694
root 32694 32675 0 16:48 pts/0 00:00:00 sh
Check the namespace resources of process 32694:
# ls -l /proc/32694/ns
总用量 0
lrwxrwxrwx 1 root root 0 1月 21 16:49 ipc -> ipc:[4026534209]
lrwxrwxrwx 1 root root 0 1月 21 16:49 mnt -> mnt:[4026534207]
lrwxrwxrwx 1 root root 0 1月 21 16:48 net -> net:[4026534212]
lrwxrwxrwx 1 root root 0 1月 21 16:49 pid -> pid:[4026534210]
lrwxrwxrwx 1 root root 0 1月 21 16:53 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 1月 21 16:49 uts -> uts:[4026534208]
Cgroup
Cgroup stands for Control Group, which serves to limit the resource usage limits of a group of processes, such as CPU, memory, disk, network bandwidth, etc.
The implementation in Linux is through specific configuration files in a specific directory: /sys/fs/cgroup/
# ls -l /sys/fs/cgroup/
总用量 0
drwxr-xr-x 5 root root 0 7月 7 2021 blkio
lrwxrwxrwx 1 root root 11 7月 7 2021 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 7月 7 2021 cpuacct -> cpu,cpuacct
drwxr-xr-x 5 root root 0 7月 7 2021 cpu,cpuacct
drwxr-xr-x 4 root root 0 7月 7 2021 cpuset
drwxr-xr-x 5 root root 0 7月 7 2021 devices
drwxr-xr-x 4 root root 0 7月 7 2021 freezer
drwxr-xr-x 4 root root 0 7月 7 2021 hugetlb
drwxr-xr-x 5 root root 0 7月 7 2021 memory
lrwxrwxrwx 1 root root 16 7月 7 2021 net_cls -> net_cls,net_prio
drwxr-xr-x 4 root root 0 7月 7 2021 net_cls,net_prio
lrwxrwxrwx 1 root root 16 7月 7 2021 net_prio -> net_cls,net_prio
drwxr-xr-x 4 root root 0 7月 7 2021 perf_event
drwxr-xr-x 5 root root 0 7月 7 2021 pids
drwxr-xr-x 6 root root 0 7月 7 2021 systemd
These folders represent the types of resources that cgroups can limit, such as CPU:
# ls -l /sys/fs/cgroup/cpu/
总用量 0
-rw-r--r-- 1 root root 0 7月 7 2021 cgroup.clone_children
--w--w--w- 1 root root 0 7月 7 2021 cgroup.event_control
-rw-r--r-- 1 root root 0 7月 7 2021 cgroup.procs
-r--r--r-- 1 root root 0 7月 7 2021 cgroup.sane_behavior
-r--r--r-- 1 root root 0 7月 7 2021 cpuacct.stat
-rw-r--r-- 1 root root 0 7月 7 2021 cpuacct.usage
-r--r--r-- 1 root root 0 7月 7 2021 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 7月 7 2021 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 7月 7 2021 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 7月 7 2021 cpu.rt_period_us
-rw-r--r-- 1 root root 0 7月 7 2021 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 7月 7 2021 cpu.shares
-r--r--r-- 1 root root 0 7月 7 2021 cpu.stat
drwxr-xr-x 5 root root 0 1月 21 16:46 docker
drwxr-xr-x 5 root root 0 7月 15 2021 kubepods
-rw-r--r-- 1 root root 0 7月 7 2021 notify_on_release
-rw-r--r-- 1 root root 0 7月 7 2021 release_agent
drwxr-xr-x 218 root root 0 1月 21 16:46 system.slice
-rw-r--r-- 1 root root 0 7月 7 2021 tasks
For example, the parameters cfs_period_us and cfs_quota_us limit the process to be allocated a total of CPU time equal to cfs_quota during a period of length cfs_period.
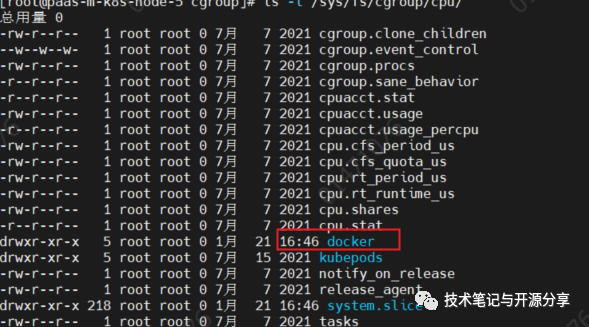
Note the highlighted Docker folder.
# ls -l /sys/fs/cgroup/cpu/docker
总用量 0
drwxr-xr-x 2 root root 0 1月 21 16:41 51868296b5adcf5fa6bd0e85c72fc004ba8abf676159c6a74f06e276b7c229dd
drwxr-xr-x 2 root root 0 1月 21 16:48 68f11c135bcdf9d5f793a6f12e90e37b5bca07735b9d715c2a02a163d3715c77
drwxr-xr-x 2 root root 0 10月 12 13:26 afcc1b255416ebf7b3303904e5aee41afd281073fe00d5eb065dd9f73e31269b
-rw-r--r-- 1 root root 0 7月 19 2021 cgroup.clone_children
--w--w--w- 1 root root 0 7月 19 2021 cgroup.event_control
-rw-r--r-- 1 root root 0 7月 19 2021 cgroup.procs
-r--r--r-- 1 root root 0 7月 19 2021 cpuacct.stat
-rw-r--r-- 1 root root 0 7月 19 2021 cpuacct.usage
-r--r--r-- 1 root root 0 7月 19 2021 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 7月 19 2021 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 7月 19 2021 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 7月 19 2021 cpu.rt_period_us
-rw-r--r-- 1 root root 0 7月 19 2021 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 7月 19 2021 cpu.shares
-r--r--r-- 1 root root 0 7月 19 2021 cpu.stat
Do you remember the busybox container we created? 68f11c135bcdf9d5f793a6f12e90e37b5bca07735b9d715c2a02a163d3715c77
The resource limits for this container are here:
# cat cpu.cfs_quota_us
-1
When we created it, we did not limit resources, so it is explicitly -1, meaning no limits.
Now let’s run an Ubuntu container:
# docker run -it -d --cpu-period=100000 --cpu-quota=20000 busybox
cf367a47f6cd9766effe154e9d725a21657663a3d14f731077ea7e09153cc35a
period=100000 combined with cpu-quota=20000 means that in every 100 ms, the processes limited by this control group can only use 20 ms of CPU time, i.e., limited to 20% of CPU power.
Check period and quota:
# cat cpu.cfs_period_us
200000
# cat cpu.cfs_quota_us
420000
A container is a single-process model. The essence of a container is a process. The user’s application process is actually the process with PID=1 in the container, which is also the parent process of all subsequent created processes.
This means that within a container, you cannot run two different applications simultaneously. This is because the design of the container itself is intended for the container and the application to have the same lifecycle, which is a very important concept for subsequent container orchestration. Otherwise, if a situation arises where “the container is running normally, but the application inside has already crashed,” it becomes very troublesome for the orchestration system to handle.